El root cause analysis es uno de los procesos más críticos dentro de las operaciones de TI modernas.
Ante cada incidente, caída de servicio o degradación de rendimiento, la pregunta clave es: ¿cuál fue la causa raíz?
En infraestructuras simples, responderla era relativamente directo. Hoy, con arquitecturas distribuidas, microservicios, APIs, nubes múltiples y dependencias externas, el root cause analysis tradicional se ha vuelto lento, manual y muchas veces ineficaz.
En este contexto, el root cause analysis impulsado por IA surge como la evolución natural del diagnóstico de incidentes. Este artículo compara ambos enfoques, explica sus diferencias reales, analiza sus limitaciones y muestra cómo la IA permite reducir drásticamente el MTTR, mejorar SLAs y aumentar la estabilidad operativa.
Hace algunos años, el root cause analysis consistía en revisar logs, observar métricas aisladas y reconstruir mentalmente la secuencia de eventos que llevó a un incidente. El proceso dependía en gran medida de la experiencia del ingeniero y del tiempo disponible.
Hoy, ese enfoque ya no escala. Las aplicaciones modernas generan miles de métricas por segundo, eventos distribuidos en múltiples servicios y comportamientos no lineales difíciles de interpretar manualmente. En este escenario, el root cause analysis tradicional suele responder tarde, cuando el daño ya está hecho.
El desafío actual no es solo encontrar la causa raíz, sino hacerlo rápidamente, con contexto y de forma repetible. Ahí es donde la IA transforma por completo el root cause analysis.
El root cause analysis tradicional sigue, en general, una secuencia como esta:
- Ocurre un incidente
- Se recibe una alerta
- El equipo revisa métricas y logs
- Se formulan hipótesis
- Se prueban posibles causas
- Se identifica (o se asume) una causa raíz
Este proceso puede tomar minutos, horas o incluso días, dependiendo de la complejidad del sistema.
El enfoque clásico del root cause analysis se basa en:
- Análisis manual de logs
- Revisión de dashboards
- Comparación histórica “a ojo”
- Comunicación entre múltiples equipos
- Experiencia previa del personal
Aunque este método puede funcionar en sistemas pequeños, presenta problemas graves en entornos modernos.
