La fiabilidad de microservicios es uno de los mayores desafíos en plataformas de e-commerce modernas. Los microservicios permiten escalar rápido, desplegar con frecuencia y evolucionar el producto sin grandes dependencias, pero también introducen un nuevo tipo de fragilidad: fallos distribuidos, degradaciones silenciosas y efectos en cascada que impactan directamente en ventas y experiencia del cliente.
En retail digital, donde el tráfico puede dispararse en segundos y cada transacción importa, una arquitectura distribuida mal preparada puede colapsar justo en los momentos más críticos. Durante picos de tráfico, una interrupción de apenas 15 minutos en el checkout puede traducirse en cientos de miles de dólares en ventas perdidas, incluso si el resto de la plataforma sigue “en línea”.
Este artículo presenta un framework práctico y accionable para mejorar la fiabilidad de microservicios en e-commerce, combinando buenas prácticas de ingeniería, monitoreo avanzado, pruebas synthetic y predicción de incidentes con inteligencia artificial, con un objetivo claro: evitar que fallos técnicos se conviertan en pérdidas reales de negocio.
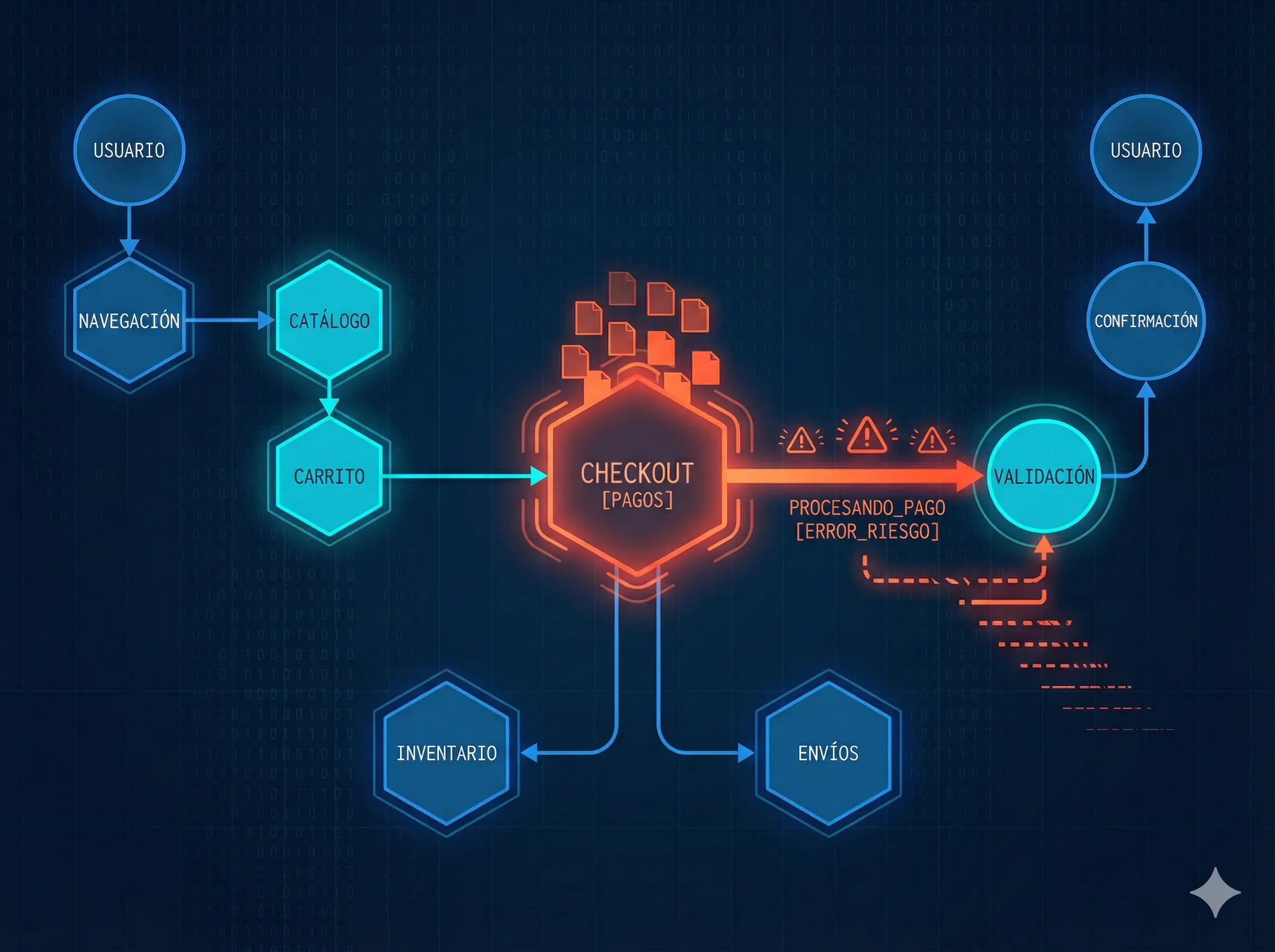
Los microservicios ofrecen ventajas claras: escalabilidad independiente, despliegues más rápidos y equipos autónomos. Sin embargo, en e-commerce esas ventajas vienen acompañadas de riesgos específicos que no siempre son evidentes en entornos distribuidos.
