Operar una aplicación en una sola nube ya implica complejidad. Operarla en varias cambia por completo las reglas del juego. Cada vez más empresas distribuyen componentes entre AWS, GCP, Azure u otros proveedores por razones perfectamente válidas: resiliencia, costos, compliance, proximidad geográfica, especialización de servicios o decisiones históricas de arquitectura.
El resultado es una realidad que muchos equipos conocen demasiado bien: una plataforma que ya no vive en un solo entorno, sino en una malla de servicios, regiones, APIs y dependencias repartidas entre múltiples clouds.
El problema no es únicamente que existan más componentes. El problema es que, cuanto más distribuido está el sistema, más difícil se vuelve entender su comportamiento como un todo.
Un frontend puede vivir en AWS, una API crítica en GCP, una capa analítica en Azure y una pasarela externa de pagos fuera de todo ese perímetro. En ese escenario, el fallo rara vez ocurre “dentro” de un solo componente. Muchas veces ocurre en la interacción entre ellos.
Ese matiz es decisivo.
En entornos multicloud, la fiabilidad no depende solo de que cada pieza individual esté sana. Depende de que las relaciones entre piezas sigan siendo rápidas, consistentes y estables bajo carga.
Una llamada entre servicios que cruza clouds, una autenticación que pasa por un proveedor externo, una diferencia de latencia entre regiones o un timeout intermitente en una dependencia compartida puede convertirse en un incidente visible sin que ningún dashboard aislado lo muestre con claridad.
Por eso el monitoreo multicloud no puede limitarse a ver componentes de forma separada. Necesita observar comportamiento global.
Y ahí es donde el monitoreo predictivo se vuelve especialmente valioso: permite detectar anomalías y degradaciones antes de que se conviertan en fallas visibles para el usuario.
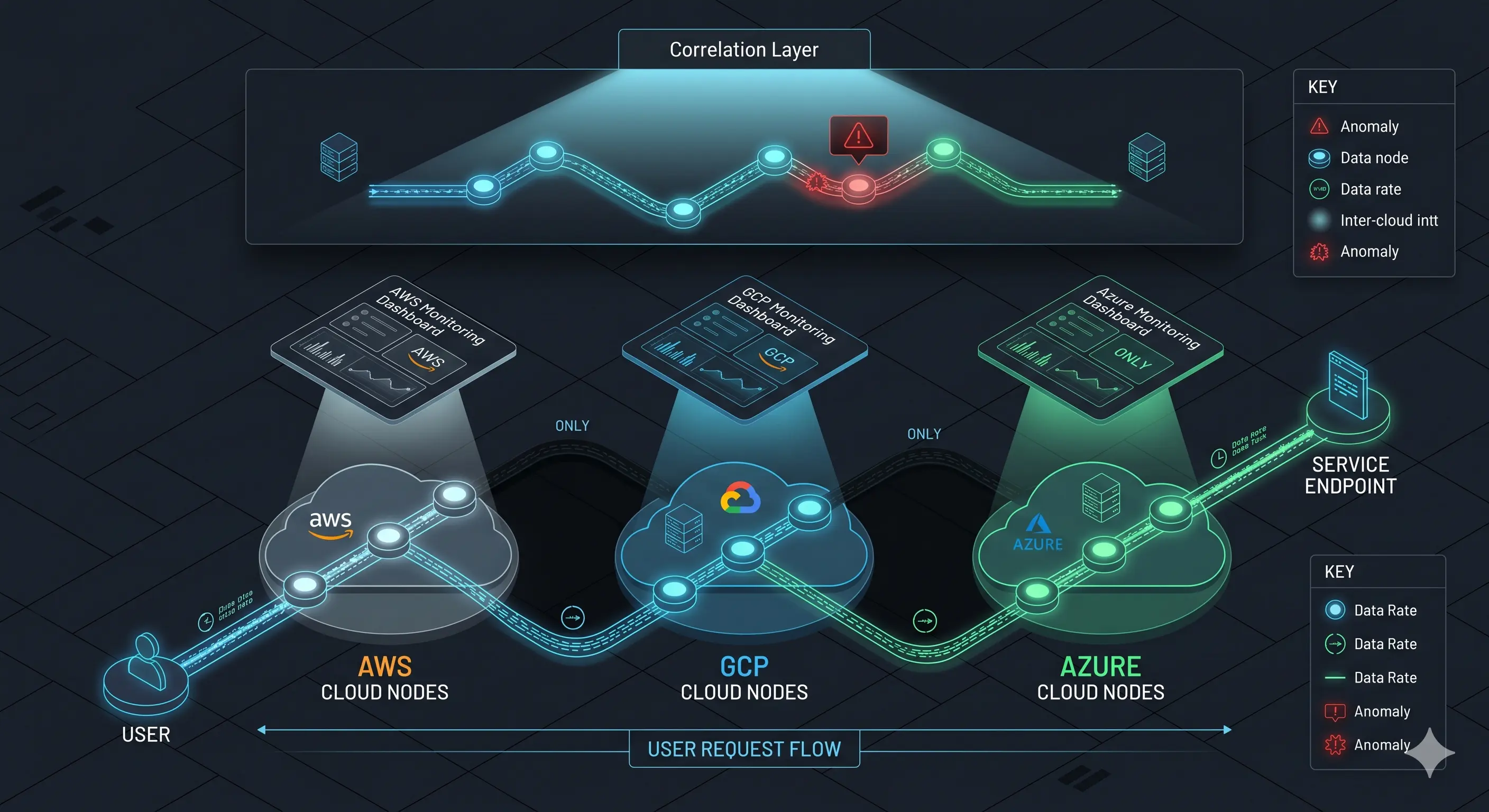
La mayoría de las herramientas tradicionales fueron pensadas para operar dentro de un perímetro relativamente homogéneo. Aunque hoy muchas ofrecen capacidades más amplias, la lógica subyacente de muchos equipos sigue siendo trabajar por silos.
