La semana pasada les pregunté cuánto pagan por APIs de IA. Las respuestas: entre $500-$5,000/mes.
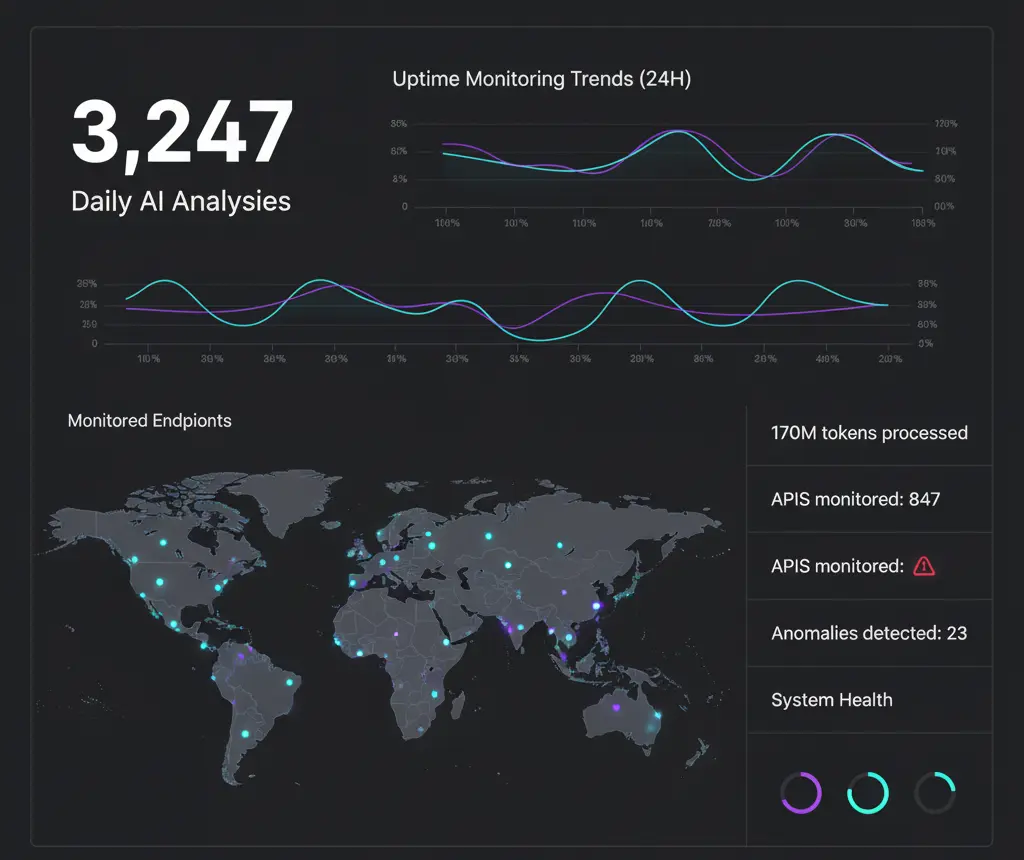
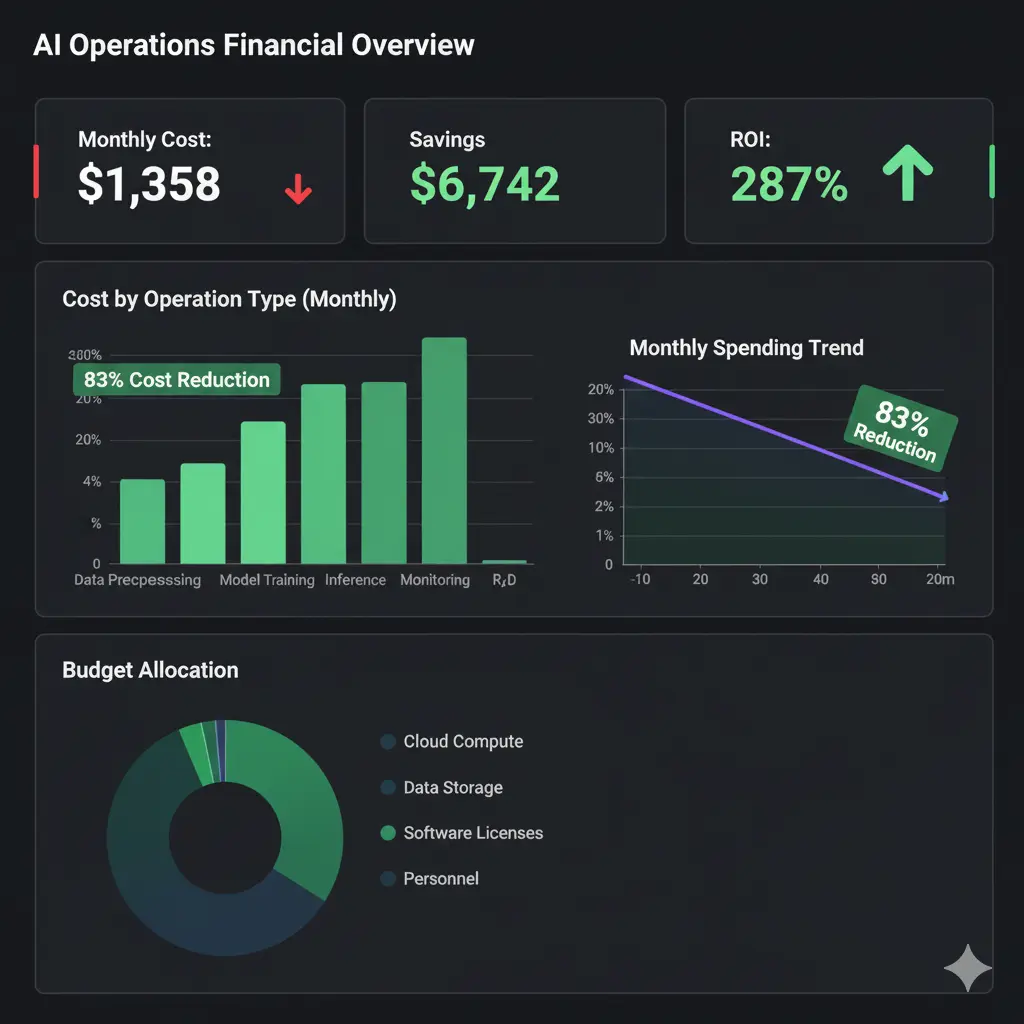
Hoy les comparto cómo en UptimeBolt procesamos 170 millones de tokens y el gasto proyectado no supera los $100/mes. Una reducción de más de un 83% sin cortar ni una función.
Y no, NO fue solo "activar prompt caching" (eso solo da 10-15% de ahorro).
UptimeBolt monitorea 24/7:
- Sitios web y APIs
- Transacciones complejas
- Bases de datos
- Servicios de correo
- Infraestructura completa
Cada día, la IA analiza miles de métricas para:
- Detectar anomalías en tiempo real
- Predecir incidentes antes de que ocurran
- Analizar causas raíz automáticamente
- Optimizar capacidad de forma predictiva
Sin optimización, esto sería económicamente inviable.
