Cuando una empresa se prepara para Black Friday, Hot Sale, Buen Fin, un lanzamiento masivo o una campaña de marketing de alto alcance, suele pensar primero en capacidad: más instancias, más ancho de banda, más escalado automático, más CDN. Todo eso importa, pero no alcanza. En la práctica, muchos incidentes de alto tráfico no ocurren porque “faltó infraestructura” en términos absolutos, sino porque hubo un punto débil que nadie vio a tiempo. Aquí es donde la predicción de incidentes —cada vez más impulsada por inteligencia artificial— empieza a marcar la diferencia.
Ese es el gran error de enfoque. En eventos de alto tráfico web, no basta con soportar carga. Hay que anticipar fallas antes de que aparezcan. Una degradación de pocos minutos en el checkout, una API de pagos que empieza a responder con mayor latencia o una base de datos que se acerca lentamente a saturación puede traducirse en pérdidas directas de ingresos, tickets de soporte, abandono de usuarios y daño reputacional.
En este tipo de escenarios, la diferencia entre un equipo reactivo y uno realmente preparado no está en quién reacciona más rápido cuando todo se rompe. Está en quién detecta antes las señales que anuncian el problema. Ese es el terreno de la predicción de incidentes.
La conversación moderna sobre alto tráfico web ya no gira solo alrededor de “cuánto tráfico aguanta mi plataforma”, sino sobre una pregunta más estratégica:
¿puedo detectar saturaciones, degradaciones y cuellos de botella antes de que el usuario final los sufra?
Ahí es donde se conectan prácticas clásicas como capacity planning, pruebas de carga y tuning de infraestructura con enfoques más avanzados como monitoreo end-to-end, detección de anomalías y predicción de incidentes basada en inteligencia artificial.
Los eventos de alto tráfico son momentos de máxima exposición para cualquier plataforma digital. No solo porque hay más usuarios concurrentes, sino porque casi todos los componentes críticos trabajan cerca de sus límites al mismo tiempo: frontend, balanceadores, APIs, bases de datos, cachés, colas, servicios externos y pasarelas de pago.
Lo más delicado es que, en estos periodos, cualquier degradación tiene un costo multiplicado. Una latencia adicional de 2 o 3 segundos puede parecer tolerable en una hora normal, pero durante un evento comercial esa misma latencia puede reducir significativamente la tasa de conversión en flujos críticos como el checkout, además de disparar el abandono de carrito. En escenarios móviles, este impacto puede ser aún más agresivo: incrementos de apenas segundos en el tiempo de carga pueden duplicar la tasa de rebote.
A esto se suma la presión operativa:
- Más tickets de soporte
- Más fricción en atención al cliente
- Experiencia degradada en el momento de mayor intención de compra
Minutos de caída en una ventana de máximo tráfico no se distribuyen de forma uniforme durante el día: pegan justo cuando más dinero y confianza están en juego. El impacto no es lineal, es exponencial.
Por eso, prepararse para alto tráfico web no significa solo “tener más capacidad”. Significa entender que estos eventos son también pruebas de resiliencia operativa. Una arquitectura robusta en papel puede fallar si los equipos no tienen visibilidad real sobre lo que está pasando en cada capa del sistema.
Uno de los malentendidos más comunes es creer que un sistema bien provisionado está automáticamente protegido. En realidad, muchos incidentes en eventos de alto tráfico ocurren en plataformas que sí tenían margen de infraestructura, pero fallaron por otros motivos.
Una arquitectura puede escalar horizontalmente en frontend y API gateway, pero seguir dependiendo de una base de datos, una caché, una cola o una dependencia externa que no escala igual. El sistema en conjunto parece robusto, pero su punto más débil define el límite real.
Muchas plataformas modernas dependen de terceros para pagos, autenticación, scoring, logística, fraude o mensajería. Puedes tener tu infraestructura perfectamente preparada y aun así sufrir un colapso parcial porque una dependencia externa empieza a responder lento, devuelve errores intermitentes o agota sus propios recursos.
Antes de que ocurra una caída visible, suele haber una fase previa donde:
- La latencia crece
- Los timeouts aumentan
- Los retries se multiplican
- Los tiempos de respuesta se vuelven erráticos
El problema es que, si solo se mira disponibilidad binaria, esa fase pasa desapercibida.
En una arquitectura con microservicios, un flujo crítico como login o checkout atraviesa múltiples componentes. Cada uno puede “estar arriba” y aun así el flujo completo fallar. El monitoreo tradicional por servicio no alcanza para capturar esa realidad.
El enfoque reactivo asume que el sistema avisará claramente cuando algo salga mal. En la práctica, lo que suele ocurrir es que las alertas llegan cuando el impacto ya es visible.
