Reducir el MTTR es uno de los mayores desafíos para los equipos de tecnología modernos. El MTTR (Mean Time to Recovery) mide cuánto tiempo tarda una organización en recuperar un servicio después de un incidente, y su impacto va mucho más allá del área técnica: afecta directamente a SLAs, experiencia de usuario, costos operativos y reputación del negocio.
En entornos digitales complejos, donde las arquitecturas son distribuidas, los servicios dependen de múltiples APIs y los sistemas cambian constantemente, reducir el MTTR con métodos tradicionales es cada vez más difícil. Aquí es donde la inteligencia artificial (IA) se convierte en un factor decisivo. Este artículo profundiza en cómo la IA permite reducir el MTTR de forma drástica, transformando la manera en que los equipos detectan, entienden y resuelven incidentes.
Durante años, muchas organizaciones se enfocaron casi exclusivamente en el uptime. Sin embargo, hoy se entiende que la disponibilidad por sí sola no cuenta toda la historia. Los incidentes ocurren, incluso en las mejores infraestructuras; lo que realmente marca la diferencia es qué tan rápido puedes recuperarte.
Un MTTR alto implica:
- Más tiempo de usuarios afectados
- Mayor riesgo de incumplir SLAs
- Incremento en tickets de soporte
- Pérdida de ingresos y confianza
Por el contrario, reducir el MTTR significa sistemas más resilientes y equipos más eficientes. En este contexto, reducir el MTTR ya no es solo un objetivo técnico, sino una prioridad estratégica para CTOs, líderes SRE y responsables de continuidad operativa.
Antes de entender cómo la IA ayuda a reducir el MTTR, es importante identificar qué lo incrementa en primer lugar. En infraestructuras modernas, estos son los factores más comunes.
Cuantos más servicios interactúan entre sí, más difícil es identificar dónde se originó un problema. Un fallo en un microservicio puede propagarse rápidamente y generar síntomas en múltiples puntos.
APIs de terceros, pasarelas de pago, servicios de autenticación o integraciones externas suelen ser cajas negras. Cuando fallan o se degradan, el diagnóstico manual se vuelve lento e impreciso.
Muchas alertas indican qué está fallando, pero no por qué. Sin contexto, los equipos pierden tiempo investigando señales aisladas.
Un exceso de alertas irrelevantes satura a los equipos, retrasa la respuesta y aumenta el tiempo hasta identificar el incidente real.
Revisar logs, métricas y dashboards de forma manual consume tiempo crítico durante un incidente. Cada minuto invertido en “buscar la causa” incrementa el MTTR.
Estos factores hacen que reducir el MTTR con enfoques tradicionales sea cada vez más complejo.
Para entender cómo la IA ayuda a reducir el MTTR, conviene analizar el ciclo completo de resolución de incidentes:
detectar → entender → resolver
La inteligencia artificial tiene impacto directo en cada una de estas etapas.
La IA permite identificar señales débiles antes de que ocurra un incidente visible. Al anticipar fallas potenciales, los equipos pueden actuar antes de que el sistema colapse, reduciendo drásticamente el tiempo de recuperación.
La detección de anomalías basada en IA identifica comportamientos inusuales que no encajan con el patrón normal del sistema. Estas anomalías suelen aparecer mucho antes de una caída total, dando margen para intervenir.
En lugar de analizar alertas aisladas, la IA correlaciona eventos, métricas y anomalías entre múltiples servicios. Esto permite entender rápidamente qué eventos están relacionados y cuáles son simples efectos colaterales.
Este trío —predicción, anomalías y correlación— transforma el MTTR porque reduce el tiempo perdido en detección y diagnóstico.
En el modelo tradicional, la detección ocurre cuando un umbral se rompe o un servicio cae. En ese punto, el impacto ya es visible para el usuario.
Con IA, la detección ocurre antes:
- Degradaciones progresivas de rendimiento
- Incrementos anómalos en latencia
- Patrones irregulares de tráfico
- Comportamientos atípicos en APIs o bases de datos
Al detectar estas señales tempranas, la IA permite iniciar acciones correctivas antes de que el incidente escale, reduciendo el MTTR incluso a cero en algunos casos.
El diagnóstico es, históricamente, la fase que más tiempo consume durante un incidente. Aquí es donde la IA genera uno de los mayores impactos.
