En la economía digital de 2025, la disponibilidad de tu sitio web no es solo una métrica técnica—es la base de tu negocio. Cada segundo de inactividad se traduce directamente en pérdida de ingresos, reputación dañada y clientes frustrados que no esperarán a que vuelvas a estar en línea.
El uptime se refiere a la cantidad de tiempo que un sistema, servicio o sitio web permanece operativo y accesible para los usuarios. Típicamente se expresa como un porcentaje durante un período determinado, generalmente calculado mensual o anualmente.
Cuando decimos que un sitio web tiene 99.9% de uptime, estamos diciendo que estuvo disponible y funcionando correctamente durante el 99.9% del período medido. Ese 0.1% restante representa el downtime—períodos en los que los usuarios no pudieron acceder al servicio.
El concepto parece simple, pero las implicaciones son profundas. En un mundo siempre conectado, los usuarios esperan que los servicios estén disponibles 24/7/365. Cualquier desviación de esta expectativa crea fricción, frustración y, en última instancia, pérdida de clientes.
 La industria usa "nueves" para describir niveles de uptime. Cada nueve adicional representa una reducción dramática en el downtime permitido.
La industria usa "nueves" para describir niveles de uptime. Cada nueve adicional representa una reducción dramática en el downtime permitido.
Dos Nueves (99%)
Permite aproximadamente 87.6 horas de downtime por año, o cerca de 7.3 horas por mes. Este nivel generalmente se considera inaceptable para cualquier servicio crítico de negocio.
Tres Nueves (99.9%)
Permite aproximadamente 8.76 horas de downtime anualmente, o cerca de 43.8 minutos mensuales. Este es el nivel mínimo aceptable para la mayoría de servicios comerciales.
Cuatro Nueves (99.99%)
Reduce el downtime permitido a solo 52.56 minutos por año, o aproximadamente 4.38 minutos por mes. Este nivel requiere infraestructura y monitoreo sofisticados.
Cinco Nueves (99.999%)
El estándar de oro, permitiendo solo 5.26 minutos de downtime por año. Lograr esto requiere redundancia en cada nivel y típicamente se ve solo en infraestructura crítica.
Para ponerlo en perspectiva: la diferencia entre 99% y 99.9% de uptime es la diferencia entre estar caído tres días y medio versus ocho horas anualmente.

Según estudios recientes, el costo promedio del downtime de TI ha aumentado a más de $5,600 por minuto para organizaciones empresariales. Para sitios de comercio electrónico durante períodos pico de compras, esta cifra puede ser significativamente mayor.
Pero no se trata solo de pérdida directa de ingresos. El downtime crea efectos en cascada que amplifican el daño mucho más allá del impacto financiero inmediato.
Los usuarios modernos tienen cero tolerancia a la indisponibilidad. Los estudios muestran que el 88% de los consumidores en línea son menos propensos a regresar a un sitio después de una mala experiencia, y el 79% de los clientes insatisfechos compartirán su experiencia negativa con otros.
En 2025, tus competidores están a solo un clic de distancia. Cuando tu sitio está caído, los usuarios no esperan—se van. Y a menudo no regresan.
Google y otros motores de búsqueda consideran la confiabilidad del sitio en sus algoritmos de ranking. El downtime frecuente o prolongado señala una mala experiencia de usuario, lo que puede impactar negativamente tu visibilidad en búsquedas.
Esto crea un efecto compuesto: el downtime no solo te hace perder visitantes actuales sino que también reduce tu capacidad de atraer nuevos a través de búsqueda orgánica.
El cambio al trabajo remoto e híbrido ha convertido a las aplicaciones SaaS y servicios en la nube en infraestructura esencial. Cuando estos servicios caen, organizaciones enteras dejan de funcionar.
Una caída de una herramienta de colaboración no solo inconveniencia a los usuarios—detiene proyectos, retrasa fechas límite e interrumpe flujos de trabajo en múltiples equipos y zonas horarias.
Muchas industrias ahora tienen regulaciones que requieren niveles específicos de uptime para servicios orientados al cliente. Servicios financieros, salud y contratistas gubernamentales a menudo enfrentan requisitos estrictos de disponibilidad con penalidades significativas por incumplimiento.
Más allá de las regulaciones, la mayoría de contratos B2B incluyen Acuerdos de Nivel de Servicio (SLAs) con garantías de uptime. No cumplir estos objetivos puede activar reembolsos, penalidades o terminación de contrato.