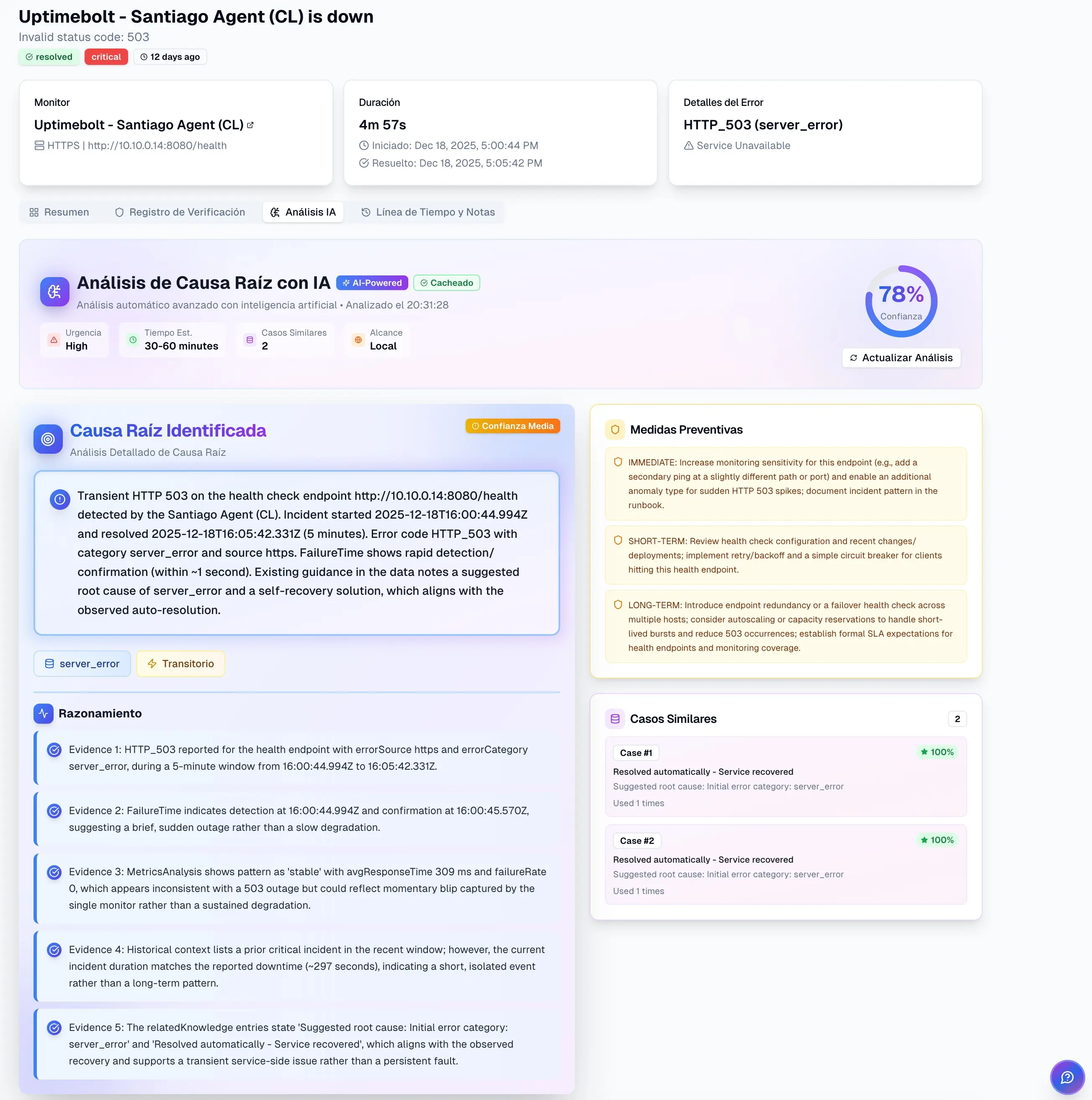
El root cause analysis tradicional no falla por falta de intención, sino por limitaciones estructurales.
La investigación manual consume tiempo valioso mientras el sistema sigue degradado o caído. Cada minuto adicional aumenta el impacto en usuarios y negocio.
Dos ingenieros pueden llegar a conclusiones distintas analizando el mismo incidente. El root cause analysis depende demasiado del criterio humano.
El enfoque clásico analiza métricas de forma aislada, sin correlacionar automáticamente eventos entre servicios, APIs, bases de datos y flujos E2E.
Muchas veces la causa raíz no está donde el síntoma es visible. El root cause analysis tradicional suele confundir efecto con causa.
La consecuencia directa es un MTTR alto, que afecta SLAs, reputación y costos operativos.
Estas limitaciones explican por qué, incluso con buen monitoreo, los incidentes siguen ocurriendo y repitiéndose.
El root cause analysis con IA introduce un cambio radical: en lugar de analizar señales aisladas, correlaciona automáticamente grandes volúmenes de datos para identificar la causa más probable del problema.
La IA aplicada al root cause analysis es capaz de:
- Correlacionar eventos en múltiples capas del sistema
- Analizar métricas como series de tiempo
- Detectar anomalías y patrones ocultos
- Entender relaciones causa–efecto
- Priorizar la causa más relevante
Esto permite pasar de “buscar la causa” a identificarla de forma automática y contextual.
El proceso de root cause analysis con IA suele incluir los siguientes pasos:
-
Ingesta masiva de datos
Métricas, logs, eventos, flujos E2E, APIs y bases de datos se analizan en conjunto.
-
Detección de anomalías
La IA identifica comportamientos inusuales que preceden al incidente.
-
Correlación automática de eventos
Eventos aparentemente independientes se agrupan según su relación temporal y causal.
-
Análisis de patrones históricos
Se comparan incidentes actuales con incidentes pasados para encontrar similitudes.
-
Identificación de la causa raíz más probable
El sistema propone la causa raíz con mayor impacto y probabilidad.
Gracias a este enfoque, el root cause analysis deja de ser reactivo y se vuelve predictivo y asistido por inteligencia artificial.