Imagina un caso realista:
- El checkout responde en 800 ms p95
- Sube a 1.2 s
- Luego a 1.8 s
- Finalmente a 2.7 s
No hay caída total. No hay errores masivos. Pero la conversión ya empezó a caer.
Este aumento progresivo es, de hecho, una violación de nuestro SLO de latencia (ej. p95 < 1s), mucho antes de que se registre un error HTTP 5xx.
El problema del monitoreo reactivo es claro: llega tarde para el negocio.
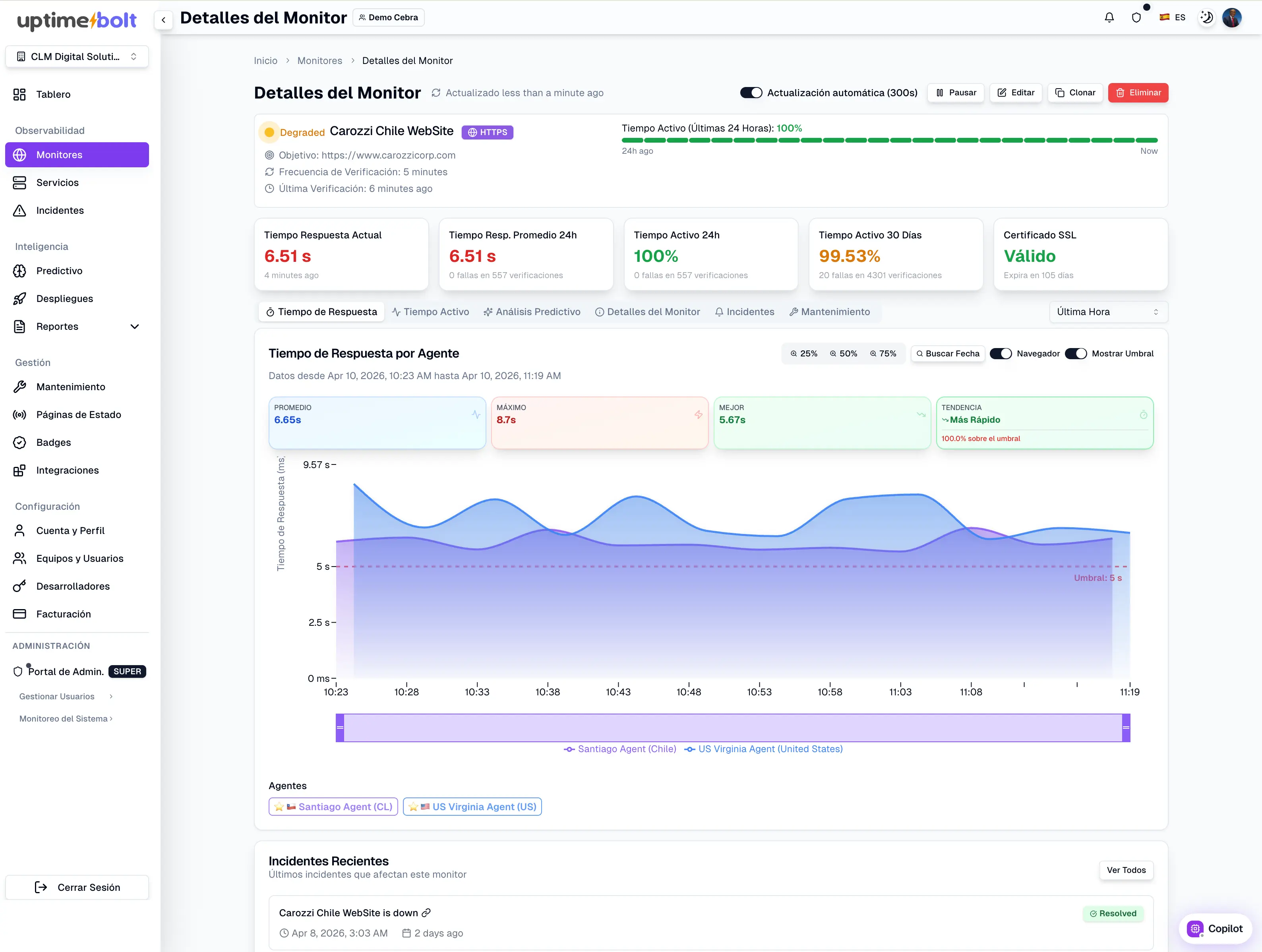
La predicción de incidentes no consiste en “adivinar el futuro”, sino en usar señales históricas y en tiempo real para identificar patrones que preceden fallas.