El costo más obvio, pero a menudo subestimado. Un sitio de comercio electrónico que genera $100,000 diarios pierde más de $4,100 por cada hora de downtime. Durante períodos pico como Black Friday, esta cifra puede multiplicarse varias veces.
Cuando los sistemas internos caen, los empleados no pueden trabajar. Si 100 empleados que ganan un promedio de $50/hora pierden acceso a sistemas críticos, eso son $5,000 por hora en productividad perdida—antes de contar el impacto en fechas límite y entregables.
Poner los sistemas de nuevo en línea no es gratis. Soporte de TI de emergencia, pago de horas extra, soporte acelerado de proveedores y potencial reemplazo de hardware se suman a la cuenta. Cuanto más larga la caída, más altos estos costos.
Quizás el costo más significativo a largo plazo. Los clientes recuerdan el downtime, especialmente si los afectó durante un momento crítico. Reconstruir la confianza toma tiempo y recursos, y algunos clientes nunca regresan.
Las redes sociales amplifican este efecto. Una sola caída significativa puede generar cobertura negativa que persiste en resultados de búsqueda por meses o años.
Mientras tu sitio está caído, los competidores capturan a tus posibles clientes. Algunos de esos clientes descubrirán que prefieren la alternativa y nunca regresarán, incluso después de que estés de nuevo en línea.
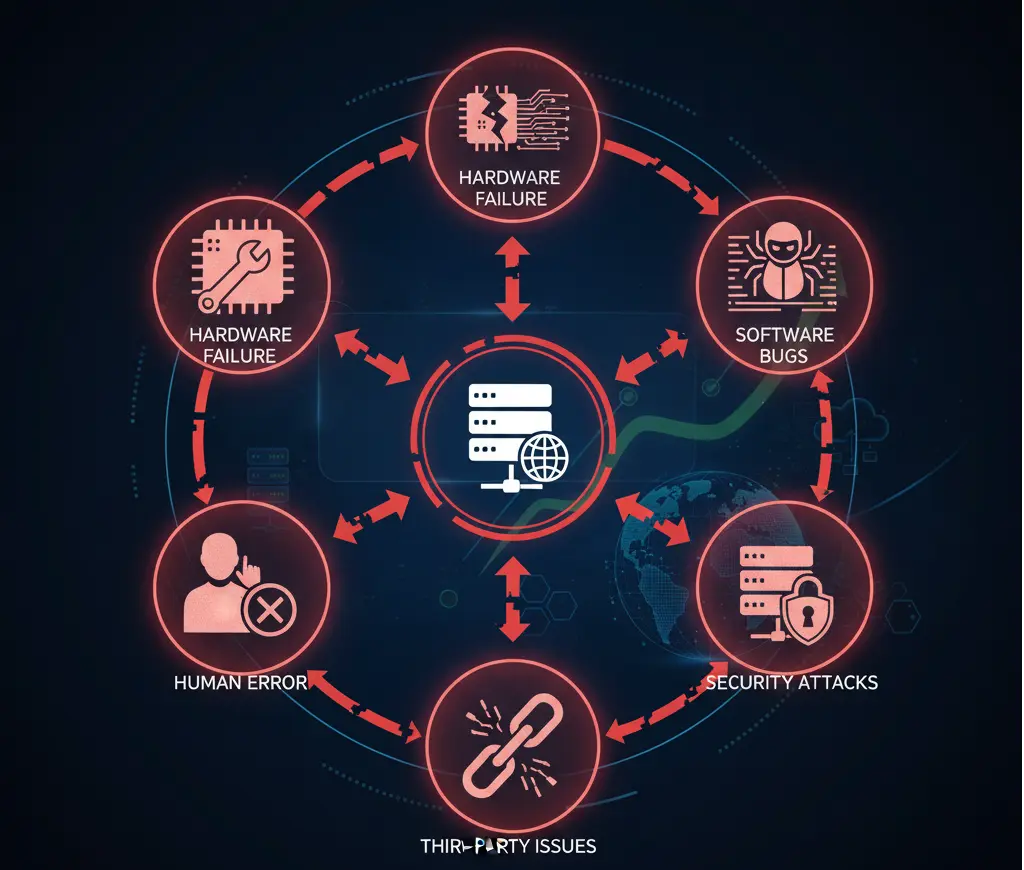 Entender las causas ayuda a prevenirlas. La mayoría del downtime cae en varias categorías.
Entender las causas ayuda a prevenirlas. La mayoría del downtime cae en varias categorías.
