Cada log que envías a Datadog, New Relic o Elastic ya existe en tu servidor. Pagas por generarlo. Luego pagas de nuevo para replicarlo e indexarlo fuera de tu infraestructura. En el 80% de los casos, esa duplicación no mejora tu MTTR de forma proporcional al costo. Aquí los números reales con pricing oficial verificado en marzo 2026.
Cuando tu aplicación escribe un log en producción, ese log ya te costó dinero: CPU que lo generó, disco que lo almacena, red si viaja dentro de tu VPC. Esa es tu primera frontera contable.
Luego instalas un agente de Datadog, New Relic o Elastic. El agente toma ese mismo log, lo comprime, lo envía al proveedor. Ahí lo ingieren, lo indexan, lo almacenan, te cobran por hacer queries sobre él, te cobran por retenerlo más allá del default, y te cobran por forwardearlo si lo mandas a un SIEM externo. Esa es tu segunda frontera contable.
El mismo activo cruzó tu presupuesto dos veces.
La justificación clásica es "lo necesito para correlacionar métricas, traces y logs en un solo lugar." Tiene validez técnica, pero asume algo falso en la mayoría de casos: que la correlación útil durante un incidente depende de tener el 100% del volumen de logs replicado y listo para query. En la mayoría de incidentes reales, esa premisa no se sostiene.
Veamos un caso realista. SaaS B2B con 25 microservicios en Kubernetes, 50 hosts monitoreados, dos ambientes, equipo de 15 personas (5 necesitan acceso full para debugging), 100 GB/día de logs de aplicación, SLA 99.9%.
Datadog tiene la particularidad de cobrar dos veces por los logs: una por ingestión ($0.10/GB) y otra por indexación ($1.70 por millón de eventos). Esto lo confirman análisis recientes: "Datadog charges twice for logs. First for ingesting them ($0.10/GB), then for indexing them ($1.70/million events). You can ingest without indexing (they go to archives only), but then you can't search them in the UI — which defeats the purpose for most teams."
Para nuestro caso (3,000 GB/mes de logs):
- Ingestión: ~$300/mes
- Indexación: ~$10,200/mes
- Infraestructura (50 hosts Pro × $15): $750/mes
- APM: ~$1,550/mes
Total estimado: $12,800/mes ($153,600/año) — y eso con retención estándar de 15 días. Un análisis independiente de marzo 2026 confirma este rango: "Your annual Datadog bill at 100 GB/day: approximately $107,400. And this is a conservative estimate. It excludes APM, RUM, synthetic monitoring, security monitoring, and any overages or spikes."
💡 ¿Te parece caro? Calcula el número exacto para tu caso con mi calculadora
gratis en Google Sheets → uptimebolt.com/calculadora-observabilidad
New Relic cobra por usuarios full-platform ($349/usuario/mes en Pro anual) y por GB ingerido después de los primeros 100 GB gratis ($0.40/GB en Original, $0.60/GB en Data Plus con retención extendida).