En una plataforma típica, un flujo de compra involucra decenas de servicios interconectados: catálogo, precios, promociones, carrito, inventario, pagos, envíos, antifraude, notificaciones y servicios externos. Estos servicios suelen comunicarse de forma síncrona en puntos críticos del journey del usuario.
Por ejemplo, una degradación en la API del Servicio de Promociones puede aumentar el tiempo de respuesta del Servicio de Carrito, que a su vez bloquea el hilo de ejecución del Servicio de Inventario mientras espera el cálculo final del precio. Bajo carga, este bloqueo puede provocar exhaustión de threads o conexiones, generando latencias en cascada que terminan haciendo que el Servicio de Checkout agote su timeout, incluso cuando ningún servicio está completamente caído.
Este tipo de fallos no se manifiesta como una caída total, sino como degradaciones progresivas, timeouts intermitentes o errores parciales que impactan directamente en conversión y experiencia del cliente.
Por eso, la fiabilidad de microservicios en e-commerce no depende de que cada servicio funcione de forma aislada, sino de que todo el conjunto funcione correctamente bajo carga real, con dependencias internas y externas, y en escenarios no ideales.
Antes de definir un framework, es clave entender dónde suelen fallar los microservicios en retail digital.
-
Latencia acumulada
Cada llamada entre servicios añade latencia. Un flujo puede ser funcional pero demasiado lento para el usuario.
-
Dependencias críticas ocultas
Servicios aparentemente secundarios pueden convertirse en cuellos de botella durante picos de tráfico.
-
Timeouts mal configurados
Timeouts demasiado altos bloquean recursos; demasiado bajos generan errores innecesarios.
-
Degradación silenciosa
Un servicio responde, pero de forma incorrecta o intermitente, sin disparar alertas claras.
-
Cascadas de fallos
La caída o lentitud de un servicio se propaga a otros, amplificando el impacto.
Mejorar la fiabilidad de microservicios implica atacar estos puntos de forma sistemática.
A continuación, un framework paso a paso pensado específicamente para plataformas de e-commerce.
No todos los microservicios tienen el mismo impacto. El primer paso es identificar qué flujos generan valor real.
En e-commerce, los más comunes son:
- Login y autenticación
- Navegación y búsqueda
- Carrito de compras
- Checkout
- Pago y confirmación
La fiabilidad de microservicios debe evaluarse desde estos journeys, no desde servicios individuales.
Una vez definidos los flujos críticos, es necesario mapear qué servicios participan y cómo se relacionan.
Este mapa permite:
- Identificar dependencias fuertes
- Detectar single points of failure
- Priorizar servicios críticos
- Entender impactos en cascada
Sin este mapa, la fiabilidad de microservicios se gestiona a ciegas.
Alta disponibilidad no garantiza fiabilidad. En microservicios, la resiliencia es clave.
Buenas prácticas incluyen:
- Definir un Error Budget y un SLO de latencia
- Circuit breakers para evitar cascadas
- Retries controlados
- Fallbacks cuando un servicio falla
- Degradación funcional aceptable
Por ejemplo, mostrar productos sin recomendaciones es preferible a romper todo el flujo.