Los componentes físicos fallan. Servidores, dispositivos de almacenamiento, equipos de red y sistemas de energía tienen vidas útiles finitas. Sin redundancia, una sola falla de hardware puede derribar servicios completos.
Problemas de código, fugas de memoria y excepciones no manejadas pueden bloquear aplicaciones o hacerlas no responsivas. Estos problemas a menudo emergen solo bajo condiciones específicas o niveles de carga.
Configuraciones incorrectas, eliminaciones accidentales y errores de despliegue siguen siendo causas principales de caídas. Incluso equipos experimentados cometen errores, especialmente bajo presión.
Ataques DDoS, ransomware y otras brechas de seguridad pueden hacer que los servicios no estén disponibles. Estos incidentes a menudo se programan deliberadamente para maximizar el daño.
Las aplicaciones modernas dependen de numerosos servicios externos: procesadores de pago, APIs, CDNs, proveedores de DNS y plataformas en la nube. Cuando cualquiera de estos falla, tu servicio puede fallar con ellos.
Los picos de tráfico pueden abrumar sistemas que no están diseñados para escalar. Contenido viral, campañas de marketing o picos estacionales pueden generar carga que excede la capacidad.
Medir el uptime parece sencillo pero requiere consideración cuidadosa de la metodología.
¿Con qué frecuencia verificas? Verificar cada 5 minutos significa que podrías no detectar una caída hasta por 5 minutos. Verificar cada minuto proporciona detección más rápida pero genera más datos.
Un sitio podría estar disponible en una región pero inalcanzable en otra debido a problemas de red, problemas de CDN o fallas de infraestructura regional. La medición precisa requiere verificar desde múltiples ubicaciones.
¿Está el sitio "arriba" si devuelve un código de estado 200 pero tarda 30 segundos en cargar? ¿Qué pasa si devuelve una página de error? Definir uptime requiere especificar qué constituye rendimiento aceptable.
El mantenimiento planificado típicamente no cuenta contra las métricas de uptime, pero esto requiere comunicación clara y seguimiento preciso de los períodos de mantenimiento.
No puedes mejorar lo que no mides. Despliega monitoreo que verifique tus sistemas críticos frecuentemente desde múltiples ubicaciones geográficas.
El monitoreo moderno debe incluir no solo verificaciones de disponibilidad sino también métricas de rendimiento, seguimiento de expiración de certificados SSL y verificación de DNS.
Elimina los puntos únicos de falla. Usa múltiples servidores, múltiples centros de datos, múltiples proveedores de DNS y múltiples rutas de red. Diseña sistemas para que cualquier componente individual pueda fallar sin derribar el servicio.
No esperes a que humanos respondan a alertas a las 3 AM. Implementa failover automático, auto-escalado y sistemas auto-reparables que puedan responder a problemas más rápido que cualquier humano.
Las pruebas regulares de recuperación ante desastres aseguran que tus sistemas de failover realmente funcionen cuando se necesiten. Muchas organizaciones descubren que sus sistemas de respaldo no funcionan correctamente solo cuando más los necesitan.
Documenta los procedimientos de respuesta a incidentes. Cuando ocurre el downtime, cada segundo cuenta. Los procesos claros reducen la confusión y aceleran la recuperación.
Entender el uptime es el primer paso. El segundo paso es medirlo.
Si actualmente no estás monitoreando la disponibilidad de tu sitio web, estás volando a ciegas. Los problemas pueden persistir por horas antes de que alguien lo note—usualmente cuando un cliente se queja.
UptimeBolt hace que empezar sea simple. Crea tu primer monitor en 30 segundos y comienza a recibir alertas cuando ocurran problemas. Con predicciones potenciadas por IA, a menudo sabrás sobre problemas antes de que afecten a tus usuarios.
El uptime no es solo una métrica técnica—es un imperativo de negocio. En 2025, donde la presencia digital equivale a la presencia de negocio, la disponibilidad impacta directamente los ingresos, la reputación y el crecimiento.
Las organizaciones que prosperarán serán aquellas que traten el uptime como una prioridad estratégica, no como una ocurrencia tardía. Invertirán en monitoreo, redundancia y capacidades de respuesta rápida.
No esperes a que el downtime te enseñe su importancia. Comienza a monitorear hoy, establece tu línea base y comienza el viaje hacia mayor disponibilidad.
Tus clientes esperan que estés ahí cuando te necesiten. Asegúrate de estarlo.