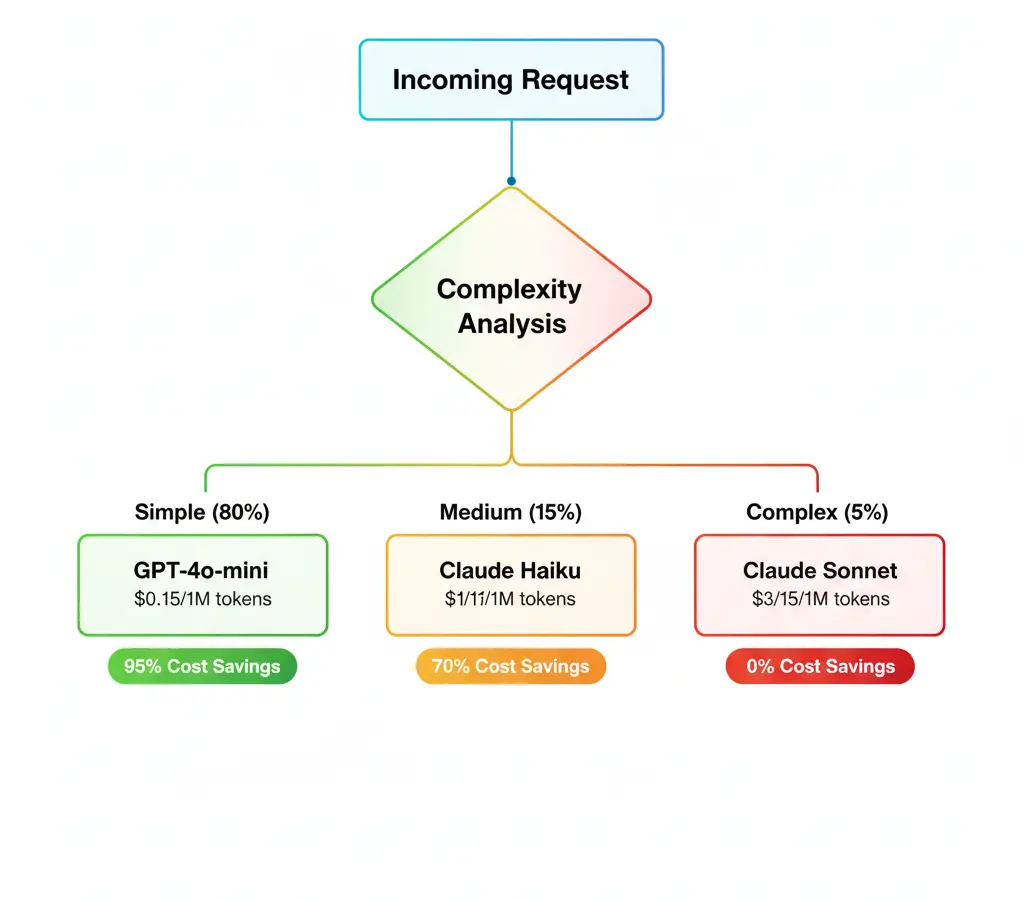
Este es el secreto #1.
No envío todo a GPT-5 o Claude Sonnet 4.5. Creé una matriz que decide el modelo según:
- Complejidad de la tarea
- Latencia aceptable
- Presupuesto disponible
'anomaly-simple': 'gpt-4o-mini',
'anomaly-complex': 'claude-haiku-4.5',
'incident-analysis': 'claude-sonnet-4.5',
'batch-predictions': 'gpt-4o-mini'
Resultado: El 80% de mis tareas usan modelos económicos. Solo el 20% usa los caros.
Ahorro: 60-70%
En lugar de cientos o miles de llamadas individuales al día, agrupo análisis similares:
- Detección de anomalías: hasta 50 monitores en una llamada
- Análisis predictivos: por tipo de servicio y región
- Reportes: procesamiento nocturno en lotes
async processBatchAnomalies(monitors: Monitor[]) {
const batches = this.createOptimalBatches(monitors, {
maxTokensPerBatch: 100000,
maxMonitorsPerBatch: 50
});
return Promise.all(batches.map(batch =>
this.analyzeWithRateLimit(batch)
));
}
Ventajas:
- 50% de descuento en Batch API de OpenAI
- Menos overhead de requests
- Mejor aprovechamiento de prompt caching
Ahorro: 40-50%
Las métricas de monitoring son series temporales. Aquí está el cambio que más impacto tuvo:
❌ ANTES (8,000 tokens promedio):
[
{"timestamp": "2025-10-21T10:00:00Z", "responseTime": 234, "status": "ok"},
{"timestamp": "2025-10-21T10:01:00Z", "responseTime": 245, "status": "ok"},
]
✅ DESPUÉS (1,200 tokens promedio):
{
period: "2025-10-21",
stats: {min: 180, max: 450, avg: 234, p95: 380, p99: 420},
trends: "stable_spike_14:00",
samples: 1440,
anomalies: [{time: "14:00", val: 450, delta: "+87%"}]
}
Reducción: 85% en tokens de entrada
Además:
- Texto plano en vez de JSON verboso
- IDs abreviados:
srv:a1b2c3 vs server-id: a1b2c3d4-e5f6-7890-abcd-ef1234567890
- Símbolos para estados:
✅ ⚠️ 🔴 vs "operational, warning, critical"
Ahorro adicional: 40-60% en tokens de entrada

Cada palabra en un prompt cuesta dinero. Optimicé sin piedad:
❌ ANTES (250 tokens de instrucciones):
"Please analyze the following monitoring data carefully and tell me
if there are any anomalies present. Consider historical patterns,
trends, seasonality effects, and provide detailed explanations
about your findings..."
