En 2026, el costo promedio del downtime para una empresa puede superar los USD 300.000 por hora, y en sectores como e-commerce, fintech o servicios digitales críticos esa cifra puede escalar rápidamente a millones durante picos de tráfico.
Aun así, muchas organizaciones siguen abordando el downtime como un problema puramente técnico, en lugar de tratarlo como lo que realmente es: una fuente directa de pérdidas financieras, incumplimientos de SLA, desgaste de los equipos operativos y erosión de la confianza de clientes y usuarios.
Reducir el downtime se ha convertido, por tanto, en una prioridad estratégica, no solo de TI, sino del negocio en su conjunto. El reto ya no es únicamente reaccionar más rápido cuando algo falla, sino prevenir fallos antes de que impacten en ingresos, reputación y continuidad operativa.
Este artículo ofrece una guía práctica y accionable para reducir el downtime y su coste, combinando estrategias técnicas, operativas y organizacionales. Veremos por qué el downtime sigue ocurriendo incluso en entornos bien monitoreados, cómo prevenirlo con inteligencia artificial, cómo acortar el MTTR y cómo traducir todo esto en ahorro real para el negocio.
Cuando un sistema cae, el impacto no se limita al tiempo que el servicio estuvo indisponible. Reducir downtime implica entender que el costo real se acumula en múltiples frentes:
- Ventas perdidas durante la caída
- Usuarios que abandonan el servicio y no regresan
- Penalizaciones por incumplimiento de SLAs
- Saturación de equipos de soporte y operaciones
- Daño a la reputación de la marca
En muchos casos, el mayor impacto ocurre después de que el sistema vuelve a estar operativo. Por eso, reducir downtime no es solo una tarea técnica, sino una decisión de negocio.
Por ejemplo, el tiempo de rollback de bases de datos, la reconstrucción de caches o los esfuerzos para cumplir con notificaciones regulatorias (GDPR, compliance) consumen horas adicionales y generan costes indirectos muy elevados.
Uno de los mayores mitos es pensar que tener “buen monitoreo” es suficiente para evitar caídas. En la práctica, muchas organizaciones cuentan con múltiples herramientas y aun así sufren downtime recurrente.
Algunas razones comunes:
Detecta problemas cuando ya son visibles para el usuario. En ese punto, el downtime ya ocurrió.
No se adaptan a cambios de carga, estacionalidad o contexto, por lo que no detectan degradaciones tempranas.
Las alertas llegan aisladas, sin contexto, dificultando el diagnóstico rápido.
APIs externas, colas, jobs internos o microservicios pueden fallar sin generar alertas claras.
Esto es común en arquitecturas de microservicios o serverless, donde una falla silenciosa en un sidecar o un aumento de latencia en un servicio de terceros (por ejemplo, un proveedor de pagos o CDN) degrada la experiencia antes de que el monitor principal reaccione.
El primer paso para reducir downtime es cambiar el enfoque operativo. En lugar de preguntarse “¿qué hacemos cuando caemos?”, la pregunta correcta es:
¿Cómo evitamos llegar a una caída?
Esto implica:
- Detectar problemas antes de que se conviertan en incidentes
- Priorizar degradaciones, no solo fallos totales
- Entender patrones de comportamiento del sistema
- Anticipar escenarios de riesgo
Aquí es donde la inteligencia artificial y el monitoreo predictivo se vuelven fundamentales.
La mayoría de los incidentes no ocurren de forma repentina. Antes del downtime, suelen aparecer señales tempranas que pasan desapercibidas.
La IA permite identificar comportamientos inusuales como:
- Aumentos progresivos de latencia
- Errores intermitentes
- Cambios sutiles en tiempos de respuesta
- Patrones de tráfico inesperados
Detectar estas anomalías permite actuar cuando aún hay margen de maniobra, reduciendo o incluso evitando el downtime.
Por ejemplo, la IA puede detectar que el percentil 95 de latencia de una API de login pasó de 200 ms a 450 ms en 10 minutos, aunque la latencia media siga “verde”. Este es un indicador de degradación que un umbral estático omitiría.