En la economía digital de 2025, la disponibilidad de tu sitio web no es solo una métrica técnica—es la base de tu negocio. Cada segundo de inactividad se traduce directamente en pérdida de ingresos, reputación dañada y clientes frustrados que no esperarán a que vuelvas a estar en línea.
¿Qué es Exactamente el Uptime?
El uptime se refiere a la cantidad de tiempo que un sistema, servicio o sitio web permanece operativo y accesible para los usuarios. Típicamente se expresa como un porcentaje durante un período determinado, generalmente calculado mensual o anualmente.
Cuando decimos que un sitio web tiene 99.9% de uptime, estamos diciendo que estuvo disponible y funcionando correctamente durante el 99.9% del período medido. Ese 0.1% restante representa el downtime—períodos en los que los usuarios no pudieron acceder al servicio.
El concepto parece simple, pero las implicaciones son profundas. En un mundo siempre conectado, los usuarios esperan que los servicios estén disponibles 24/7/365. Cualquier desviación de esta expectativa crea fricción, frustración y, en última instancia, pérdida de clientes.
Entendiendo los Nueves: Porcentajes de Uptime Explicados
Dos Nueves (99%) Permite aproximadamente 87.6 horas de downtime por año, o cerca de 7.3 horas por mes. Este nivel generalmente se considera inaceptable para cualquier servicio crítico de negocio.
Tres Nueves (99.9%) Permite aproximadamente 8.76 horas de downtime anualmente, o cerca de 43.8 minutos mensuales. Este es el nivel mínimo aceptable para la mayoría de servicios comerciales.
Cuatro Nueves (99.99%) Reduce el downtime permitido a solo 52.56 minutos por año, o aproximadamente 4.38 minutos por mes. Este nivel requiere infraestructura y monitoreo sofisticados.
Cinco Nueves (99.999%) El estándar de oro, permitiendo solo 5.26 minutos de downtime por año. Lograr esto requiere redundancia en cada nivel y típicamente se ve solo en infraestructura crítica.
Para ponerlo en perspectiva: la diferencia entre 99% y 99.9% de uptime es la diferencia entre estar caído tres días y medio versus ocho horas anualmente.
Por Qué el Uptime Importa Más en 2025
El Costo del Downtime se ha Disparado
Según estudios recientes, el costo promedio del downtime de TI ha aumentado a más de $5,600 por minuto para organizaciones empresariales. Para sitios de comercio electrónico durante períodos pico de compras, esta cifra puede ser significativamente mayor.
Pero no se trata solo de pérdida directa de ingresos. El downtime crea efectos en cascada que amplifican el daño mucho más allá del impacto financiero inmediato.
Las Expectativas de los Usuarios Nunca Han Sido Mayores
Los usuarios modernos tienen cero tolerancia a la indisponibilidad. Los estudios muestran que el 88% de los consumidores en línea son menos propensos a regresar a un sitio después de una mala experiencia, y el 79% de los clientes insatisfechos compartirán su experiencia negativa con otros.
En 2025, tus competidores están a solo un clic de distancia. Cuando tu sitio está caído, los usuarios no esperan—se van. Y a menudo no regresan.
Los Motores de Búsqueda Penalizan el Downtime
Google y otros motores de búsqueda consideran la confiabilidad del sitio en sus algoritmos de ranking. El downtime frecuente o prolongado señala una mala experiencia de usuario, lo que puede impactar negativamente tu visibilidad en búsquedas.
Esto crea un efecto compuesto: el downtime no solo te hace perder visitantes actuales sino que también reduce tu capacidad de atraer nuevos a través de búsqueda orgánica.
El Trabajo Remoto Depende de Servicios Siempre Disponibles
El cambio al trabajo remoto e híbrido ha convertido a las aplicaciones SaaS y servicios en la nube en infraestructura esencial. Cuando estos servicios caen, organizaciones enteras dejan de funcionar.
Una caída de una herramienta de colaboración no solo inconveniencia a los usuarios—detiene proyectos, retrasa fechas límite e interrumpe flujos de trabajo en múltiples equipos y zonas horarias.
Obligaciones Regulatorias y Contractuales
Muchas industrias ahora tienen regulaciones que requieren niveles específicos de uptime para servicios orientados al cliente. Servicios financieros, salud y contratistas gubernamentales a menudo enfrentan requisitos estrictos de disponibilidad con penalidades significativas por incumplimiento.
Más allá de las regulaciones, la mayoría de contratos B2B incluyen Acuerdos de Nivel de Servicio (SLAs) con garantías de uptime. No cumplir estos objetivos puede activar reembolsos, penalidades o terminación de contrato.