La inteligencia artificial permite detectar correlaciones como:
- p95 del login ↑ 18%
- Aumento de jitter en autenticación
- Incremento de reintentos
- Degradación en flujo E2E por región
Cada señal aislada no es crítica. Juntas, sí.
Ahí está el valor: actuar antes del impacto.
Los datos históricos permiten responder:
- ¿Cuándo ocurren los picos?
- ¿Qué flujos fallan primero?
- ¿Qué dependencias se degradan antes?
- ¿Dónde está el mayor riesgo real?
Esto permite pasar de una preparación genérica a una preparación estratégica.
No basta con validar endpoints. Hay que validar experiencia real de usuario.
Flujos clave:
- Login
- Búsqueda
- Checkout
- Pago
- Confirmación
El monitoreo E2E valida que todo el journey funcione, no solo partes aisladas.
- Latencias p95/p99
- Timeouts
- Retries
- Límites de concurrencia
- Queries lentas
- Locks
- Conexiones
- Índices
- Escalabilidad real
- Caché
- Circuit breakers
- Fallbacks
El objetivo: reforzar el eslabón más débil del sistema.
CDN y caché reducen carga en backend.
Errores comunes:
- Caché mal configurado
- TTLs bajos
- Assets sin cachear
Buenas prácticas:
Cache-Control: max-agestale-while-revalidate
Una buena estrategia de caché puede ser la diferencia entre estabilidad y colapso.
UptimeBolt combina:
- Monitoreo avanzado
- Detección de anomalías
- Predicción con IA
Permite:
- Detectar anomalías en tiempo real
- Identificar patrones previos
- Visualizar flujos E2E
- Reducir MTTD y MTTR
Resultado: actuar antes del impacto.
Los equipos reactivos responden rápido.
Los equipos predictivos evitan el problema antes de que ocurra.
La fiabilidad no se escala solo agregando infraestructura. Se diseña, se prueba y se anticipa.
Hoy, prepararse para eventos de alto tráfico significa combinar:
- Capacity planning
- Monitoreo E2E
- Pruebas synthetic
- Optimización de backend
- Estrategia de caché
- Predicción de incidentes con IA
En el ecosistema B2B, esto no es opcional.
Es la única forma real de proteger ingresos en momentos críticos.
¿Qué pasaría si pudieras predecir fallas 30 minutos antes de que la latencia impacte el checkout?
Cuando una empresa se prepara para Black Friday, Hot Sale, Buen Fin, un lanzamiento masivo o una campaña de marketing de alto alcance, suele pensar primero en capacidad: más instancias, más ancho de banda, más escalado automático, más CDN. Todo eso importa, pero no alcanza. En la práctica, muchos incidentes de alto tráfico no ocurren porque “faltó infraestructura” en términos absolutos, sino porque hubo un punto débil que nadie vio a tiempo. Aquí es donde la predicción de incidentes —cada vez más impulsada por inteligencia artificial— empieza a marcar la diferencia.
Ese es el gran error de enfoque. En eventos de alto tráfico web, no basta con soportar carga. Hay que anticipar fallas antes de que aparezcan. Una degradación de pocos minutos en el checkout, una API de pagos que empieza a responder con mayor latencia o una base de datos que se acerca lentamente a saturación puede traducirse en pérdidas directas de ingresos, tickets de soporte, abandono de usuarios y daño reputacional.
En este tipo de escenarios, la diferencia entre un equipo reactivo y uno realmente preparado no está en quién reacciona más rápido cuando todo se rompe. Está en quién detecta antes las señales que anuncian el problema. Ese es el terreno de la predicción de incidentes.
La conversación moderna sobre alto tráfico web ya no gira solo alrededor de “cuánto tráfico aguanta mi plataforma”, sino sobre una pregunta más estratégica:
¿puedo detectar saturaciones, degradaciones y cuellos de botella antes de que el usuario final los sufra?
Ahí es donde se conectan prácticas clásicas como capacity planning, pruebas de carga y tuning de infraestructura con enfoques más avanzados como monitoreo end-to-end, detección de anomalías y predicción de incidentes basada en inteligencia artificial.
Contexto: picos de tráfico como momentos de máximo riesgo operativo
Los eventos de alto tráfico son momentos de máxima exposición para cualquier plataforma digital. No solo porque hay más usuarios concurrentes, sino porque casi todos los componentes críticos trabajan cerca de sus límites al mismo tiempo: frontend, balanceadores, APIs, bases de datos, cachés, colas, servicios externos y pasarelas de pago.