Timeouts genéricos son una causa común de fallos en e-commerce.
Cada servicio debe tener:
- Timeouts alineados con la experiencia del usuario
- Límites claros de concurrencia, utilizando rate limiters a nivel de API Gateway y el patrón de bulkheads para aislar servicios secundarios (por ejemplo, Recomendaciones) y proteger los críticos (Checkout)
- Protección frente a saturación
La fiabilidad de microservicios mejora cuando los límites están diseñados pensando en el journey completo.
Monitorear microservicios de forma individual no garantiza que el sistema funcione como un todo.
El monitoreo synthetic permite validar journeys completos simulando usuarios, como:
- Login → búsqueda → carrito → checkout → pago
Es importante aclarar que esto no mide comportamiento real del usuario (eso corresponde a RUM), sino que valida el comportamiento real del sistema simulando usuarios de forma controlada.
Este enfoque detecta:
- Flujos rotos aunque los servicios estén “arriba”
- Errores lógicos entre servicios
- Degradaciones progresivas
Para la fiabilidad de microservicios en e-commerce, este tipo de validación es indispensable.
Los microservicios se comunican principalmente vía APIs. Si estas fallan, todo el sistema sufre.
El monitoreo debe cubrir:
- Latencia entre servicios
- Errores intermitentes
- Timeouts y respuestas incompletas
- Cambios en contratos de API
Monitorear APIs de forma aislada no basta; deben correlacionarse dentro del flujo de negocio.
En e-commerce, la conversión suele caer antes de que el sistema se caiga.
Señales tempranas de degradación incluyen:
-
Aumento gradual en tiempos de respuesta
La monitorización debe enfocarse en la latencia P99 de servicios críticos (por ejemplo, Pago y Checkout) y alertar si supera un umbral de degradación (ej. +20 % en 5 minutos).
-
Errores esporádicos en checkout
-
Pagos que tardan más de lo normal
-
Reintentos invisibles para el usuario
La detección temprana de anomalías permite actuar antes de que estas degradaciones impacten métricas de negocio.
La complejidad de la fiabilidad de microservicios hace que el análisis manual sea insuficiente.
La IA permite:
- Detectar anomalías no evidentes
(ejemplo: correlacionar un pico de errores 503 en Inventario con una caída del throughput de la base de datos de Catálogo y un aumento de latencia P50 en Autenticación)
- Correlacionar eventos entre servicios
- Identificar patrones previos a incidentes
- Priorizar riesgos reales para el negocio
En e-commerce, donde los picos de tráfico son predecibles pero intensos, la predicción de incidentes marca la diferencia entre estabilidad y caída.
Un framework efectivo no se limita a producción. La fiabilidad de microservicios debe validarse antes y después de cada release.
Esto incluye:
- Pruebas synthetic en entornos de staging
- Validaciones post-deploy en producción
- Monitoreo continuo de flujos críticos
Así se evita que cambios pequeños rompan journeys completos.
Antes de un evento crítico, un equipo debería poder responder afirmativamente a estas preguntas:
- ¿Tenemos identificados los journeys críticos?
- ¿Conocemos las dependencias entre microservicios?
- ¿Existen circuit breakers y fallbacks?
- ¿Los timeouts están bien definidos?
- ¿Simulamos flujos completos de forma continua?
- ¿Monitoreamos APIs internas con contexto?
- ¿Detectamos degradaciones antes de que haya caídas?
- ¿Usamos datos e IA para anticipar incidentes?
Si alguna respuesta es “no”, la fiabilidad de microservicios está en riesgo.
UptimeBolt está diseñado para abordar la fiabilidad de microservicios desde una perspectiva end-to-end y orientada a negocio.
La plataforma permite:
- Monitoreo synthetic de journeys completos de e-commerce
- Monitoreo de APIs entre microservicios
- Detección de anomalías basada en IA
- Predicción de incidentes antes de picos de tráfico
- Correlación automática de eventos
- Alertas inteligentes con contexto claro
Este enfoque permite a los equipos anticiparse a fallos, proteger conversiones y operar con mayor confianza incluso bajo carga extrema.
Si quieres fortalecer la fiabilidad de microservicios en tu plataforma de e-commerce y evitar que un servicio rompa todo el flujo de ventas, regístrate y obtén una prueba gratuita.
