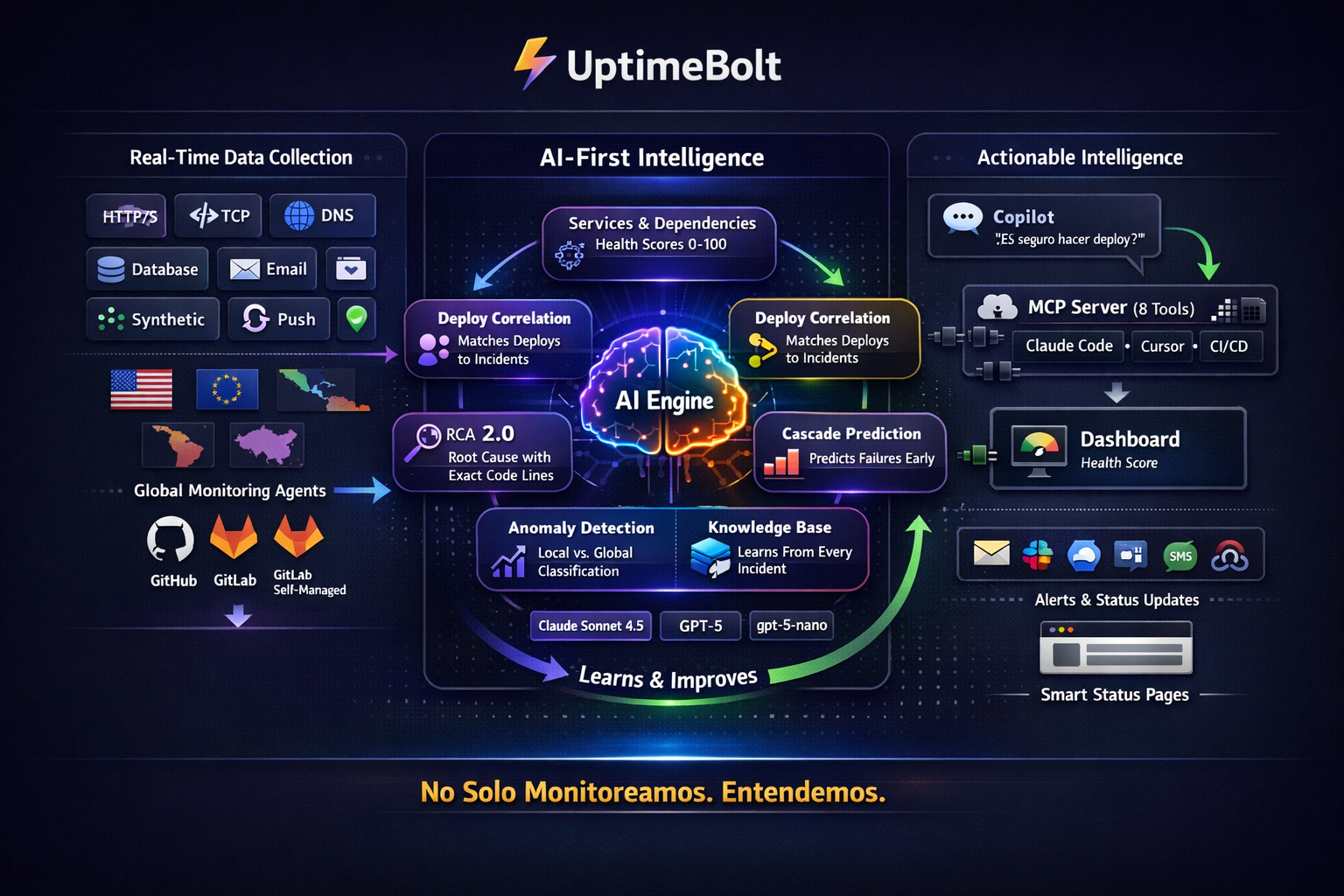
El salto de monolitos a arquitecturas distribuidas —microservicios, entornos serverless y sistemas event-driven— ha redefinido por completo el significado de “monitoreo”. Lo que antes implicaba observar unos pocos servidores y métricas básicas hoy exige visibilidad profunda sobre sistemas dinámicos, altamente desacoplados y en constante cambio.
Elegir una plataforma de monitoreo nunca fue trivial, pero hoy se ha convertido en una decisión estratégica que impacta directamente en la estabilidad del negocio, los costos operativos y la capacidad de escalar sin fricción. Lo que antes se resolvía con un par de dashboards y alertas básicas ahora requiere evaluar arquitecturas distribuidas, flujos end-to-end, dependencias externas, experiencia de usuario y prevención proactiva de incidentes.