Los Costos Ocultos del Downtime
Pérdida de Ingresos
El costo más obvio, pero a menudo subestimado. Un sitio de comercio electrónico que genera $100,000 diarios pierde más de $4,100 por cada hora de downtime. Durante períodos pico como Black Friday, esta cifra puede multiplicarse varias veces.
Pérdida de Productividad
Cuando los sistemas internos caen, los empleados no pueden trabajar. Si 100 empleados que ganan un promedio de $50/hora pierden acceso a sistemas críticos, eso son $5,000 por hora en productividad perdida—antes de contar el impacto en fechas límite y entregables.
Costos de Recuperación
Poner los sistemas de nuevo en línea no es gratis. Soporte de TI de emergencia, pago de horas extra, soporte acelerado de proveedores y potencial reemplazo de hardware se suman a la cuenta. Cuanto más larga la caída, más altos estos costos.
Daño a la Reputación
Quizás el costo más significativo a largo plazo. Los clientes recuerdan el downtime, especialmente si los afectó durante un momento crítico. Reconstruir la confianza toma tiempo y recursos, y algunos clientes nunca regresan.
Las redes sociales amplifican este efecto. Una sola caída significativa puede generar cobertura negativa que persiste en resultados de búsqueda por meses o años.
Costo de Oportunidad
Mientras tu sitio está caído, los competidores capturan a tus posibles clientes. Algunos de esos clientes descubrirán que prefieren la alternativa y nunca regresarán, incluso después de que estés de nuevo en línea.
¿Qué Causa el Downtime?
Fallas de Hardware
Los componentes físicos fallan. Servidores, dispositivos de almacenamiento, equipos de red y sistemas de energía tienen vidas útiles finitas. Sin redundancia, una sola falla de hardware puede derribar servicios completos.
Bugs de Software
Problemas de código, fugas de memoria y excepciones no manejadas pueden bloquear aplicaciones o hacerlas no responsivas. Estos problemas a menudo emergen solo bajo condiciones específicas o niveles de carga.
Error Humano
Configuraciones incorrectas, eliminaciones accidentales y errores de despliegue siguen siendo causas principales de caídas. Incluso equipos experimentados cometen errores, especialmente bajo presión.
Incidentes de Seguridad
Ataques DDoS, ransomware y otras brechas de seguridad pueden hacer que los servicios no estén disponibles. Estos incidentes a menudo se programan deliberadamente para maximizar el daño.
Dependencias de Terceros
Las aplicaciones modernas dependen de numerosos servicios externos: procesadores de pago, APIs, CDNs, proveedores de DNS y plataformas en la nube. Cuando cualquiera de estos falla, tu servicio puede fallar con ellos.
Problemas de Capacidad
Los picos de tráfico pueden abrumar sistemas que no están diseñados para escalar. Contenido viral, campañas de marketing o picos estacionales pueden generar carga que excede la capacidad.
Cómo se Mide el Uptime
Medir el uptime parece sencillo pero requiere consideración cuidadosa de la metodología.
Frecuencia de Monitoreo
¿Con qué frecuencia verificas? Verificar cada 5 minutos significa que podrías no detectar una caída hasta por 5 minutos. Verificar cada minuto proporciona detección más rápida pero genera más datos.
Distribución Geográfica
Un sitio podría estar disponible en una región pero inalcanzable en otra debido a problemas de red, problemas de CDN o fallas de infraestructura regional. La medición precisa requiere verificar desde múltiples ubicaciones.
Definición de "Arriba"
¿Está el sitio "arriba" si devuelve un código de estado 200 pero tarda 30 segundos en cargar? ¿Qué pasa si devuelve una página de error? Definir uptime requiere especificar qué constituye rendimiento aceptable.
Ventanas de Mantenimiento
El mantenimiento planificado típicamente no cuenta contra las métricas de uptime, pero esto requiere comunicación clara y seguimiento preciso de los períodos de mantenimiento.