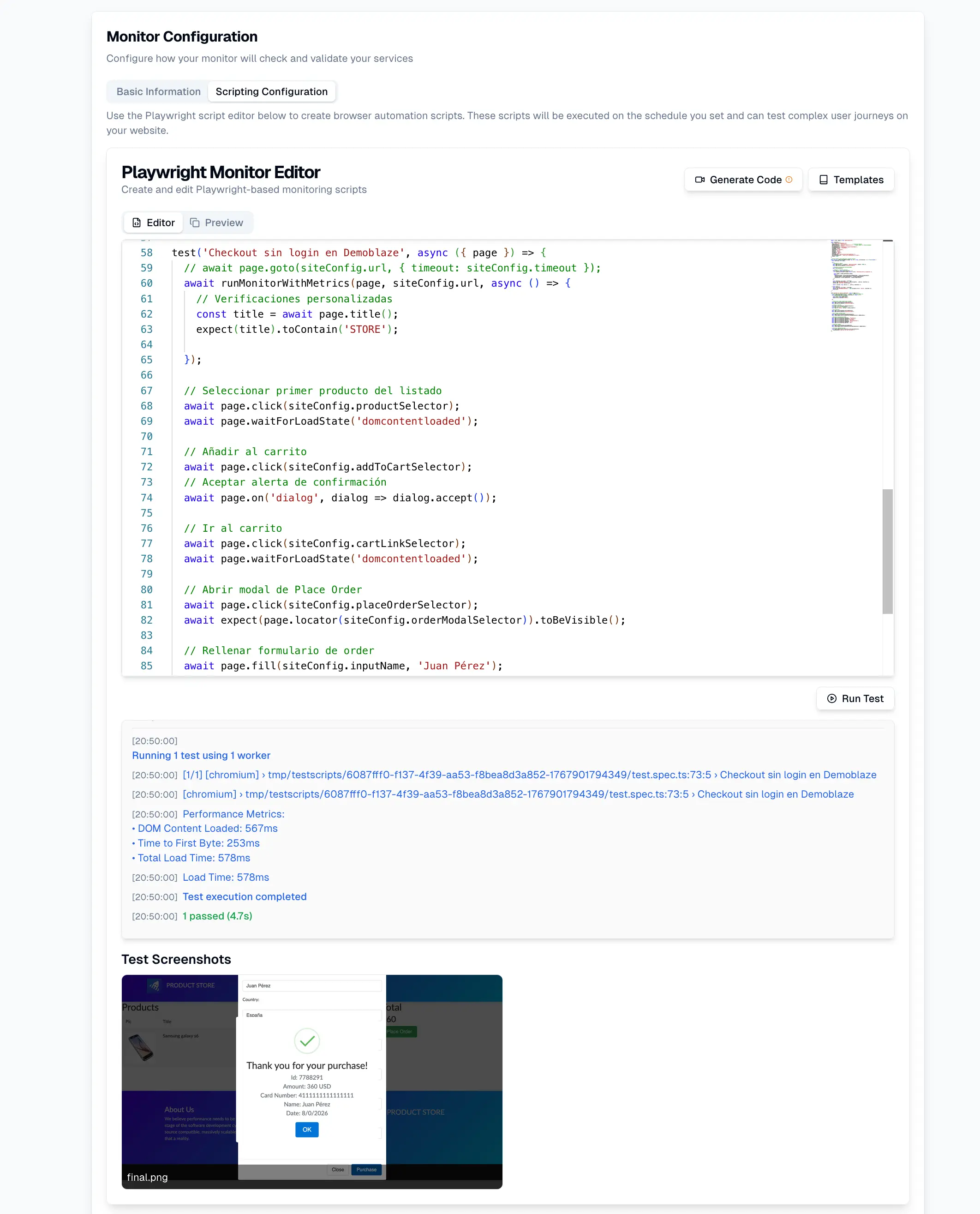
En e-commerce, la tecnología no es solo un soporte del negocio: es el negocio. Una arquitectura de microservicios mal preparada puede escalar rápido, pero también fallar rápido cuando más importa.