✅ DESPUÉS (45 tokens):
"Analyze metrics for anomalies.
Return JSON: {hasAnomaly: bool, type: string, confidence: 0-1, reason: string}"
Impacto real:
- Prompts originales: ~8K tokens promedio
- Después de optimización: ~3K tokens
- Reducción: 62%
- Bonus: Respuestas 40% más rápidas
Ahorro: 80% en tokens de sistema
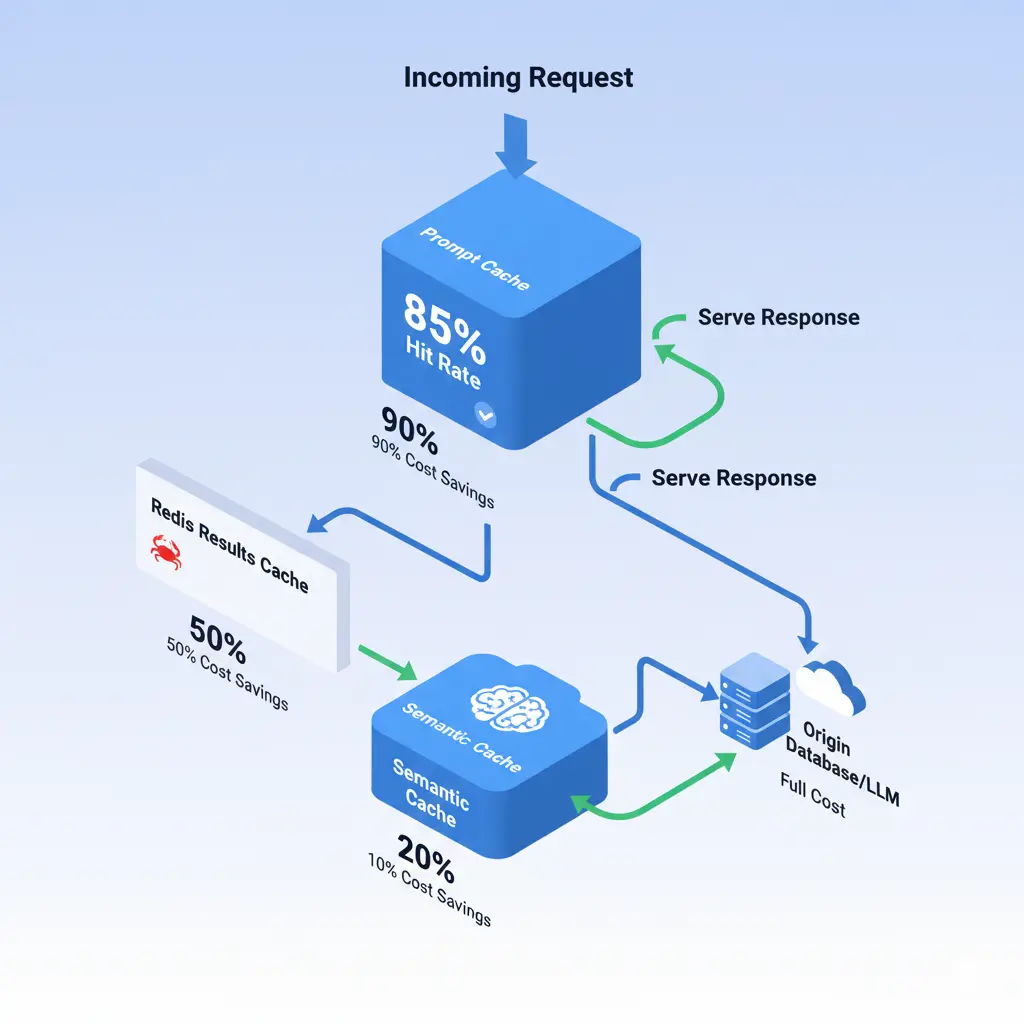
Aquí está la trampa: el prompt caching de Claude expira cada 5 minutos (o 1 hora pagando extra). Mi solución: tres niveles de caché.