Para entender el verdadero impacto del root cause analysis con IA, es útil observar cómo funciona en escenarios reales, donde la complejidad hace que el análisis manual sea lento, impreciso y costoso.
Escenario
Una plataforma de e-commerce experimenta un aumento repentino en el tiempo de respuesta del checkout durante una campaña promocional.
El sitio sigue “arriba”, pero los usuarios comienzan a abandonar el carrito. Las métricas iniciales muestran:
- Incremento de latencia en la API de checkout
- Aumento intermitente de timeouts
- Uso de CPU aparentemente normal
- Sin errores claros en los logs principales
Análisis tradicional
El equipo recibe múltiples alertas aisladas.
Se revisan dashboards de infraestructura, luego logs de la API de checkout y luego bases de datos.
Surgen varias hipótesis: problema de red, saturación del backend, dependencia externa.
El diagnóstico manual toma más de 2 horas mientras el impacto en conversión continúa.
Root cause analysis con IA
La IA analiza métricas, eventos y anomalías en conjunto y reconstruye automáticamente la secuencia causal:
- Detecta una anomalía previa en la latencia de un microservicio de promociones
- Correlaciona ese evento con un aumento en llamadas síncronas hacia la base de datos
- Identifica que un cambio reciente activó una regla promocional más costosa bajo carga
- Determina que ese microservicio es la causa raíz del cuello de botella en checkout
Resultado
La causa raíz se identifica en menos de 3 minutos.
El equipo desactiva la regla problemática, restaura el rendimiento y evita una caída total del flujo de compra.
Escenario
Usuarios reportan fallos ocasionales al iniciar sesión. El problema no es constante y no afecta a todos los usuarios.
Los monitores tradicionales no detectan una caída clara.
Análisis tradicional
El equipo revisa logs de autenticación y no encuentra errores consistentes.
Se sospecha de red, luego de credenciales, luego de sesiones.
El problema persiste durante días, afectando la experiencia del usuario.
Root cause analysis con IA
La IA detecta un patrón anómalo en el tiempo de respuesta de un servicio de validación externa.
Correlaciona esa degradación con reintentos silenciosos en el flujo de login y con picos específicos de tráfico.
El análisis histórico revela que el problema aparece solo bajo ciertas condiciones de carga.
Resultado
La causa raíz —una dependencia externa degradándose bajo concurrencia— se identifica rápidamente.
El equipo ajusta timeouts y agrega un fallback, eliminando el fallo intermitente de forma definitiva.
Adoptar root cause analysis impulsado por inteligencia artificial genera beneficios inmediatos y medibles en cualquier entorno operativo moderno.
- Reducción significativa del MTTR
- Mejora en el cumplimiento de SLAs
- Menor reincidencia de incidentes
- Menor carga operativa para los equipos
- Mayor confianza en la toma de decisiones
Por estas razones, el root cause analysis con IA se está convirtiendo en un estándar operativo para equipos SRE y DevOps avanzados que gestionan infraestructuras complejas.
UptimeBolt integra el root cause analysis predictivo con IA directamente dentro de su plataforma de monitoreo, permitiendo que estos beneficios se apliquen de forma continua y automática.
Con UptimeBolt es posible:
- Correlacionar automáticamente métricas, eventos y anomalías en un mismo contexto
- Analizar dependencias entre servicios, APIs y flujos end-to-end
- Identificar causas raíz durante la degradación, no solo después de la caída
- Reducir drásticamente el MTTR
- Proporcionar contexto claro, priorizado y accionable
Además, UptimeBolt combina root cause analysis, detección de anomalías y predicción de incidentes, ofreciendo una visión completa del sistema:
qué está pasando, por qué está pasando y qué es probable que ocurra después.
El root cause analysis ya no puede depender únicamente del análisis manual y la experiencia individual. Las infraestructuras modernas son demasiado complejas, dinámicas y distribuidas.
El root cause analysis impulsado por IA representa la evolución natural del diagnóstico operativo: más rápido, más preciso y contextual.
En un mundo donde cada minuto de downtime cuenta, el futuro del root cause analysis es claro: autónomo, predictivo y basado en inteligencia artificial.