Para el mismo caso:
- 5 usuarios full-platform Pro: $1,745/mes
- Data ingest (~3,400 GB después del tier gratuito): $1,360-2,040/mes
Total estimado: $3,100-3,800/mes ($37,000-46,000/año)
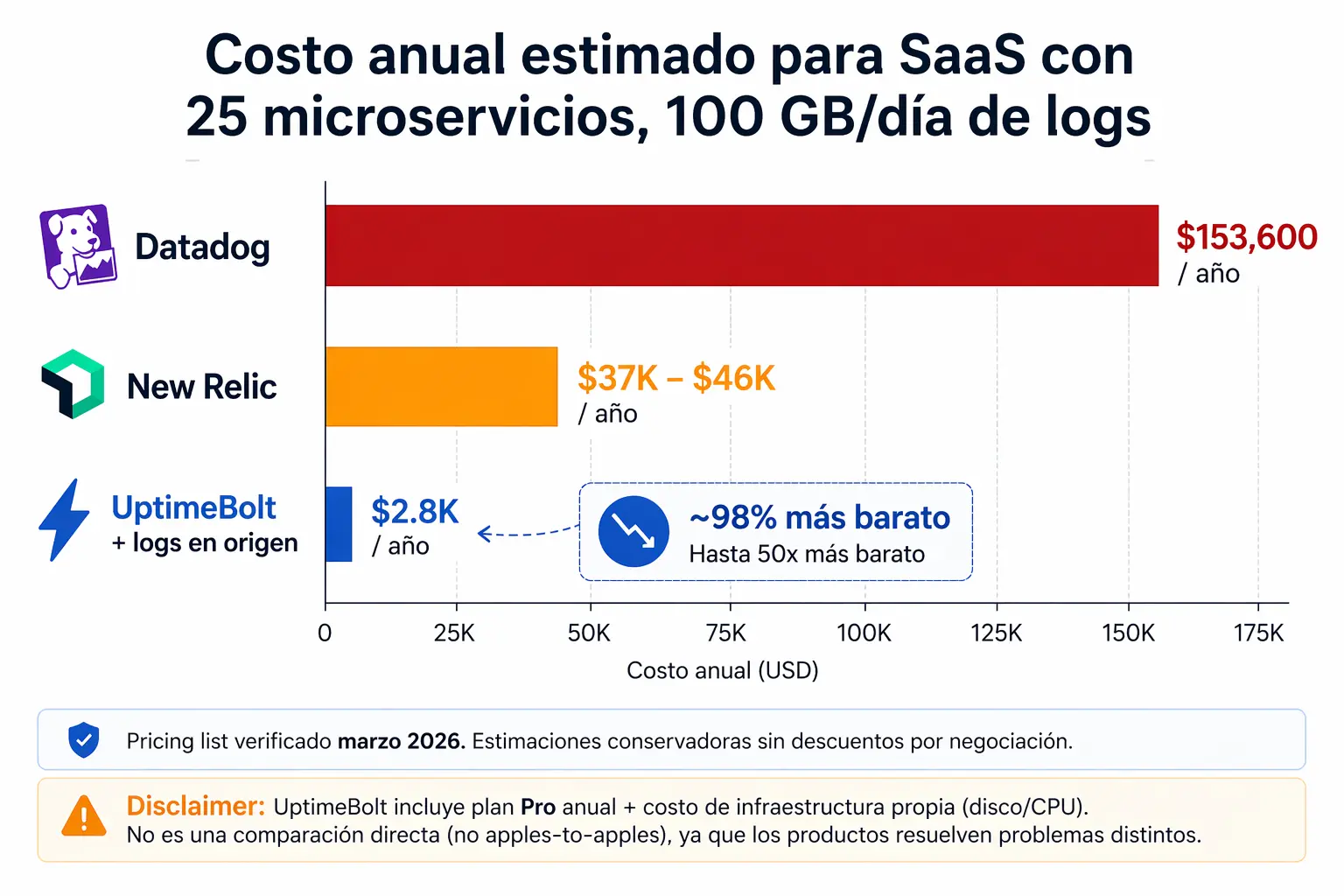
Importante entender un cliff de precio: "Standard caps at 5 full platform users. If you have a team of 6+ engineers who need full access, you're forced onto Pro at $349/user. That jump from $406/month (5 users on Standard) to $2,094/month (6 users on Pro) is the sharpest cost cliff in New Relic's pricing."