Nivel 1: Prompt Caching (Claude/OpenAI)
- Para contextos que se repiten en < 5 min
- Hit rate real: 85%
- Ahorro: 10-15%
Nivel 2: Caché de Resultados (Redis)
- Análisis idénticos en 24h se reutilizan
- Hit rate: 30%
- Ahorro: 100% del costo en esos casos
Nivel 3: Caché Semántico
- Si métricas cambian < 5%, reutilizo análisis
- Hit rate: 20%
- Ahorro: 100% en escenarios estables
async analyzeWithCache(data: MetricData) {
const semanticHash = this.generateSemanticHash(data);
const cached = await redis.get(semanticHash);
if (cached && this.isDataSimilar(data, cached.original, 0.05)) {
return cached.result;
}
return this.callAI(data);
}
Ahorro combinado: 30-45%
No todo requiere IA. Implementé un sistema de tres capas:
Capa 1: Reglas Simples (Costo: $0)
if (responseTime > threshold * 3) {
return {anomaly: true, confidence: 0.95, type: 'spike'};
}
Capa 2: Análisis Ligero (GPT-4o-mini / Haiku 4.5)
- Para casos que pasan la Capa 1
- 20% de alertas llegan aquí
Capa 3: Análisis Profundo (Claude Sonnet)
- Solo para casos complejos que fallan en Capa 2
- 5% de alertas llegan aquí
async detectAnomaly(metrics: Metric[]) {
const simple = this.ruleBasedDetection(metrics);
if (simple.confidence > 0.9) return simple;
const light = await this.lightAIAnalysis(metrics);
if (light.confidence > 0.85) return light;
return this.deepAIAnalysis(metrics);
}
Resultado: 50% de llamadas a IA evitadas completamente.
Ahorro: 50% en volumen de llamadas
No puedes optimizar lo que no mides. Implementé tracking completo:
class AIBudgetManager {
async trackUsage(operation: string, tokens: TokenUsage, cost: number) {