La IA analiza grandes volúmenes de datos históricos y en tiempo real para identificar la causa raíz más probable. Esto elimina horas de investigación manual.
En lugar de revisar múltiples dashboards, los equipos reciben una visión contextualizada: qué servicio se degradó primero, qué dependencias están involucradas y qué cambios ocurrieron antes del incidente.
La IA ayuda a distinguir entre síntomas y causas reales, permitiendo que los equipos enfoquen sus esfuerzos donde realmente importa.
Todo esto acelera la fase de entendimiento del problema, reduciendo significativamente el MTTR.
Aunque la resolución final suele requerir intervención humana, la IA también aporta valor en esta etapa:
- Sugerencia de acciones correctivas basadas en incidentes pasados
- Identificación de configuraciones problemáticas
- Validación de que el sistema vuelve a su comportamiento normal tras el fix
Al cerrar el ciclo más rápido y con mayor precisión, reducir el MTTR se vuelve un proceso repetible y escalable.
Una plataforma SaaS experimentaba lentitud intermitente que no disparaba alertas tradicionales. La IA detectó anomalías en los tiempos de respuesta y correlacionó el problema con un cambio reciente en una dependencia externa. El incidente se resolvió en minutos en lugar de horas.
Durante un evento masivo, un e-commerce comenzó a mostrar fallos esporádicos en el checkout. La IA identificó patrones de saturación en una API crítica y permitió escalar recursos antes de una caída completa, reduciendo el MTTR de horas a minutos.
Una aplicación distribuida en varias regiones sufría fallos aleatorios. La correlación inteligente de eventos reveló un problema de latencia entre nubes. El diagnóstico automático permitió una resolución rápida y evitó reincidencias.
Estos ejemplos muestran cómo la IA no solo reduce el MTTR, sino que cambia radicalmente la experiencia de gestionar incidentes.
Reducir el MTTR con IA tiene efectos directos y medibles en el negocio.
Menos tiempo de recuperación significa menos penalizaciones y mayor confianza por parte de los clientes.
Los usuarios perciben menos interrupciones y degradaciones, incluso cuando ocurren incidentes internos.
Menos horas dedicadas a incidentes, menos tickets de soporte y menos esfuerzos reactivos.
Los equipos DevOps y SRE pueden enfocarse en mejorar la arquitectura en lugar de apagar incendios constantemente.
Reducir el MTTR deja de ser un objetivo aislado y se convierte en un multiplicador de eficiencia operativa.
Los casos y beneficios analizados muestran con claridad qué es posible cuando la inteligencia artificial se aplica correctamente al manejo de incidentes: detección temprana, diagnóstico rápido y resoluciones que antes tomaban horas y ahora ocurren en minutos.
UptimeBolt está diseñado para ayudar a reducir el MTTR de manera sistemática, integrando estas capacidades de IA directamente en el flujo operativo de los equipos técnicos.
En la práctica, UptimeBolt permite:
- Detección temprana de anomalías en servicios web, APIs, flujos E2E y bases de datos
- Predicción de incidentes basada en patrones históricos y señales débiles
- Correlación automática de eventos y métricas
- Análisis de causa raíz asistido por IA
- Alertas inteligentes con contexto claro y accionable
Al consolidar estas capacidades en una sola plataforma, UptimeBolt convierte lo que antes eran resoluciones excepcionales en un proceso repetible, escalable y predecible, incluso en infraestructuras altamente distribuidas.