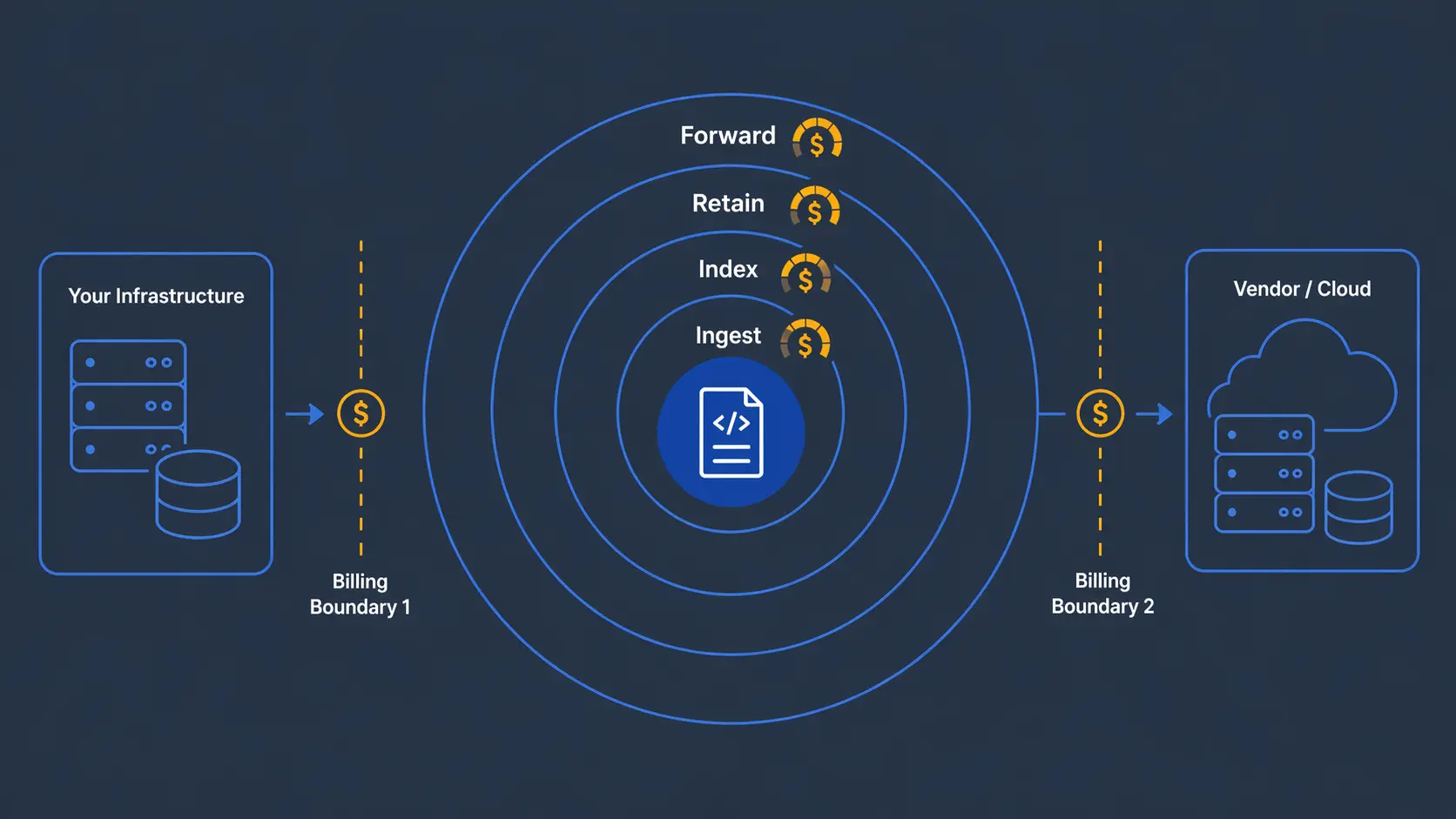
Observa qué estás pagando en ambos casos:
- Ingestión: transportar datos que ya generaste en tu infra hacia la del vendor
- Indexación: hacerlos searcheables en la UI del vendor, a pesar de que en muchos casos ya lo son con
grep o una query SQL al origen
- Retención: almacenarlos en la infra del vendor, a pesar de que ya los almacenas en la tuya
- Forwarding: si mandas los mismos logs a otro destino (SIEM, BI), Datadog cobra $0.25/GB adicional
La estructura del costo no refleja valor técnico. Refleja el número de fronteras contables que cruza un dato que ya era tuyo.
Para tu setup:
Costo_Datadog ≈ (hosts × $15) + (GB_logs_mes × $0.10) + (GB_logs_mes × 2M × $1.70/M) + (hosts × $31 APM)
El término dominante es casi siempre la indexación de logs. Crece linealmente con tu volumen y es el que explota cuando el equipo hace "structured logging" agresivo.