await db.aiUsage.create({
operation,
model: tokens.model,
inputTokens: tokens.input,
outputTokens: tokens.output,
cachedTokens: tokens.cached,
totalCost: cost,
timestamp: new Date()
});
await this.checkBudgetThreshold();
}
async getROI(operationType: string) {
const cost = await this.getOperationCost(operationType);
const value = await this.getBusinessValue(operationType);
return {cost, value, roi: (value - cost) / cost};
}
}
Esto me permite:
- Identificar operaciones más costosas
- Medir ROI de cada tipo de análisis
- Alertas antes de exceder presupuesto
- Optimización continua basada en datos
Descubrimientos clave:
- El 10% de operaciones consumían 70% del presupuesto
- Algunas operaciones "baratas" generaban más valor que las caras
- Eliminé 3 tipos de análisis con ROI negativo
Breakdown del ahorro:
- Model selection matrix: 60%
- Batch processing: 40%
- Token optimization: 60%
- Prompt engineering: 80%
- Caché multinivel: 35%
- Lazy analysis: 50%
- Combinado: +83% de reducción total
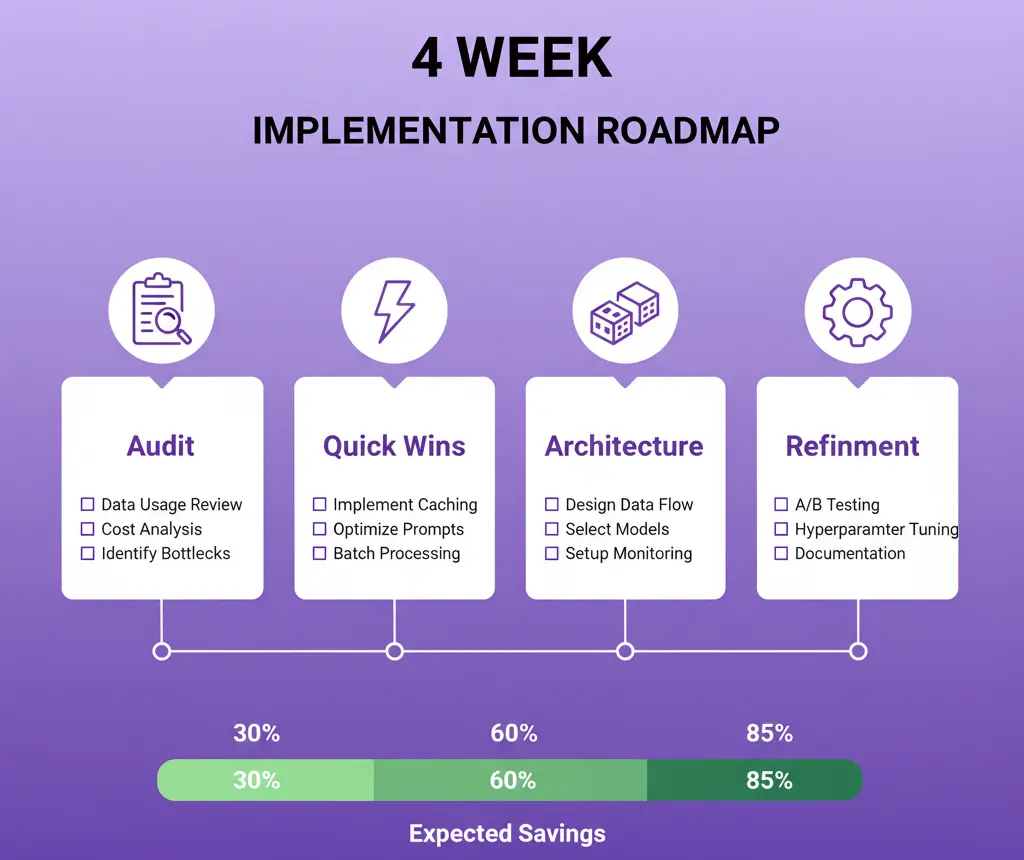
Semana 1: Auditoría 📋
Semana 2: Quick Wins ⚡
Semana 3: Arquitectura 🏗️
Semana 4: Refinamiento 🔧
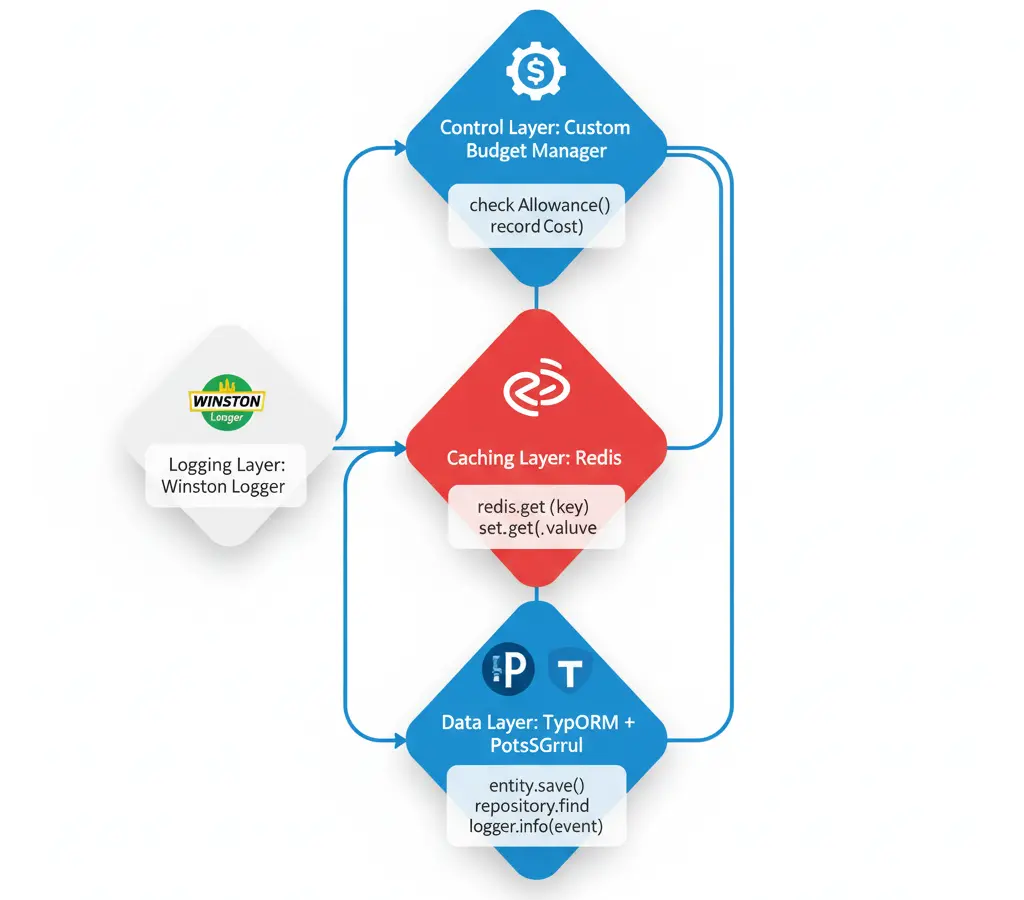
Mi implementación usa:
- TypeORM + PostgreSQL: Tracking histórico de uso
- Redis: Caché multinivel y rate limiting
- Winston Logger: Logs estructurados de todas las llamadas
- Custom Budget Manager: Sistema propio de presupuestos
Código starter del Budget Manager:
import Anthropic from '@anthropic-ai/sdk';
import OpenAI from 'openai';
class SimpleBudgetTracker {
private costs = {