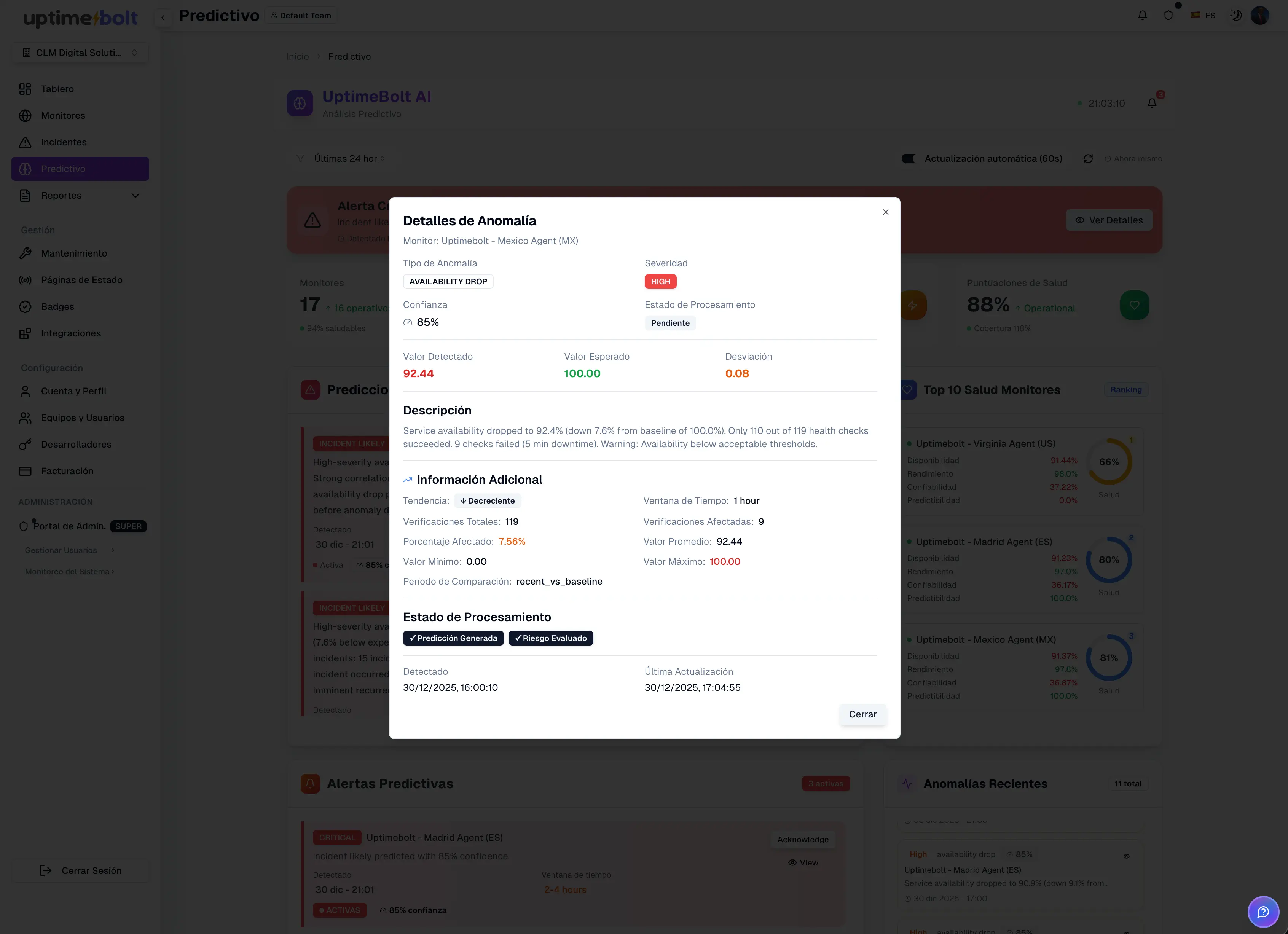
El MTTR seguirá siendo una métrica clave mientras existan sistemas digitales complejos. Sin embargo, la forma de reducirlo está cambiando. El enfoque reactivo, manual y basado en alertas aisladas ya no es suficiente.
La IA introduce un nuevo paradigma: detectar antes, entender más rápido y resolver con mayor precisión. Al combinar predicción de incidentes, detección de anomalías y correlación inteligente, los equipos pueden reducir el MTTR de forma drástica y sostenible.
En el futuro, reducir el MTTR no dependerá de reaccionar mejor, sino de prevenir de forma inteligente. Y ese futuro ya está aquí.
Si quieres reducir el MTTR usando IA y anticiparte a los incidentes antes de que afecten a tus usuarios, regístrate y obtén una prueba gratuita.
Reducir el MTTR es uno de los mayores desafíos para los equipos de tecnología modernos. El MTTR (Mean Time to Recovery) mide cuánto tiempo tarda una organización en recuperar un servicio después de un incidente, y su impacto va mucho más allá del área técnica: afecta directamente a SLAs, experiencia de usuario, costos operativos y reputación del negocio.