Si quieres probar el Root Cause Analysis con IA, ¡regístrate y obtén una prueba gratuita!
El root cause analysis es uno de los procesos más críticos dentro de las operaciones de TI modernas.
Ante cada incidente, caída de servicio o degradación de rendimiento, la pregunta clave es: ¿cuál fue la causa raíz?
En infraestructuras simples, responderla era relativamente directo. Hoy, con arquitecturas distribuidas, microservicios, APIs, nubes múltiples y dependencias externas, el root cause analysis tradicional se ha vuelto lento, manual y muchas veces ineficaz.
En este contexto, el root cause analysis impulsado por IA surge como la evolución natural del diagnóstico de incidentes. Este artículo compara ambos enfoques, explica sus diferencias reales, analiza sus limitaciones y muestra cómo la IA permite reducir drásticamente el MTTR, mejorar SLAs y aumentar la estabilidad operativa.
Introducción: el desafío moderno del root cause analysis en infraestructuras complejas
Hace algunos años, el root cause analysis consistía en revisar logs, observar métricas aisladas y reconstruir mentalmente la secuencia de eventos que llevó a un incidente. El proceso dependía en gran medida de la experiencia del ingeniero y del tiempo disponible.
Hoy, ese enfoque ya no escala. Las aplicaciones modernas generan miles de métricas por segundo, eventos distribuidos en múltiples servicios y comportamientos no lineales difíciles de interpretar manualmente. En este escenario, el root cause analysis tradicional suele responder tarde, cuando el daño ya está hecho.
El desafío actual no es solo encontrar la causa raíz, sino hacerlo rápidamente, con contexto y de forma repetible. Ahí es donde la IA transforma por completo el root cause analysis.
RCA tradicional: cómo funciona y por qué ya no es suficiente
El root cause analysis tradicional sigue, en general, una secuencia como esta:
Este proceso puede tomar minutos, horas o incluso días, dependiendo de la complejidad del sistema.
Cómo se realiza el root cause analysis clásico
El enfoque clásico del root cause analysis se basa en:
Aunque este método puede funcionar en sistemas pequeños, presenta problemas graves en entornos modernos.
Limitaciones del root cause analysis tradicional
El root cause analysis tradicional no falla por falta de intención, sino por limitaciones estructurales.
Procesos manuales y lentos
La investigación manual consume tiempo valioso mientras el sistema sigue degradado o caído. Cada minuto adicional aumenta el impacto en usuarios y negocio.
Subjetividad en el diagnóstico
Dos ingenieros pueden llegar a conclusiones distintas analizando el mismo incidente. El root cause analysis depende demasiado del criterio humano.
Falta de correlación real
El enfoque clásico analiza métricas de forma aislada, sin correlacionar automáticamente eventos entre servicios, APIs, bases de datos y flujos E2E.
Dificultad para detectar causas indirectas
Muchas veces la causa raíz no está donde el síntoma es visible. El root cause analysis tradicional suele confundir efecto con causa.
MTTR elevado
La consecuencia directa es un MTTR alto, que afecta SLAs, reputación y costos operativos.
Estas limitaciones explican por qué, incluso con buen monitoreo, los incidentes siguen ocurriendo y repitiéndose.
Root Cause Analysis con IA: correlación de eventos, patrones, anomalías y contexto
El root cause analysis con IA introduce un cambio radical: en lugar de analizar señales aisladas, correlaciona automáticamente grandes volúmenes de datos para identificar la causa más probable del problema.
Qué hace diferente al root cause analysis con IA
La IA aplicada al root cause analysis es capaz de:
Esto permite pasar de “buscar la causa” a identificarla de forma automática y contextual.
Cómo funciona el root cause analysis impulsado por IA
El proceso de root cause analysis con IA suele incluir los siguientes pasos:
Ingesta masiva de datos
Métricas, logs, eventos, flujos E2E, APIs y bases de datos se analizan en conjunto.
Detección de anomalías
La IA identifica comportamientos inusuales que preceden al incidente.
Correlación automática de eventos
Eventos aparentemente independientes se agrupan según su relación temporal y causal.