En un entorno donde la complejidad es la norma y el downtime tiene impacto inmediato en ingresos y reputación, seleccionar la plataforma adecuada no es solo una decisión técnica: es una decisión de resiliencia operativa.
Las organizaciones modernas operan sobre sistemas cada vez más complejos:
- Microservicios
- APIs internas y externas
- Arquitecturas event-driven
- Múltiples regiones
- Pipelines CI/CD
- Flujos críticos que atraviesan decenas de componentes
En este escenario, el monitoreo tradicional por host o por métrica aislada ya no es suficiente.
Además, el contexto económico ha cambiado. Los CTOs y líderes de plataforma ya no solo preguntan “¿qué tan completo es el monitoreo?”, sino también:
- ¿Escala el costo de forma predecible?
- ¿Cuánto esfuerzo de configuración y tuning requiere el modelo de alertas para ser útil?
- ¿Reduce realmente el downtime o solo genera alertas?
- ¿Ayuda a prevenir incidentes o solo a reaccionar?
- ¿Aporta contexto o solo ruido?
Elegir mal una plataforma de monitoreo hoy implica:
- Sobrecostos crecientes por modelos de pricing rígidos
- Alert fatigue que desgasta a los equipos
- Falta de visibilidad en flujos críticos
- Incidentes detectados demasiado tarde
- Dependencia excesiva de conocimiento humano para interpretar datos
Por eso, una plataforma de monitoreo moderna no se define por cuántas métricas puede recolectar, sino por qué tan bien ayuda a tomar decisiones operativas antes de que el usuario sufra el impacto.
Uno de los errores más frecuentes al evaluar plataformas de monitoreo es asumir que “más funcionalidades” equivale automáticamente a “mejor monitoreo”.
El desafío no está en recolectar métricas, sino en convertir señales técnicas en decisiones accionables.
Una buena plataforma debe cubrir sólidamente lo esencial y, sobre esa base, ofrecer capacidades avanzadas que permitan evolucionar desde un monitoreo reactivo hacia uno preventivo y proactivo.

Una plataforma moderna debe poder responder:
- ¿Está disponible el servicio?
- ¿Desde dónde?
- ¿Con qué latencia?
Sin esta visibilidad básica, no existe punto de partida para la fiabilidad.
Una plataforma debe ofrecer visibilidad clara sobre:
- Latencia de APIs internas y externas
- Errores HTTP y timeouts
- Dependencias críticas de terceros
Sin visibilidad de APIs, los incidentes se detectan tarde y el diagnóstico se vuelve lento y costoso.
Una plataforma moderna debe permitir:
- Configurar alertas claras y específicas
- Ajustar sensibilidad según el contexto
- Evitar duplicados y falsos positivos
Alertar todo el tiempo no es monitorear bien.