Y no olvides el costo de origen que ya estás pagando: CPU de generación (2-7% overhead en apps con logging agresivo), disco de almacenamiento ($0.04/GB/mes en GCP PD), y egress de red si los logs salen de tu VPC ($0.09/GB en AWS). En nuestro caso hipotético, eso añade $200-400/mes adicionales solo por mover datos que ya tenías.
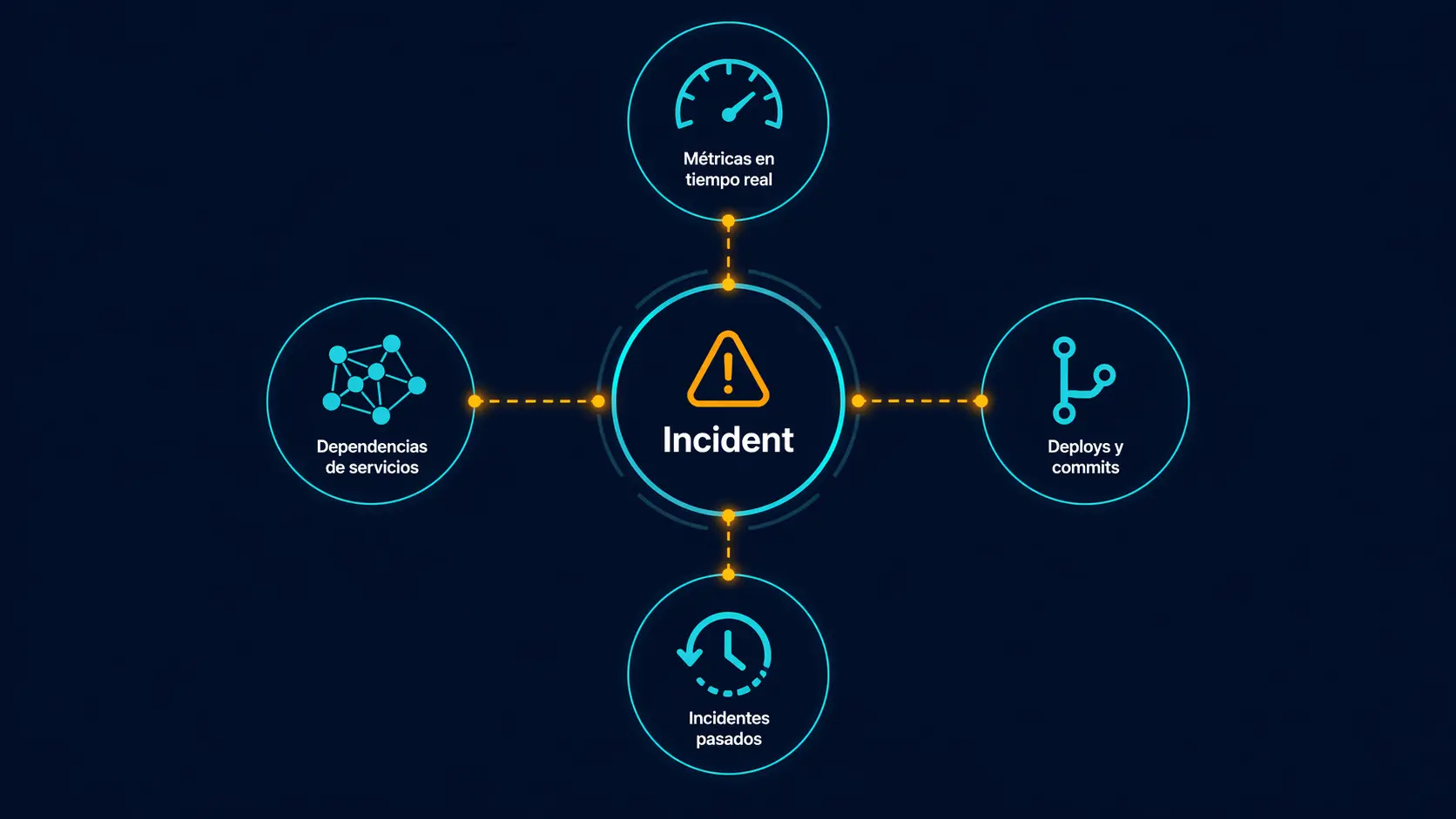 Después de observar cómo equipos SRE resuelven incidentes en producción, los datos que consistentemente correlacionan con reducción de MTTR son cuatro:
Después de observar cómo equipos SRE resuelven incidentes en producción, los datos que consistentemente correlacionan con reducción de MTTR son cuatro:
- Métricas del monitor afectado en la última hora. No el dashboard completo. El monitor específico que rompió.