Al analizar datos históricos y señales en tiempo real, la IA puede anticipar fallas probables. Esto permite preparar respuestas antes de que el problema impacte al usuario.
Reducir downtime deja de ser una carrera contra el reloj y se convierte en un proceso planificado.
Cuando el downtime ocurre, el tiempo de recuperación es crítico. Reducir downtime no solo significa evitar caídas, sino recuperarse más rápido cuando suceden.
Aquí entra en juego la automatización del diagnóstico:
La IA agrupa métricas, alertas y anomalías relacionadas, evitando que los equipos pierdan tiempo analizando señales aisladas.
En lugar de investigar manualmente, los equipos reciben hipótesis claras sobre la causa raíz más probable.
Saber qué cambió, qué servicio se degradó primero y qué dependencias están involucradas acelera la resolución.
Todo esto reduce el MTTR y, por lo tanto, reduce el downtime acumulado.
Reducir downtime también implica diseñar sistemas que fallen mejor.
Algunas prácticas esenciales:
No basta con duplicar recursos. La redundancia debe probarse y monitorearse regularmente.
Bases de datos, colas o servicios críticos no deben depender de un solo componente.
Evitan que fallas en un servicio se propaguen al resto del sistema.
Escalar automáticamente sin límites puede generar nuevos problemas. El escalado debe ser monitoreado y contextual.
Estas prácticas reducen la probabilidad y el impacto del downtime, pero deben combinarse con monitoreo avanzado para ser efectivas.
No solo diseñes para fallar mejor: pruébalo activamente. Introduce fallas controladas en producción para validar que los timeouts, circuit breakers y la redundancia funcionan como se espera.
Un enemigo silencioso al intentar reducir downtime es la fatiga por alertas. Cuando todo genera alertas, nada es realmente urgente.
Reducir downtime requiere:
- Menos alertas, pero más relevantes
- Alertas basadas en impacto real
- Priorización automática
- Contexto claro para actuar rápido
La inteligencia artificial se apoya en baselines dinámicos y correlación multi-signal (métricas, trazas e incidentes) para reducir la fatiga por alertas, presentando una única alerta accionable en lugar de decenas de señales aisladas.
Para reducir downtime de forma efectiva, es clave cuantificar su impacto.
Costo por minuto = ventas promedio por minuto × tasa de abandono adicional
Costo = churn incremental + soporte + impacto en renovaciones
Costo = transacciones fallidas + penalizaciones regulatorias + pérdida de confianza
Costo = incumplimiento de SLA + créditos + riesgo contractual
Poner números reales sobre la mesa ayuda a justificar inversiones en prevención y monitoreo avanzado.
No todo downtime puede eliminarse, pero mucho sí puede prevenirse.
El downtime prevenible suele estar relacionado con:
- Falta de detección temprana
- Cambios no validados
- Configuraciones incorrectas
- Dependencias mal monitoreadas
Reducir downtime significa enfocarse primero en este tipo de fallos, que representan una gran parte del impacto total.