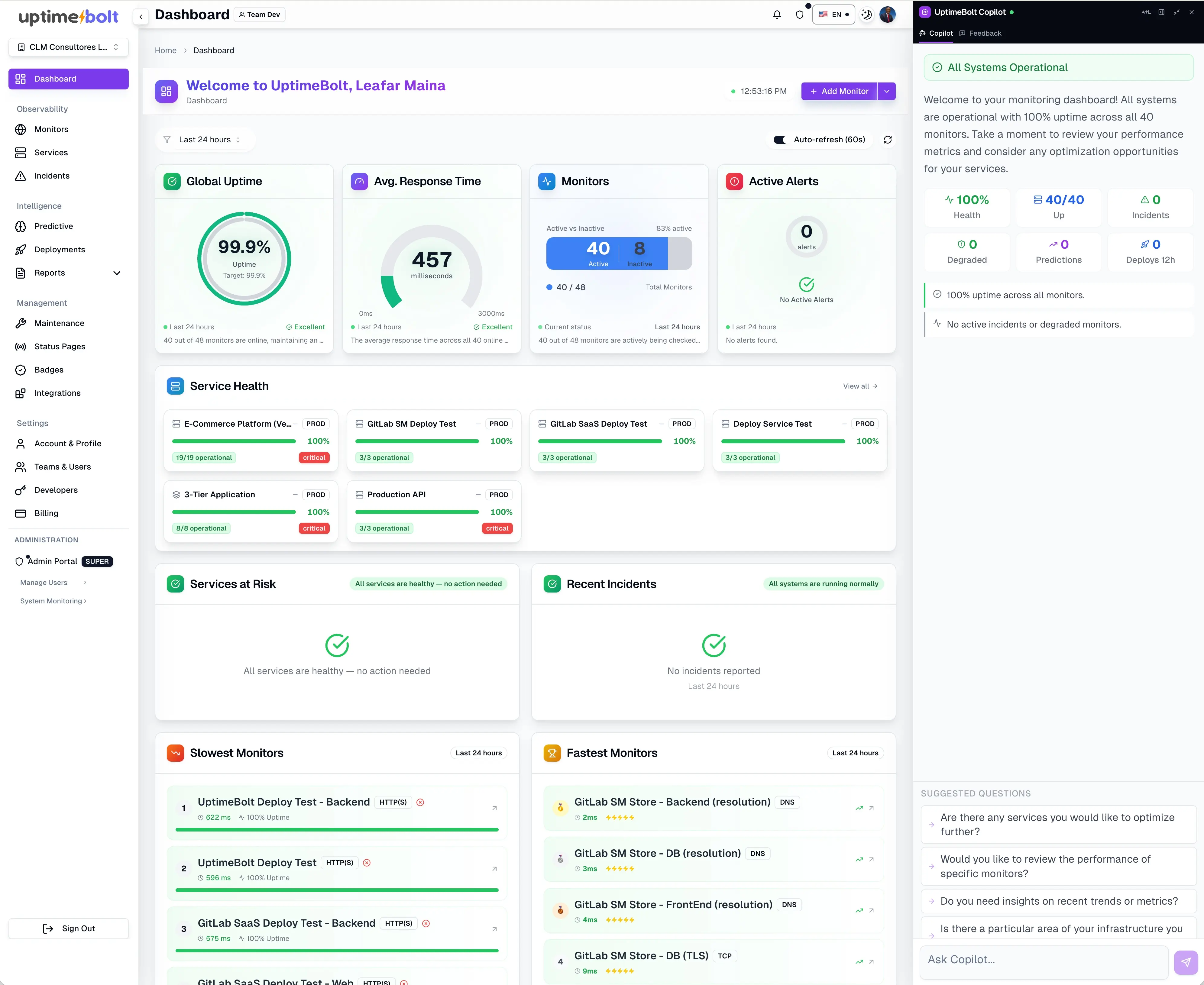
Los dashboards deben responder rápidamente:
- ¿Qué está pasando ahora?
- ¿Qué servicios están afectados?
- ¿Cuál es el impacto potencial?
Debe integrarse con:
- Slack
- Microsoft Teams
- PagerDuty
Cubrir solo lo esencial deja a la organización atrapada en un modelo reactivo con altos MTTD (Mean Time To Detect) y alto consumo de horas hombre en incidentes.
Permite validar flujos completos como los experimenta el usuario.
Responde a la pregunta clave:
¿Puede el usuario completar su objetivo ahora mismo?
Permite:
- Detectar regresiones
- Identificar errores intermitentes
- Validar APIs críticas
- Confirmar funcionamiento sin tráfico real
En lugar de preguntar:
¿Superó el umbral?
Pregunta:
¿Este comportamiento es normal para este sistema, en este momento?
Permite:
- Identificar degradaciones progresivas
- Detectar comportamientos inusuales
- Adaptarse a estacionalidad
Permite:
- Comparar comportamiento actual vs. histórico
- Identificar tendencias negativas
- Entender el contexto de un incidente
Debe responder:
- ¿Qué flujo está afectado?
- ¿Cuántos usuarios impacta?
- ¿Está relacionado con ingresos o SLAs?
Permite:
- Alertar antes de que el problema escale
- Detectar riesgos latentes
- Reducir MTTD y MTTR
Basadas en umbrales estáticos:
- CPU > 80%
- Latencia > 300ms
- Error rate > 5%
Problemas:
- Falsos positivos
- No detectan degradaciones sutiles
Se preguntan:
- ¿Este comportamiento es normal en este contexto?
- ¿Está cambiando la tendencia?
- ¿Históricamente precede un incidente?
Resultado: detección temprana y menos ruido.
Escala por:
Se alinea con:
- Flujos críticos
- Experiencia de usuario
- Impacto en negocio
Detecta:
- Servicio caído
- CPU saturada
- Endpoint no responde
Detecta:
- Degradaciones progresivas
- Cambios sutiles
- Patrones de riesgo
Requiere:
- Ajuste constante
- Revisión manual
- Refinamiento continuo
Permite:
- Adaptación automática
- Menos tuning
- Menos fatiga operativa
La plataforma de monitoreo que elijas define cómo tu organización responde al fallo, al crecimiento y a la presión del negocio.
No se trata de monitorear más, sino de monitorear mejor.
Las plataformas AI-first representan la evolución natural del monitoreo en entornos modernos. Elegir bien hoy puede ser la diferencia entre operar en modo reactivo o construir una operación verdaderamente resiliente.
Si quieres optimizar tu monitoreo y dar el salto hacia una prevención real de incidentes, comienza con UptimeBolt mediante una prueba gratuita y evalúa cómo una plataforma moderna puede transformar tu estabilidad operativa.