Aplicar un framework práctico para mejorar la fiabilidad de microservicios permite detectar riesgos antes de que impacten conversiones, anticiparse a incidentes y ofrecer experiencias estables incluso en condiciones extremas.
En retail digital, el éxito no lo define quién lanza más rápido, sino quién se mantiene confiable cuando todos los usuarios llegan al mismo tiempo.
La fiabilidad de microservicios es uno de los mayores desafíos en plataformas de e-commerce modernas. Los microservicios permiten escalar rápido, desplegar con frecuencia y evolucionar el producto sin grandes dependencias, pero también introducen un nuevo tipo de fragilidad: fallos distribuidos, degradaciones silenciosas y efectos en cascada que impactan directamente en ventas y experiencia del cliente.
En retail digital, donde el tráfico puede dispararse en segundos y cada transacción importa, una arquitectura distribuida mal preparada puede colapsar justo en los momentos más críticos. Durante picos de tráfico, una interrupción de apenas 15 minutos en el checkout puede traducirse en cientos de miles de dólares en ventas perdidas, incluso si el resto de la plataforma sigue “en línea”.
Este artículo presenta un framework práctico y accionable para mejorar la fiabilidad de microservicios en e-commerce, combinando buenas prácticas de ingeniería, monitoreo avanzado, pruebas synthetic y predicción de incidentes con inteligencia artificial, con un objetivo claro: evitar que fallos técnicos se conviertan en pérdidas reales de negocio.
Por qué los microservicios son potentes pero frágiles en e-commerce
Los microservicios ofrecen ventajas claras: escalabilidad independiente, despliegues más rápidos y equipos autónomos. Sin embargo, en e-commerce esas ventajas vienen acompañadas de riesgos específicos que no siempre son evidentes en entornos distribuidos.
En una plataforma típica, un flujo de compra involucra decenas de servicios interconectados: catálogo, precios, promociones, carrito, inventario, pagos, envíos, antifraude, notificaciones y servicios externos. Estos servicios suelen comunicarse de forma síncrona en puntos críticos del journey del usuario.
Por ejemplo, una degradación en la API del Servicio de Promociones puede aumentar el tiempo de respuesta del Servicio de Carrito, que a su vez bloquea el hilo de ejecución del Servicio de Inventario mientras espera el cálculo final del precio. Bajo carga, este bloqueo puede provocar exhaustión de threads o conexiones, generando latencias en cascada que terminan haciendo que el Servicio de Checkout agote su timeout, incluso cuando ningún servicio está completamente caído.
Este tipo de fallos no se manifiesta como una caída total, sino como degradaciones progresivas, timeouts intermitentes o errores parciales que impactan directamente en conversión y experiencia del cliente.
Por eso, la fiabilidad de microservicios en e-commerce no depende de que cada servicio funcione de forma aislada, sino de que todo el conjunto funcione correctamente bajo carga real, con dependencias internas y externas, y en escenarios no ideales.
Principales puntos de falla en arquitecturas distribuidas
Antes de definir un framework, es clave entender dónde suelen fallar los microservicios en retail digital.
Latencia acumulada
Cada llamada entre servicios añade latencia. Un flujo puede ser funcional pero demasiado lento para el usuario.
Dependencias críticas ocultas
Servicios aparentemente secundarios pueden convertirse en cuellos de botella durante picos de tráfico.
Timeouts mal configurados
Timeouts demasiado altos bloquean recursos; demasiado bajos generan errores innecesarios.
Degradación silenciosa
Un servicio responde, pero de forma incorrecta o intermitente, sin disparar alertas claras.
Cascadas de fallos
La caída o lentitud de un servicio se propaga a otros, amplificando el impacto.
Mejorar la fiabilidad de microservicios implica atacar estos puntos de forma sistemática.
Un framework práctico para mejorar la fiabilidad de microservicios
A continuación, un framework paso a paso pensado específicamente para plataformas de e-commerce.
Paso 1: identificar journeys críticos de negocio
No todos los microservicios tienen el mismo impacto. El primer paso es identificar qué flujos generan valor real.
En e-commerce, los más comunes son:
La fiabilidad de microservicios debe evaluarse desde estos journeys, no desde servicios individuales.
Paso 2: mapear dependencias entre microservicios
Una vez definidos los flujos críticos, es necesario mapear qué servicios participan y cómo se relacionan.