En entornos digitales complejos, donde las arquitecturas son distribuidas, los servicios dependen de múltiples APIs y los sistemas cambian constantemente, reducir el MTTR con métodos tradicionales es cada vez más difícil. Aquí es donde la inteligencia artificial (IA) se convierte en un factor decisivo. Este artículo profundiza en cómo la IA permite reducir el MTTR de forma drástica, transformando la manera en que los equipos detectan, entienden y resuelven incidentes.
Introducción: por qué el MTTR es una métrica crítica para equipos modernos
Durante años, muchas organizaciones se enfocaron casi exclusivamente en el uptime. Sin embargo, hoy se entiende que la disponibilidad por sí sola no cuenta toda la historia. Los incidentes ocurren, incluso en las mejores infraestructuras; lo que realmente marca la diferencia es qué tan rápido puedes recuperarte.
Un MTTR alto implica:
Por el contrario, reducir el MTTR significa sistemas más resilientes y equipos más eficientes. En este contexto, reducir el MTTR ya no es solo un objetivo técnico, sino una prioridad estratégica para CTOs, líderes SRE y responsables de continuidad operativa.
Factores que aumentan el MTTR en infraestructuras complejas
Antes de entender cómo la IA ayuda a reducir el MTTR, es importante identificar qué lo incrementa en primer lugar. En infraestructuras modernas, estos son los factores más comunes.
Arquitecturas distribuidas y microservicios
Cuantos más servicios interactúan entre sí, más difícil es identificar dónde se originó un problema. Un fallo en un microservicio puede propagarse rápidamente y generar síntomas en múltiples puntos.
Dependencias externas
APIs de terceros, pasarelas de pago, servicios de autenticación o integraciones externas suelen ser cajas negras. Cuando fallan o se degradan, el diagnóstico manual se vuelve lento e impreciso.
Falta de contexto en las alertas
Muchas alertas indican qué está fallando, pero no por qué. Sin contexto, los equipos pierden tiempo investigando señales aisladas.
Alert fatigue
Un exceso de alertas irrelevantes satura a los equipos, retrasa la respuesta y aumenta el tiempo hasta identificar el incidente real.
Diagnóstico manual
Revisar logs, métricas y dashboards de forma manual consume tiempo crítico durante un incidente. Cada minuto invertido en “buscar la causa” incrementa el MTTR.
Estos factores hacen que reducir el MTTR con enfoques tradicionales sea cada vez más complejo.
Cómo la IA impacta cada etapa del ciclo de resolución
Para entender cómo la IA ayuda a reducir el MTTR, conviene analizar el ciclo completo de resolución de incidentes:
detectar → entender → resolver
La inteligencia artificial tiene impacto directo en cada una de estas etapas.
Predicción, anomalías y correlación: el trío que reduce MTTR
Detección temprana mediante predicción de incidentes
La IA permite identificar señales débiles antes de que ocurra un incidente visible. Al anticipar fallas potenciales, los equipos pueden actuar antes de que el sistema colapse, reduciendo drásticamente el tiempo de recuperación.
Detección de anomalías
La detección de anomalías basada en IA identifica comportamientos inusuales que no encajan con el patrón normal del sistema. Estas anomalías suelen aparecer mucho antes de una caída total, dando margen para intervenir.
Correlación inteligente de eventos
En lugar de analizar alertas aisladas, la IA correlaciona eventos, métricas y anomalías entre múltiples servicios. Esto permite entender rápidamente qué eventos están relacionados y cuáles son simples efectos colaterales.
Este trío —predicción, anomalías y correlación— transforma el MTTR porque reduce el tiempo perdido en detección y diagnóstico.
Cómo la IA reduce el MTTR en la fase de detección
En el modelo tradicional, la detección ocurre cuando un umbral se rompe o un servicio cae. En ese punto, el impacto ya es visible para el usuario.
Con IA, la detección ocurre antes:
Al detectar estas señales tempranas, la IA permite iniciar acciones correctivas antes de que el incidente escale, reduciendo el MTTR incluso a cero en algunos casos.
Cómo la IA acelera el diagnóstico y reduce el MTTR
El diagnóstico es, históricamente, la fase que más tiempo consume durante un incidente. Aquí es donde la IA genera uno de los mayores impactos.