Análisis de patrones históricos
Se comparan incidentes actuales con incidentes pasados para encontrar similitudes.
Identificación de la causa raíz más probable
El sistema propone la causa raíz con mayor impacto y probabilidad.
Gracias a este enfoque, el root cause analysis deja de ser reactivo y se vuelve predictivo y asistido por inteligencia artificial.
Casos prácticos: cuando la IA identifica la causa raíz en minutos
Para entender el verdadero impacto del root cause analysis con IA, es útil observar cómo funciona en escenarios reales, donde la complejidad hace que el análisis manual sea lento, impreciso y costoso.
Caso 1: latencia crítica en la API de checkout durante un pico de tráfico
Escenario
Una plataforma de e-commerce experimenta un aumento repentino en el tiempo de respuesta del checkout durante una campaña promocional.
El sitio sigue “arriba”, pero los usuarios comienzan a abandonar el carrito. Las métricas iniciales muestran:
Análisis tradicional
El equipo recibe múltiples alertas aisladas.
Se revisan dashboards de infraestructura, luego logs de la API de checkout y luego bases de datos.
Surgen varias hipótesis: problema de red, saturación del backend, dependencia externa.
El diagnóstico manual toma más de 2 horas mientras el impacto en conversión continúa.
Root cause analysis con IA
La IA analiza métricas, eventos y anomalías en conjunto y reconstruye automáticamente la secuencia causal:
Resultado
La causa raíz se identifica en menos de 3 minutos.
El equipo desactiva la regla problemática, restaura el rendimiento y evita una caída total del flujo de compra.
Caso 2: fallos intermitentes en autenticación sin errores visibles
Escenario
Usuarios reportan fallos ocasionales al iniciar sesión. El problema no es constante y no afecta a todos los usuarios.
Los monitores tradicionales no detectan una caída clara.
Análisis tradicional
El equipo revisa logs de autenticación y no encuentra errores consistentes.
Se sospecha de red, luego de credenciales, luego de sesiones.
El problema persiste durante días, afectando la experiencia del usuario.
Root cause analysis con IA
La IA detecta un patrón anómalo en el tiempo de respuesta de un servicio de validación externa.
Correlaciona esa degradación con reintentos silenciosos en el flujo de login y con picos específicos de tráfico.
El análisis histórico revela que el problema aparece solo bajo ciertas condiciones de carga.
Resultado
La causa raíz —una dependencia externa degradándose bajo concurrencia— se identifica rápidamente.
El equipo ajusta timeouts y agrega un fallback, eliminando el fallo intermitente de forma definitiva.
Impacto directo del Root Cause Analysis con IA: menos tiempo perdido, mejores SLAs y más estabilidad
Adoptar root cause analysis impulsado por inteligencia artificial genera beneficios inmediatos y medibles en cualquier entorno operativo moderno.
Por estas razones, el root cause analysis con IA se está convirtiendo en un estándar operativo para equipos SRE y DevOps avanzados que gestionan infraestructuras complejas.
Cómo UptimeBolt lleva el Root Cause Analysis con IA a la práctica
UptimeBolt integra el root cause analysis predictivo con IA directamente dentro de su plataforma de monitoreo, permitiendo que estos beneficios se apliquen de forma continua y automática.
Con UptimeBolt es posible:
Además, UptimeBolt combina root cause analysis, detección de anomalías y predicción de incidentes, ofreciendo una visión completa del sistema:
qué está pasando, por qué está pasando y qué es probable que ocurra después.
Conclusión: el futuro del diagnóstico en operaciones es autónomo y predictivo
El root cause analysis ya no puede depender únicamente del análisis manual y la experiencia individual. Las infraestructuras modernas son demasiado complejas, dinámicas y distribuidas.
El root cause analysis impulsado por IA representa la evolución natural del diagnóstico operativo: más rápido, más preciso y contextual.
En un mundo donde cada minuto de downtime cuenta, el futuro del root cause analysis es claro: autónomo, predictivo y basado en inteligencia artificial.
Si quieres probar el Root Cause Analysis con IA, ¡regístrate y obtén una prueba gratuita!