Este mapa permite:
Sin este mapa, la fiabilidad de microservicios se gestiona a ciegas.
Paso 3: diseñar resiliencia, no solo disponibilidad
Alta disponibilidad no garantiza fiabilidad. En microservicios, la resiliencia es clave.
Buenas prácticas incluyen:
Por ejemplo, mostrar productos sin recomendaciones es preferible a romper todo el flujo.
Paso 4: configurar timeouts y límites conscientes del negocio
Timeouts genéricos son una causa común de fallos en e-commerce.
Cada servicio debe tener:
La fiabilidad de microservicios mejora cuando los límites están diseñados pensando en el journey completo.
Monitoreo synthetic para validar journeys críticos
Monitorear microservicios de forma individual no garantiza que el sistema funcione como un todo.
El monitoreo synthetic permite validar journeys completos simulando usuarios, como:
Es importante aclarar que esto no mide comportamiento real del usuario (eso corresponde a RUM), sino que valida el comportamiento real del sistema simulando usuarios de forma controlada.
Este enfoque detecta:
Para la fiabilidad de microservicios en e-commerce, este tipo de validación es indispensable.
Monitoreo de APIs entre microservicios
Los microservicios se comunican principalmente vía APIs. Si estas fallan, todo el sistema sufre.
El monitoreo debe cubrir:
Monitorear APIs de forma aislada no basta; deben correlacionarse dentro del flujo de negocio.
Cómo detectar degradación antes de que afecte conversiones
En e-commerce, la conversión suele caer antes de que el sistema se caiga.
Señales tempranas de degradación incluyen:
Aumento gradual en tiempos de respuesta
La monitorización debe enfocarse en la latencia P99 de servicios críticos (por ejemplo, Pago y Checkout) y alertar si supera un umbral de degradación (ej. +20 % en 5 minutos).
Errores esporádicos en checkout
Pagos que tardan más de lo normal
Reintentos invisibles para el usuario
La detección temprana de anomalías permite actuar antes de que estas degradaciones impacten métricas de negocio.
IA para la predicción de incidentes en e-commerce
La complejidad de la fiabilidad de microservicios hace que el análisis manual sea insuficiente.
La IA permite:
(ejemplo: correlacionar un pico de errores 503 en Inventario con una caída del throughput de la base de datos de Catálogo y un aumento de latencia P50 en Autenticación)
En e-commerce, donde los picos de tráfico son predecibles pero intensos, la predicción de incidentes marca la diferencia entre estabilidad y caída.
Integrar fiabilidad en el ciclo de despliegue
Un framework efectivo no se limita a producción. La fiabilidad de microservicios debe validarse antes y después de cada release.
Esto incluye:
Así se evita que cambios pequeños rompan journeys completos.
Checklist final de fiabilidad distribuida en e-commerce
Antes de un evento crítico, un equipo debería poder responder afirmativamente a estas preguntas:
Si alguna respuesta es “no”, la fiabilidad de microservicios está en riesgo.
Cómo UptimeBolt ayuda a mejorar la fiabilidad de microservicios
UptimeBolt está diseñado para abordar la fiabilidad de microservicios desde una perspectiva end-to-end y orientada a negocio.
La plataforma permite:
Este enfoque permite a los equipos anticiparse a fallos, proteger conversiones y operar con mayor confianza incluso bajo carga extrema.
Si quieres fortalecer la fiabilidad de microservicios en tu plataforma de e-commerce y evitar que un servicio rompa todo el flujo de ventas, regístrate y obtén una prueba gratuita.
Conclusión: la fiabilidad es el verdadero secreto del éxito en retail digital
En e-commerce, la tecnología no es solo un soporte del negocio: es el negocio. Una arquitectura de microservicios mal preparada puede escalar rápido, pero también fallar rápido cuando más importa.
Aplicar un framework práctico para mejorar la fiabilidad de microservicios permite detectar riesgos antes de que impacten conversiones, anticiparse a incidentes y ofrecer experiencias estables incluso en condiciones extremas.
En retail digital, el éxito no lo define quién lanza más rápido, sino quién se mantiene confiable cuando todos los usuarios llegan al mismo tiempo.