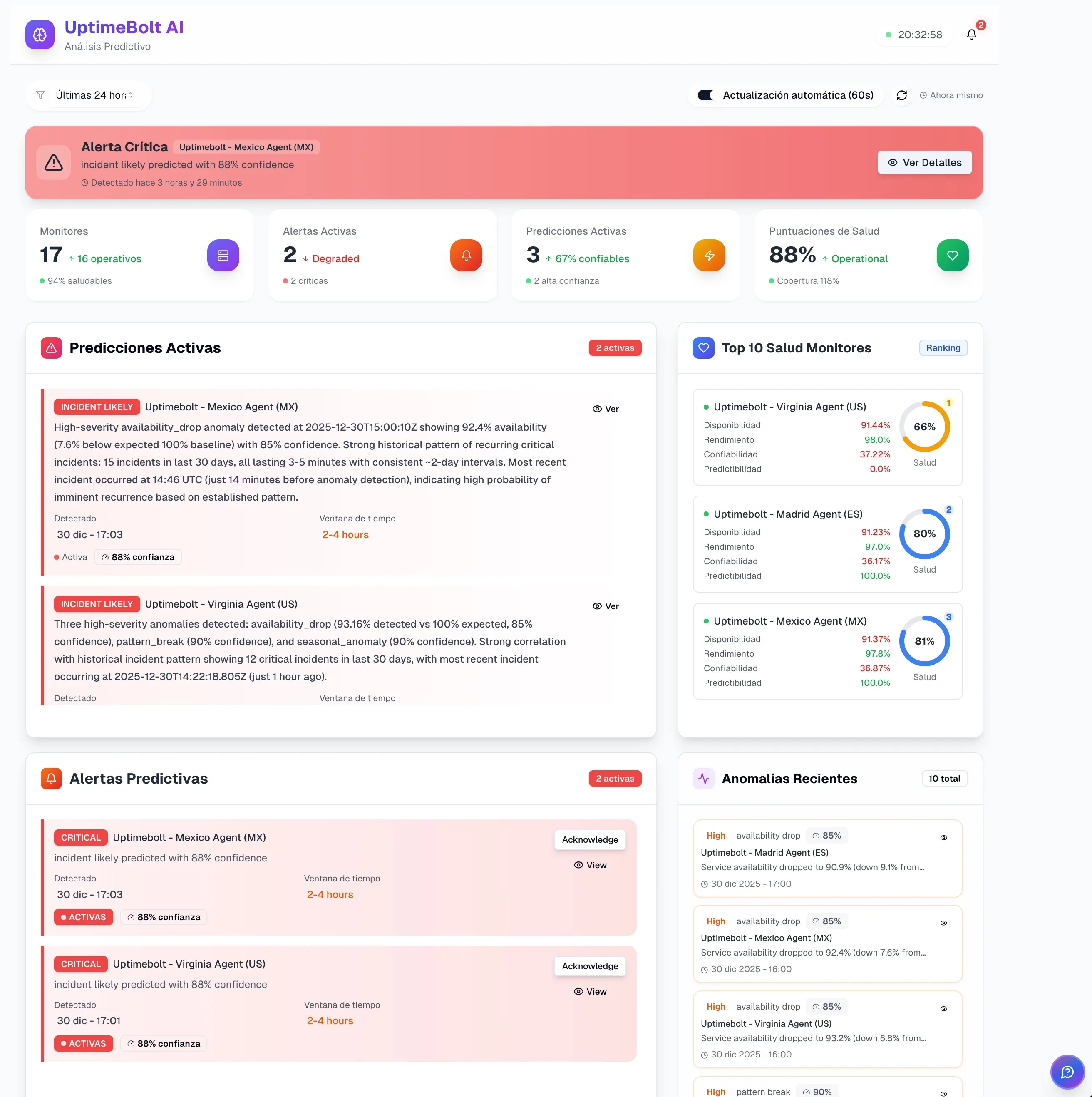
UptimeBolt está diseñado para ayudar a las organizaciones a reducir downtime y su coste mediante un enfoque preventivo y basado en datos.
La plataforma combina:
- Detección de anomalías impulsada por IA
- Predicción de incidentes
- Monitoreo synthetic de flujos críticos
- Monitoreo de APIs y dependencias
- Correlación automática de eventos
- Alertas inteligentes con contexto accionable
Esto permite actuar antes de que el downtime ocurra o reducir drásticamente su duración cuando es inevitable.
El downtime no es un accidente inevitable ni un simple problema técnico. Es una consecuencia directa de cómo se diseñan, monitorean y operan los sistemas.
Reducir downtime implica cambiar la mentalidad, invertir en prevención, automatizar el diagnóstico y apoyarse en inteligencia artificial para tomar mejores decisiones. El resultado no solo es mayor estabilidad técnica, sino menores costos operativos, mejores SLAs y una experiencia superior para los usuarios.
En un mundo digital donde cada minuto cuenta, reducir downtime no es una optimización: es una ventaja competitiva.
Si quieres empezar a reducir downtime de forma medible y proteger tus ingresos, regístrate y obtén una prueba gratuita.