- Deploys y commits en las 2 horas previas. Si algo cambió en producción, es el primer sospechoso.
- Incidentes similares en los últimos 90 días. Si ya pasó, el runbook probablemente existe.
- Grafo de dependencias del servicio afectado. Sin esto, el blast radius es adivinanza.
Ninguno requiere replicar el 100% del volumen de logs a un sistema externo. Lo que sí necesitas de logs es granular: los logs del servicio afectado, en la ventana específica del incidente, con los filtros específicos del síntoma. Eso lo puedes consultar en origen on-demand, no replicándolos 24/7.
Sería deshonesto decir que nunca vale. Tres casos donde el costo está justificado:
Compliance con retención de 7 años. HIPAA, PCI-DSS, sectores regulados. El log manager externo es el costo del compliance, no de la observabilidad.
Forense de seguridad en SOC. Si tu equipo busca patrones de ataque con queries complejas en ventanas largas, un SIEM con logs replicados es útil.
Microservicios con >50 servicios y tracing distribuido crítico. Si los traces entre servicios son el único camino para entender una request que falló, un APM enterprise completo es la herramienta correcta.
En mi experiencia observando el mercado LATAM y SMB global, estos tres casos son menos del 20% de los equipos que hoy pagan esa factura.
Si tu caso no cae en esos tres, tienes opciones más alineadas con tu costo real de MTTR:
Logs en origen + observabilidad de alta señal. Mantén los logs donde ya están (disco del servidor, S3, Cloud Storage). Usa una plataforma que detecte anomalías desde métricas de infra y monitores, correlacione con deploys automáticamente, y extraiga logs específicos solo cuando el RCA los pide. Eso es lo que estamos construyendo en UptimeBolt.
Open source self-hosted para logs. Grafana Loki, VictoriaLogs u OpenSearch en tu propia infra. Control total, cero replicación, costo real es cómputo + disco que ya pagas.
Híbrido con sampling. Configura el agente del vendor para mandar solo 5-10% de logs sampleados. Reduce factura 80-90% y mantiene búsqueda agregada. La correlación fina la haces con logs completos en origen cuando los necesitas.
La próxima vez que abras tu factura de observabilidad, no preguntes "¿cómo optimizo esto?" Pregunta primero: "¿cuándo fue la última vez que, en los primeros 10 minutos de un incidente real, abrí la UI del vendor y usé algo que no podría haber obtenido de los logs del servidor afectado en 2 minutos con grep o una query SQL al origen?"
Si la respuesta honesta es "casi nunca", estás pagando tranquilidad, no MTTR.
La tranquilidad es válida. Solo no la confundas con el costo real de resolver incidentes rápido. Son dos productos distintos.
No replicamos logs. Detectamos anomalías en las métricas que tu monitor ya genera. Cuando hay incidente, correlacionamos automáticamente con deploys recientes vía webhooks de GitHub/GitLab, buscamos incidentes similares en tu historial, y analizamos el grafo de dependencias.
Cuando el RCA necesita logs, los extraemos del servicio afectado en la ventana del incidente, desde su origen. No replicados. No almacenados en nuestra infraestructura. Just-in-time.
Por eso el plan free ofrece RCA real sin instrumentar nada, y los planes pagos empiezan en $23/mes anual.
¿Quieres los números exactos para tu setup?
Preparé una calculadora gratis con todas las fórmulas ya hechas. Ingresas
tus datos y obtienes el costo estimado en Datadog, New Relic y la
alternativa con logs en origen. Pricing oficial verificado marzo 2026.