Cómo elegir una plataforma de monitoreo moderna
El salto de monolitos a arquitecturas distribuidas —microservicios, entornos serverless y sistemas event-driven— ha redefinido por completo el significado de “monitoreo”. Lo que antes implicaba observar unos pocos servidores y métricas básicas hoy exige visibilidad profunda sobre sistemas dinámicos, altamente desacoplados y en constante cambio.
Elegir una plataforma de monitoreo nunca fue trivial, pero hoy se ha convertido en una decisión estratégica que impacta directamente en la estabilidad del negocio, los costos operativos y la capacidad de escalar sin fricción. Lo que antes se resolvía con un par de dashboards y alertas básicas ahora requiere evaluar arquitecturas distribuidas, flujos end-to-end, dependencias externas, experiencia de usuario y prevención proactiva de incidentes.
En un entorno donde la complejidad es la norma y el downtime tiene impacto inmediato en ingresos y reputación, seleccionar la plataforma adecuada no es solo una decisión técnica: es una decisión de resiliencia operativa.
La nueva complejidad operativa
Las organizaciones modernas operan sobre sistemas cada vez más complejos:
En este escenario, el monitoreo tradicional por host o por métrica aislada ya no es suficiente.
Además, el contexto económico ha cambiado. Los CTOs y líderes de plataforma ya no solo preguntan “¿qué tan completo es el monitoreo?”, sino también:
Elegir mal una plataforma de monitoreo hoy implica:
Por eso, una plataforma de monitoreo moderna no se define por cuántas métricas puede recolectar, sino por qué tan bien ayuda a tomar decisiones operativas antes de que el usuario sufra el impacto.
Qué debe tener una plataforma de monitoreo moderna: lo esencial vs. lo deseable
Uno de los errores más frecuentes al evaluar plataformas de monitoreo es asumir que “más funcionalidades” equivale automáticamente a “mejor monitoreo”.
El desafío no está en recolectar métricas, sino en convertir señales técnicas en decisiones accionables.
Una buena plataforma debe cubrir sólidamente lo esencial y, sobre esa base, ofrecer capacidades avanzadas que permitan evolucionar desde un monitoreo reactivo hacia uno preventivo y proactivo.
Capacidades esenciales: la base operativa mínima (no negociables)
Monitoreo de disponibilidad y latencia
Una plataforma moderna debe poder responder:
Sin esta visibilidad básica, no existe punto de partida para la fiabilidad.
Visibilidad de APIs y servicios críticos
Una plataforma debe ofrecer visibilidad clara sobre:
Sin visibilidad de APIs, los incidentes se detectan tarde y el diagnóstico se vuelve lento y costoso.
Alertas configurables y confiables
Una plataforma moderna debe permitir:
Alertar todo el tiempo no es monitorear bien.
Dashboards claros y accionables
Los dashboards deben responder rápidamente:
Integraciones básicas con herramientas de notificación
Debe integrarse con:
Cubrir solo lo esencial deja a la organización atrapada en un modelo reactivo con altos MTTD (Mean Time To Detect) y alto consumo de horas hombre en incidentes.
Capacidades diferenciales: el verdadero salto de madurez
Monitoreo end-to-end (E2E)
Permite validar flujos completos como los experimenta el usuario.
Responde a la pregunta clave:
Monitoreo synthetic continuo
Permite:
Detección automática de anomalías
En lugar de preguntar:
Pregunta:
Permite:
Análisis de comportamiento histórico
Permite:
Contexto para priorizar incidentes
Debe responder:
Predicción temprana de incidentes
Permite:
Herramientas legacy vs. plataformas AI-first
1. Modelo de detección
Herramientas legacy
Basadas en umbrales estáticos:
Problemas:
Plataformas AI-first
Se preguntan:
Resultado: detección temprana y menos ruido.
2. Enfoque de costo
Legacy
Escala por:
AI-first
Se alinea con:
3. Tipo de problema que resuelve
Legacy
Detecta:
AI-first
Detecta:
4. Esfuerzo de mantenimiento
Legacy
Requiere:
AI-first
Permite:
Conclusión
La plataforma de monitoreo que elijas define cómo tu organización responde al fallo, al crecimiento y a la presión del negocio.
No se trata de monitorear más, sino de monitorear mejor.
Las plataformas AI-first representan la evolución natural del monitoreo en entornos modernos. Elegir bien hoy puede ser la diferencia entre operar en modo reactivo o construir una operación verdaderamente resiliente.
Si quieres optimizar tu monitoreo y dar el salto hacia una prevención real de incidentes, comienza con UptimeBolt mediante una prueba gratuita y evalúa cómo una plataforma moderna puede transformar tu estabilidad operativa.