Root Cause Analysis asistido por IA
La IA analiza grandes volúmenes de datos históricos y en tiempo real para identificar la causa raíz más probable. Esto elimina horas de investigación manual.
Contexto automático
En lugar de revisar múltiples dashboards, los equipos reciben una visión contextualizada: qué servicio se degradó primero, qué dependencias están involucradas y qué cambios ocurrieron antes del incidente.
Priorización inteligente
La IA ayuda a distinguir entre síntomas y causas reales, permitiendo que los equipos enfoquen sus esfuerzos donde realmente importa.
Todo esto acelera la fase de entendimiento del problema, reduciendo significativamente el MTTR.
Cómo la IA impacta la fase de resolución
Aunque la resolución final suele requerir intervención humana, la IA también aporta valor en esta etapa:
Al cerrar el ciclo más rápido y con mayor precisión, reducir el MTTR se vuelve un proceso repetible y escalable.
Casos de uso reales: resolución acelerada gracias a IA
Caso 1: degradación silenciosa en una plataforma SaaS
Una plataforma SaaS experimentaba lentitud intermitente que no disparaba alertas tradicionales. La IA detectó anomalías en los tiempos de respuesta y correlacionó el problema con un cambio reciente en una dependencia externa. El incidente se resolvió en minutos en lugar de horas.
Caso 2: e-commerce en evento de alto tráfico
Durante un evento masivo, un e-commerce comenzó a mostrar fallos esporádicos en el checkout. La IA identificó patrones de saturación en una API crítica y permitió escalar recursos antes de una caída completa, reduciendo el MTTR de horas a minutos.
Caso 3: infraestructura multicloud
Una aplicación distribuida en varias regiones sufría fallos aleatorios. La correlación inteligente de eventos reveló un problema de latencia entre nubes. El diagnóstico automático permitió una resolución rápida y evitó reincidencias.
Estos ejemplos muestran cómo la IA no solo reduce el MTTR, sino que cambia radicalmente la experiencia de gestionar incidentes.
Beneficios para SLAs, clientes y operaciones
Reducir el MTTR con IA tiene efectos directos y medibles en el negocio.
Mejor cumplimiento de SLAs
Menos tiempo de recuperación significa menos penalizaciones y mayor confianza por parte de los clientes.
Mejor experiencia de usuario
Los usuarios perciben menos interrupciones y degradaciones, incluso cuando ocurren incidentes internos.
Menores costos operativos
Menos horas dedicadas a incidentes, menos tickets de soporte y menos esfuerzos reactivos.
Equipos más eficientes
Los equipos DevOps y SRE pueden enfocarse en mejorar la arquitectura en lugar de apagar incendios constantemente.
Reducir el MTTR deja de ser un objetivo aislado y se convierte en un multiplicador de eficiencia operativa.
Cómo UptimeBolt reduce MTTR mediante monitoreo predictivo
Los casos y beneficios analizados muestran con claridad qué es posible cuando la inteligencia artificial se aplica correctamente al manejo de incidentes: detección temprana, diagnóstico rápido y resoluciones que antes tomaban horas y ahora ocurren en minutos.
UptimeBolt está diseñado para ayudar a reducir el MTTR de manera sistemática, integrando estas capacidades de IA directamente en el flujo operativo de los equipos técnicos.
En la práctica, UptimeBolt permite:
Al consolidar estas capacidades en una sola plataforma, UptimeBolt convierte lo que antes eran resoluciones excepcionales en un proceso repetible, escalable y predecible, incluso en infraestructuras altamente distribuidas.
Conclusión: el MTTR del futuro será autónomo y preventivo
El MTTR seguirá siendo una métrica clave mientras existan sistemas digitales complejos. Sin embargo, la forma de reducirlo está cambiando. El enfoque reactivo, manual y basado en alertas aisladas ya no es suficiente.
La IA introduce un nuevo paradigma: detectar antes, entender más rápido y resolver con mayor precisión. Al combinar predicción de incidentes, detección de anomalías y correlación inteligente, los equipos pueden reducir el MTTR de forma drástica y sostenible.
En el futuro, reducir el MTTR no dependerá de reaccionar mejor, sino de prevenir de forma inteligente. Y ese futuro ya está aquí.
Si quieres reducir el MTTR usando IA y anticiparte a los incidentes antes de que afecten a tus usuarios, regístrate y obtén una prueba gratuita.