→ uptimebolt.com/calculadora-observabilidad
Precios sujetos a descuentos por volumen y negociación. Verifica en las páginas oficiales al momento de decidir.
Pagas dos veces por los mismos logs: el cálculo real
TL;DR
Cada log que envías a Datadog, New Relic o Elastic ya existe en tu servidor. Pagas por generarlo. Luego pagas de nuevo para replicarlo e indexarlo fuera de tu infraestructura. En el 80% de los casos, esa duplicación no mejora tu MTTR de forma proporcional al costo. Aquí los números reales con pricing oficial verificado en marzo 2026.
El problema estructural
Cuando tu aplicación escribe un log en producción, ese log ya te costó dinero: CPU que lo generó, disco que lo almacena, red si viaja dentro de tu VPC. Esa es tu primera frontera contable.
Luego instalas un agente de Datadog, New Relic o Elastic. El agente toma ese mismo log, lo comprime, lo envía al proveedor. Ahí lo ingieren, lo indexan, lo almacenan, te cobran por hacer queries sobre él, te cobran por retenerlo más allá del default, y te cobran por forwardearlo si lo mandas a un SIEM externo. Esa es tu segunda frontera contable.
El mismo activo cruzó tu presupuesto dos veces.
La justificación clásica es "lo necesito para correlacionar métricas, traces y logs en un solo lugar." Tiene validez técnica, pero asume algo falso en la mayoría de casos: que la correlación útil durante un incidente depende de tener el 100% del volumen de logs replicado y listo para query. En la mayoría de incidentes reales, esa premisa no se sostiene.
El cálculo con pricing oficial
Veamos un caso realista. SaaS B2B con 25 microservicios en Kubernetes, 50 hosts monitoreados, dos ambientes, equipo de 15 personas (5 necesitan acceso full para debugging), 100 GB/día de logs de aplicación, SLA 99.9%.
Lo que cobra Datadog
Datadog tiene la particularidad de cobrar dos veces por los logs: una por ingestión ($0.10/GB) y otra por indexación ($1.70 por millón de eventos). Esto lo confirman análisis recientes: "Datadog charges twice for logs. First for ingesting them ($0.10/GB), then for indexing them ($1.70/million events). You can ingest without indexing (they go to archives only), but then you can't search them in the UI — which defeats the purpose for most teams."
Para nuestro caso (3,000 GB/mes de logs):
Total estimado:
$12,800/mes ($153,600/año) — y eso con retención estándar de 15 días. Un análisis independiente de marzo 2026 confirma este rango: "Your annual Datadog bill at 100 GB/day: approximately $107,400. And this is a conservative estimate. It excludes APM, RUM, synthetic monitoring, security monitoring, and any overages or spikes."💡 ¿Te parece caro? Calcula el número exacto para tu caso con mi calculadora gratis en Google Sheets → uptimebolt.com/calculadora-observabilidad
Lo que cobra New Relic
New Relic cobra por usuarios full-platform ($349/usuario/mes en Pro anual) y por GB ingerido después de los primeros 100 GB gratis ($0.40/GB en Original, $0.60/GB en Data Plus con retención extendida).
Para el mismo caso:
Total estimado:
$3,100-3,800/mes ($37,000-46,000/año)Importante entender un cliff de precio: "Standard caps at 5 full platform users. If you have a team of 6+ engineers who need full access, you're forced onto Pro at $349/user. That jump from $406/month (5 users on Standard) to $2,094/month (6 users on Pro) is the sharpest cost cliff in New Relic's pricing."
Dónde vive el pago doble
Observa qué estás pagando en ambos casos:
grepo una query SQL al origenLa estructura del costo no refleja valor técnico. Refleja el número de fronteras contables que cruza un dato que ya era tuyo.
Estima tu propio caso rápido
Para tu setup:
El término dominante es casi siempre la indexación de logs. Crece linealmente con tu volumen y es el que explota cuando el equipo hace "structured logging" agresivo.