'gpt-4o-mini': {input: 0.15, output: 0.60},
'claude-haiku-4.5': {input: 1.00, output: 5.00},
'claude-sonnet-4.5': {input: 3.00, output: 15.00}
};
async trackCall(model: string, input: number, output: number) {
const cost = (input/1000000 * this.costs[model].input) +
(output/1000000 * this.costs[model].output);
await db.insert({model, input, output, cost, date: new Date()});
console.log(`💰 ${model}: $${cost.toFixed(4)}`);
}
}
- Prompt caching no es magia: Solo 10-15% de ahorro
- Cache de 1hr solo vale con alto volumen: Calcular mal el ROI es común
- Cambios en prompts = caché inválido: Versiona tus prompts
- No todo se beneficia del batch: Requests urgentes van directo
- Medir mal el hit rate destruye tu ROI: Implementa tracking desde día 1
- La optimización es iterativa: No logras 83% en un día
- Arquitectura > Prompt: Un buen sistema supera a un buen prompt
- 80/20 funciona aquí: El 20% de operaciones consume 80% del presupuesto
- El modelo más caro ≠ el mejor para todos los casos: GPT-4o-mini o Haiku 4.5 resuelve 90% de mis casos
- ROI > Costo absoluto: Algunas operaciones caras generan mucho más valor

Si pagas más de $500/mes en APIs de IA, probablemente estás dejando $400+ en la mesa cada mes.
Empieza hoy:
- Mide tu uso actual (script arriba)
- Implementa model selection (empieza con 2 modelos)
- Optimiza tus 3 prompts más caros (texto plano + compresión)
Ese 70-85% de ahorro está ahí, esperándote.
¿Qué estrategia implementarás primero? Comenta y te ayudo a priorizar.
¿Quieres el código completo del Budget Manager? Déjame saber en comentarios.