En 2026, el costo promedio del downtime para una empresa puede superar los USD 300.000 por hora, y en sectores como e-commerce, fintech o servicios digitales críticos esa cifra puede escalar rápidamente a millones durante picos de tráfico.
Aun así, muchas organizaciones siguen abordando el downtime como un problema puramente técnico, en lugar de tratarlo como lo que realmente es: una fuente directa de pérdidas financieras, incumplimientos de SLA, desgaste de los equipos operativos y erosión de la confianza de clientes y usuarios.
Reducir el downtime se ha convertido, por tanto, en una prioridad estratégica, no solo de TI, sino del negocio en su conjunto. El reto ya no es únicamente reaccionar más rápido cuando algo falla, sino prevenir fallos antes de que impacten en ingresos, reputación y continuidad operativa.
Este artículo ofrece una guía práctica y accionable para reducir el downtime y su coste, combinando estrategias técnicas, operativas y organizacionales. Veremos por qué el downtime sigue ocurriendo incluso en entornos bien monitoreados, cómo prevenirlo con inteligencia artificial, cómo acortar el MTTR y cómo traducir todo esto en ahorro real para el negocio.
Introducción: el costo oculto (y real) del downtime
Cuando un sistema cae, el impacto no se limita al tiempo que el servicio estuvo indisponible. Reducir downtime implica entender que el costo real se acumula en múltiples frentes:
En muchos casos, el mayor impacto ocurre después de que el sistema vuelve a estar operativo. Por eso, reducir downtime no es solo una tarea técnica, sino una decisión de negocio.
Por ejemplo, el tiempo de rollback de bases de datos, la reconstrucción de caches o los esfuerzos para cumplir con notificaciones regulatorias (GDPR, compliance) consumen horas adicionales y generan costes indirectos muy elevados.
Por qué ocurre el downtime incluso con buen monitoreo
Uno de los mayores mitos es pensar que tener “buen monitoreo” es suficiente para evitar caídas. En la práctica, muchas organizaciones cuentan con múltiples herramientas y aun así sufren downtime recurrente.
Algunas razones comunes:
Monitoreo reactivo
Detecta problemas cuando ya son visibles para el usuario. En ese punto, el downtime ya ocurrió.
Umbrales estáticos
No se adaptan a cambios de carga, estacionalidad o contexto, por lo que no detectan degradaciones tempranas.
Falta de correlación
Las alertas llegan aisladas, sin contexto, dificultando el diagnóstico rápido.
Dependencias invisibles
APIs externas, colas, jobs internos o microservicios pueden fallar sin generar alertas claras.
Esto es común en arquitecturas de microservicios o serverless, donde una falla silenciosa en un sidecar o un aumento de latencia en un servicio de terceros (por ejemplo, un proveedor de pagos o CDN) degrada la experiencia antes de que el monitor principal reaccione.
Cambiar la mentalidad: de reaccionar a prevenir
El primer paso para reducir downtime es cambiar el enfoque operativo. En lugar de preguntarse “¿qué hacemos cuando caemos?”, la pregunta correcta es:
¿Cómo evitamos llegar a una caída?
Esto implica:
Aquí es donde la inteligencia artificial y el monitoreo predictivo se vuelven fundamentales.
Cómo reducir downtime mediante predicción y anomalías
La mayoría de los incidentes no ocurren de forma repentina. Antes del downtime, suelen aparecer señales tempranas que pasan desapercibidas.
Detección temprana de anomalías
La IA permite identificar comportamientos inusuales como:
Detectar estas anomalías permite actuar cuando aún hay margen de maniobra, reduciendo o incluso evitando el downtime.
Por ejemplo, la IA puede detectar que el percentil 95 de latencia de una API de login pasó de 200 ms a 450 ms en 10 minutos, aunque la latencia media siga “verde”. Este es un indicador de degradación que un umbral estático omitiría.
Predicción de incidentes
Al analizar datos históricos y señales en tiempo real, la IA puede anticipar fallas probables. Esto permite preparar respuestas antes de que el problema impacte al usuario.
Reducir downtime deja de ser una carrera contra el reloj y se convierte en un proceso planificado.