Y no olvides el costo de origen que ya estás pagando: CPU de generación (2-7% overhead en apps con logging agresivo), disco de almacenamiento (
$0.04/GB/mes en GCP PD), y egress de red si los logs salen de tu VPC ($0.09/GB en AWS). En nuestro caso hipotético, eso añade $200-400/mes adicionales solo por mover datos que ya tenías.Lo que sí correlaciona con MTTR
Ninguno requiere replicar el 100% del volumen de logs a un sistema externo. Lo que sí necesitas de logs es granular: los logs del servicio afectado, en la ventana específica del incidente, con los filtros específicos del síntoma. Eso lo puedes consultar en origen on-demand, no replicándolos 24/7.
Cuándo sí aplica pagar doble
Sería deshonesto decir que nunca vale. Tres casos donde el costo está justificado:
Compliance con retención de 7 años. HIPAA, PCI-DSS, sectores regulados. El log manager externo es el costo del compliance, no de la observabilidad.
Forense de seguridad en SOC. Si tu equipo busca patrones de ataque con queries complejas en ventanas largas, un SIEM con logs replicados es útil.
Microservicios con >50 servicios y tracing distribuido crítico. Si los traces entre servicios son el único camino para entender una request que falló, un APM enterprise completo es la herramienta correcta.
En mi experiencia observando el mercado LATAM y SMB global, estos tres casos son menos del 20% de los equipos que hoy pagan esa factura.
El 80% restante: qué hacer
Si tu caso no cae en esos tres, tienes opciones más alineadas con tu costo real de MTTR:
Logs en origen + observabilidad de alta señal. Mantén los logs donde ya están (disco del servidor, S3, Cloud Storage). Usa una plataforma que detecte anomalías desde métricas de infra y monitores, correlacione con deploys automáticamente, y extraiga logs específicos solo cuando el RCA los pide. Eso es lo que estamos construyendo en UptimeBolt.
Open source self-hosted para logs. Grafana Loki, VictoriaLogs u OpenSearch en tu propia infra. Control total, cero replicación, costo real es cómputo + disco que ya pagas.
Híbrido con sampling. Configura el agente del vendor para mandar solo 5-10% de logs sampleados. Reduce factura 80-90% y mantiene búsqueda agregada. La correlación fina la haces con logs completos en origen cuando los necesitas.
La pregunta honesta
La próxima vez que abras tu factura de observabilidad, no preguntes "¿cómo optimizo esto?" Pregunta primero: "¿cuándo fue la última vez que, en los primeros 10 minutos de un incidente real, abrí la UI del vendor y usé algo que no podría haber obtenido de los logs del servidor afectado en 2 minutos con
grepo una query SQL al origen?"Si la respuesta honesta es "casi nunca", estás pagando tranquilidad, no MTTR.
La tranquilidad es válida. Solo no la confundas con el costo real de resolver incidentes rápido. Son dos productos distintos.
¿Qué hacemos diferente en UptimeBolt?
No replicamos logs. Detectamos anomalías en las métricas que tu monitor ya genera. Cuando hay incidente, correlacionamos automáticamente con deploys recientes vía webhooks de GitHub/GitLab, buscamos incidentes similares en tu historial, y analizamos el grafo de dependencias.
Cuando el RCA necesita logs, los extraemos del servicio afectado en la ventana del incidente, desde su origen. No replicados. No almacenados en nuestra infraestructura. Just-in-time.
Por eso el plan free ofrece RCA real sin instrumentar nada, y los planes pagos empiezan en $23/mes anual.
¿Quieres los números exactos para tu setup?
Preparé una calculadora gratis con todas las fórmulas ya hechas. Ingresas tus datos y obtienes el costo estimado en Datadog, New Relic y la alternativa con logs en origen. Pricing oficial verificado marzo 2026.
→ uptimebolt.com/calculadora-observabilidad
Prueba el enfoque opuesto al pago doble en uptimebolt.com, o usa AITRIAL14 para 14 días de Pro sin tarjeta.
Fuentes
Precios sujetos a descuentos por volumen y negociación. Verifica en las páginas oficiales al momento de decidir.