Sígueme para más optimizaciones sin BS de un founder de SaaS en las trincheras.
La semana pasada les pregunté cuánto pagan por APIs de IA. Las respuestas: entre $500-$5,000/mes.
Hoy les comparto cómo en UptimeBolt procesamos 170 millones de tokens y el gasto proyectado no supera los $100/mes. Una reducción de más de un 83% sin cortar ni una función.
Y no, NO fue solo "activar prompt caching" (eso solo da 10-15% de ahorro).
📊 El Contexto Real
UptimeBolt monitorea 24/7:
Cada día, la IA analiza miles de métricas para:
Sin optimización, esto sería económicamente inviable.
Los 7 Trucos Que SÍ Funcionan
1. 🎯 Arquitectura Inteligente: Model Selection Matrix
Este es el secreto #1.
No envío todo a GPT-5 o Claude Sonnet 4.5. Creé una matriz que decide el modelo según:
Resultado: El 80% de mis tareas usan modelos económicos. Solo el 20% usa los caros.
Ahorro: 60-70%
2. 📦 Batch Processing (Donde Está el Oro)
En lugar de cientos o miles de llamadas individuales al día, agrupo análisis similares:
Ventajas:
Ahorro: 40-50%
3. 🗜️ Token Optimization: Compresión de Datos
Las métricas de monitoring son series temporales. Aquí está el cambio que más impacto tuvo:
❌ ANTES (8,000 tokens promedio):
✅ DESPUÉS (1,200 tokens promedio):
Reducción: 85% en tokens de entrada
Además:
srv:a1b2c3vsserver-id: a1b2c3d4-e5f6-7890-abcd-ef1234567890✅ ⚠️ 🔴vs"operational, warning, critical"Ahorro adicional: 40-60% en tokens de entrada
4. 🎣 Prompt Engineering Quirúrgico
Cada palabra en un prompt cuesta dinero. Optimicé sin piedad:
❌ ANTES (250 tokens de instrucciones):
✅ DESPUÉS (45 tokens):
Impacto real:
Ahorro: 80% en tokens de sistema
5. 🔄 Caché Multinivel (No Solo Prompt Caching)
Aquí está la trampa: el prompt caching de Claude expira cada 5 minutos (o 1 hora pagando extra). Mi solución: tres niveles de caché.
Nivel 1: Prompt Caching (Claude/OpenAI)
Nivel 2: Caché de Resultados (Redis)
Nivel 3: Caché Semántico
Ahorro combinado: 30-45%
6. 🤖 Lazy Analysis: Solo Cuando es Necesario
No todo requiere IA. Implementé un sistema de tres capas:
Capa 1: Reglas Simples (Costo: $0)
Capa 2: Análisis Ligero (GPT-4o-mini / Haiku 4.5)
Capa 3: Análisis Profundo (Claude Sonnet)
Resultado: 50% de llamadas a IA evitadas completamente.
Ahorro: 50% en volumen de llamadas
7. 📊 Budget Management y ROI Tracking
No puedes optimizar lo que no mides. Implementé tracking completo:
Esto me permite:
Descubrimientos clave:
📈 Los Números Reales (Sin Marketing)
Breakdown del ahorro:
🚀 Implementación: Tu Plan de 4 Semanas
Semana 1: Auditoría 📋
Semana 2: Quick Wins ⚡
Semana 3: Arquitectura 🏗️
Semana 4: Refinamiento 🔧
🛠️ Stack Tecnológico
Mi implementación usa:
Código starter del Budget Manager:
⚠️ Las Trampas Que Debes Evitar
💡 Lecciones Aprendidas
✅ Tu Acción Inmediata
Si pagas más de $500/mes en APIs de IA, probablemente estás dejando $400+ en la mesa cada mes.
Empieza hoy:
Ese 70-85% de ahorro está ahí, esperándote.
¿Qué estrategia implementarás primero? Comenta y te ayudo a priorizar.
¿Quieres el código completo del Budget Manager? Déjame saber en comentarios.
Sígueme para más optimizaciones sin BS de un founder de SaaS en las trincheras.