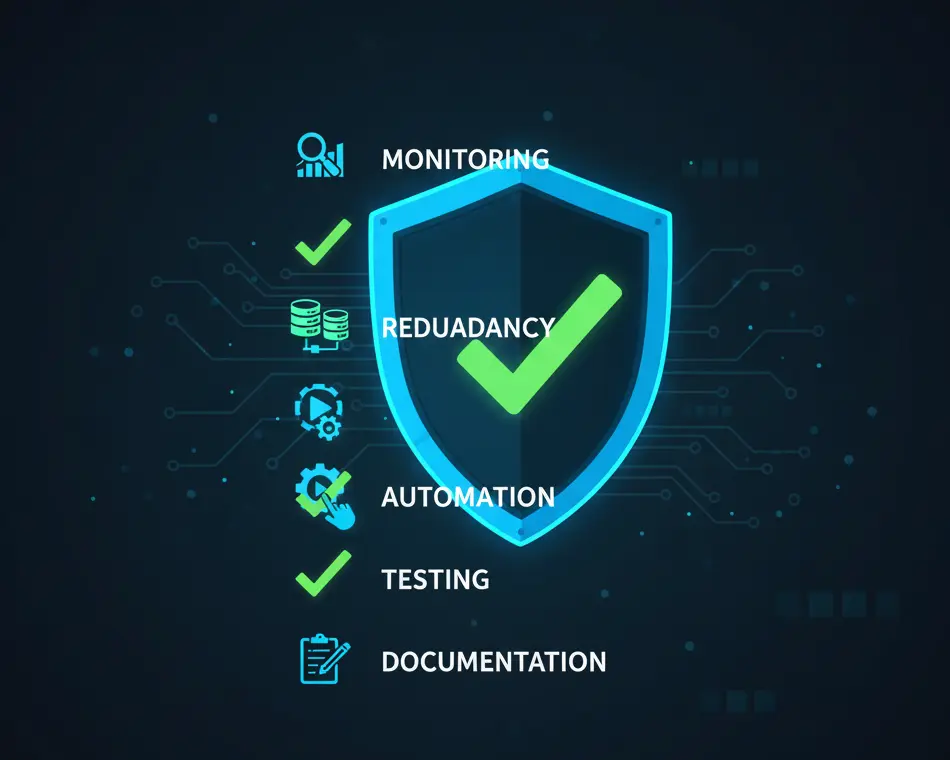
Mejores Prácticas para Maximizar el Uptime
Implementa Monitoreo Integral
No puedes mejorar lo que no mides. Despliega monitoreo que verifique tus sistemas críticos frecuentemente desde múltiples ubicaciones geográficas.
El monitoreo moderno debe incluir no solo verificaciones de disponibilidad sino también métricas de rendimiento, seguimiento de expiración de certificados SSL y verificación de DNS.
Construye Redundancia
Elimina los puntos únicos de falla. Usa múltiples servidores, múltiples centros de datos, múltiples proveedores de DNS y múltiples rutas de red. Diseña sistemas para que cualquier componente individual pueda fallar sin derribar el servicio.
Automatiza Respuestas
No esperes a que humanos respondan a alertas a las 3 AM. Implementa failover automático, auto-escalado y sistemas auto-reparables que puedan responder a problemas más rápido que cualquier humano.
Prueba tu Recuperación
Las pruebas regulares de recuperación ante desastres aseguran que tus sistemas de failover realmente funcionen cuando se necesiten. Muchas organizaciones descubren que sus sistemas de respaldo no funcionan correctamente solo cuando más los necesitan.
Establece Procesos Claros
Documenta los procedimientos de respuesta a incidentes. Cuando ocurre el downtime, cada segundo cuenta. Los procesos claros reducen la confusión y aceleran la recuperación.
Tomando Acción: Tu Primer Paso
Entender el uptime es el primer paso. El segundo paso es medirlo.
Si actualmente no estás monitoreando la disponibilidad de tu sitio web, estás volando a ciegas. Los problemas pueden persistir por horas antes de que alguien lo note—usualmente cuando un cliente se queja.
UptimeBolt hace que empezar sea simple. Crea tu primer monitor en 30 segundos y comienza a recibir alertas cuando ocurran problemas. Con predicciones potenciadas por IA, a menudo sabrás sobre problemas antes de que afecten a tus usuarios.
Conclusión
El uptime no es solo una métrica técnica—es un imperativo de negocio. En 2025, donde la presencia digital equivale a la presencia de negocio, la disponibilidad impacta directamente los ingresos, la reputación y el crecimiento.
Las organizaciones que prosperarán serán aquellas que traten el uptime como una prioridad estratégica, no como una ocurrencia tardía. Invertirán en monitoreo, redundancia y capacidades de respuesta rápida.
No esperes a que el downtime te enseñe su importancia. Comienza a monitorear hoy, establece tu línea base y comienza el viaje hacia mayor disponibilidad.
Tus clientes esperan que estés ahí cuando te necesiten. Asegúrate de estarlo.