Automatización del diagnóstico para acortar MTTR
Cuando el downtime ocurre, el tiempo de recuperación es crítico. Reducir downtime no solo significa evitar caídas, sino recuperarse más rápido cuando suceden.
Aquí entra en juego la automatización del diagnóstico:
Correlación automática de eventos
La IA agrupa métricas, alertas y anomalías relacionadas, evitando que los equipos pierdan tiempo analizando señales aisladas.
Root Cause Analysis asistido
En lugar de investigar manualmente, los equipos reciben hipótesis claras sobre la causa raíz más probable.
Contexto inmediato
Saber qué cambió, qué servicio se degradó primero y qué dependencias están involucradas acelera la resolución.
Todo esto reduce el MTTR y, por lo tanto, reduce el downtime acumulado.
Redundancia y resiliencia: prácticas clave
Reducir downtime también implica diseñar sistemas que fallen mejor.
Algunas prácticas esenciales:
Redundancia inteligente
No basta con duplicar recursos. La redundancia debe probarse y monitorearse regularmente.
Eliminación de single points of failure
Bases de datos, colas o servicios críticos no deben depender de un solo componente.
Timeouts y circuit breakers
Evitan que fallas en un servicio se propaguen al resto del sistema.
Escalado controlado
Escalar automáticamente sin límites puede generar nuevos problemas. El escalado debe ser monitoreado y contextual.
Estas prácticas reducen la probabilidad y el impacto del downtime, pero deben combinarse con monitoreo avanzado para ser efectivas.
Ingeniería del Caos (Chaos Engineering)
No solo diseñes para fallar mejor: pruébalo activamente. Introduce fallas controladas en producción para validar que los timeouts, circuit breakers y la redundancia funcionan como se espera.
Alertas inteligentes para evitar saturación (alert fatigue)
Un enemigo silencioso al intentar reducir downtime es la fatiga por alertas. Cuando todo genera alertas, nada es realmente urgente.
Reducir downtime requiere:
La inteligencia artificial se apoya en baselines dinámicos y correlación multi-signal (métricas, trazas e incidentes) para reducir la fatiga por alertas, presentando una única alerta accionable en lugar de decenas de señales aisladas.
Cómo calcular el costo del downtime por industria
Para reducir downtime de forma efectiva, es clave cuantificar su impacto.
E-commerce
Costo por minuto = ventas promedio por minuto × tasa de abandono adicional
SaaS
Costo = churn incremental + soporte + impacto en renovaciones
Fintech
Costo = transacciones fallidas + penalizaciones regulatorias + pérdida de confianza
Plataformas B2B
Costo = incumplimiento de SLA + créditos + riesgo contractual
Poner números reales sobre la mesa ayuda a justificar inversiones en prevención y monitoreo avanzado.
Downtime prevenible vs downtime inevitable
No todo downtime puede eliminarse, pero mucho sí puede prevenirse.
El downtime prevenible suele estar relacionado con:
Reducir downtime significa enfocarse primero en este tipo de fallos, que representan una gran parte del impacto total.
Cómo UptimeBolt reduce downtime con IA predictiva
UptimeBolt está diseñado para ayudar a las organizaciones a reducir downtime y su coste mediante un enfoque preventivo y basado en datos.
La plataforma combina:
Esto permite actuar antes de que el downtime ocurra o reducir drásticamente su duración cuando es inevitable.
Conclusión: reducir downtime es reducir costos operativos
El downtime no es un accidente inevitable ni un simple problema técnico. Es una consecuencia directa de cómo se diseñan, monitorean y operan los sistemas.
Reducir downtime implica cambiar la mentalidad, invertir en prevención, automatizar el diagnóstico y apoyarse en inteligencia artificial para tomar mejores decisiones. El resultado no solo es mayor estabilidad técnica, sino menores costos operativos, mejores SLAs y una experiencia superior para los usuarios.
En un mundo digital donde cada minuto cuenta, reducir downtime no es una optimización: es una ventaja competitiva.
Si quieres empezar a reducir downtime de forma medible y proteger tus ingresos, regístrate y obtén una prueba gratuita.