Lo más delicado es que, en estos periodos, cualquier degradación tiene un costo multiplicado. Una latencia adicional de 2 o 3 segundos puede parecer tolerable en una hora normal, pero durante un evento comercial esa misma latencia puede reducir significativamente la tasa de conversión en flujos críticos como el checkout, además de disparar el abandono de carrito. En escenarios móviles, este impacto puede ser aún más agresivo: incrementos de apenas segundos en el tiempo de carga pueden duplicar la tasa de rebote.
A esto se suma la presión operativa:
Minutos de caída en una ventana de máximo tráfico no se distribuyen de forma uniforme durante el día: pegan justo cuando más dinero y confianza están en juego. El impacto no es lineal, es exponencial.
Por eso, prepararse para alto tráfico web no significa solo “tener más capacidad”. Significa entender que estos eventos son también pruebas de resiliencia operativa. Una arquitectura robusta en papel puede fallar si los equipos no tienen visibilidad real sobre lo que está pasando en cada capa del sistema.
Por qué las caídas ocurren incluso con infraestructura robusta
Uno de los malentendidos más comunes es creer que un sistema bien provisionado está automáticamente protegido. En realidad, muchos incidentes en eventos de alto tráfico ocurren en plataformas que sí tenían margen de infraestructura, pero fallaron por otros motivos.
Cuellos de botella
Una arquitectura puede escalar horizontalmente en frontend y API gateway, pero seguir dependiendo de una base de datos, una caché, una cola o una dependencia externa que no escala igual. El sistema en conjunto parece robusto, pero su punto más débil define el límite real.
Dependencias externas
Muchas plataformas modernas dependen de terceros para pagos, autenticación, scoring, logística, fraude o mensajería. Puedes tener tu infraestructura perfectamente preparada y aun así sufrir un colapso parcial porque una dependencia externa empieza a responder lento, devuelve errores intermitentes o agota sus propios recursos.
Degradaciones progresivas
Antes de que ocurra una caída visible, suele haber una fase previa donde:
El problema es que, si solo se mira disponibilidad binaria, esa fase pasa desapercibida.
Falta de visibilidad en sistemas distribuidos
En una arquitectura con microservicios, un flujo crítico como login o checkout atraviesa múltiples componentes. Cada uno puede “estar arriba” y aun así el flujo completo fallar. El monitoreo tradicional por servicio no alcanza para capturar esa realidad.
Alto tráfico web: por qué el enfoque reactivo ya no funciona
El enfoque reactivo asume que el sistema avisará claramente cuando algo salga mal. En la práctica, lo que suele ocurrir es que las alertas llegan cuando el impacto ya es visible.
Imagina un caso realista:
No hay caída total. No hay errores masivos. Pero la conversión ya empezó a caer.
Este aumento progresivo es, de hecho, una violación de nuestro SLO de latencia (ej. p95 < 1s), mucho antes de que se registre un error HTTP 5xx.
El problema del monitoreo reactivo es claro: llega tarde para el negocio.
Cómo la predicción de incidentes permite anticiparse a saturaciones
La predicción de incidentes no consiste en “adivinar el futuro”, sino en usar señales históricas y en tiempo real para identificar patrones que preceden fallas.
La inteligencia artificial permite detectar correlaciones como:
Cada señal aislada no es crítica. Juntas, sí.
Ahí está el valor: actuar antes del impacto.
Analizar patrones históricos para identificar ventanas de riesgo
Los datos históricos permiten responder:
Esto permite pasar de una preparación genérica a una preparación estratégica.
Pruebas synthetic y simulación de flujos críticos
No basta con validar endpoints. Hay que validar experiencia real de usuario.
Flujos clave:
El monitoreo E2E valida que todo el journey funcione, no solo partes aisladas.
Fortalecer APIs, bases de datos y microservicios
APIs
Bases de datos
Microservicios
El objetivo: reforzar el eslabón más débil del sistema.
El rol clave de CDNs y cachés
CDN y caché reducen carga en backend.
Errores comunes:
Buenas prácticas:
Cache-Control: max-agestale-while-revalidateUna buena estrategia de caché puede ser la diferencia entre estabilidad y colapso.
Cómo UptimeBolt anticipa incidentes entre 30 min y 48 h antes
UptimeBolt combina:
Permite:
Resultado: actuar antes del impacto.
Conclusión
Los equipos reactivos responden rápido.
Los equipos predictivos evitan el problema antes de que ocurra.
La fiabilidad no se escala solo agregando infraestructura. Se diseña, se prueba y se anticipa.
Hoy, prepararse para eventos de alto tráfico significa combinar:
En el ecosistema B2B, esto no es opcional.
Es la única forma real de proteger ingresos en momentos críticos.