- AWS se monitorea con herramientas y dashboards de AWS
- GCP se observa desde el stack de GCP
- Azure se revisa con sus propias métricas y eventos
- Las dependencias externas se tratan como algo separado
- Los flujos reales del usuario quedan repartidos entre varias consolas
Ese enfoque tiene una limitación estructural: no hay una visión unificada del sistema.
Y cuando el problema nace en la interacción entre clouds, esa fragmentación se vuelve muy costosa. Cada plataforma muestra “su parte” del incidente, pero nadie ve fácilmente la historia completa.
Un equipo puede observar que una API en AWS responde más lento. Otro detecta timeouts en un servicio en GCP. Un tercero ve un aumento de retries desde el frontend. Pero si nadie correlaciona esas señales como parte de un mismo patrón, el diagnóstico llega tarde.
El resultado es conocido:
- Incidentes difíciles de diagnosticar
- Mayor tiempo de investigación
- Más war rooms
- Más dependencia de conocimiento tribal
- Más riesgo de que el usuario perciba el problema antes que el equipo
El monitoreo tradicional basado en silos también tiende a apoyarse en umbrales simples. Eso funciona para detectar caídas claras o saturaciones extremas, pero falla cuando el problema es más sutil:
- una degradación progresiva entre servicios
- una latencia cross-cloud que empeora solo bajo ciertos picos
- un incremento intermitente en timeouts que todavía no cruza un umbral fijo
En multicloud, esa sutileza es exactamente donde se esconden los problemas más costosos.
El monitoreo predictivo aporta algo que el monitoreo tradicional rara vez logra por sí solo: capacidad de anticipación sobre el comportamiento global del sistema, no solo sobre el estado de cada componente aislado.
Eso cambia radicalmente la lógica operativa.
En lugar de preguntar:
“¿Qué servicio cruzó el umbral?”
El monitoreo predictivo pregunta:
“¿Qué patrón está cambiando y qué relación tiene con el resto del sistema?”
Esa diferencia importa mucho en multicloud, porque muchos incidentes no comienzan con una caída evidente, sino con pequeñas desviaciones en las interacciones.
Puede identificar cuando dos servicios que normalmente se comunican dentro de cierto patrón de latencia empiezan a desviarse, aunque ninguno esté formalmente “down”.
Puede detectar correlaciones entre señales que viven en clouds distintas.
Por ejemplo:
- aumento de tiempo de respuesta en un servicio en GCP
- coincidiendo con crecimiento de retries desde un frontend en AWS
Puede marcar desviaciones tempranas antes de que el usuario note el fallo:
- variabilidad inusual en latencia
- un p95 que se separa de su baseline
- errores intermitentes
- caída progresiva en el éxito de un flujo crítico
Este es el cambio clave:
Pasamos de monitorear componentes a monitorear comportamiento global.
Y en arquitecturas distribuidas, ese comportamiento global es el que realmente determina si el sistema está sano o no.
Cuando un servicio en AWS depende de otro en GCP o Azure, la latencia entre ambos no siempre es estable.
Puede cambiar por:
- saturación
- cambios de red
- presión regional
- comportamiento inesperado bajo carga
Ejemplo típico:
Una API en AWS llama a un servicio de cálculo de riesgo en GCP. Bajo tráfico normal, el tiempo total es aceptable. Durante un pico, esa interacción empieza a demorarse 2x o 3x, generando una cascada de degradación.
Los timeouts suelen ser uno de los primeros síntomas de una interacción multicloud inestable.
A veces no son masivos al principio, sino intermitentes y difíciles de diagnosticar.
En muchos entornos multicloud existen dependencias críticas externas:
- pagos
- identidad
- validaciones
- fraude
- logística
- mensajería
Una pequeña degradación en ellas puede afectar solo ciertos caminos del sistema, pero con impacto real.
Dos servicios pueden seguir respondiendo, pero con diferencias sutiles de comportamiento según región, cloud o camino de ejecución.
Eso genera errores que no siempre aparecen como indisponibilidad, sino como:
- respuestas incompletas
- latencias anómalas
- resultados inconsistentes
Un patrón muy común en multicloud es que el problema no afecta a todo el sistema, sino a una interacción específica entre:
- una región y otra
- un servicio desplegado en un cloud y otro proveedor distinto
Este es quizá el caso más peligroso.
Ninguna métrica cruza un umbral drástico, pero el sistema va entrando en una zona de riesgo:
- más latencia
- más jitter
- más retries
- más p99
Un monitoreo basado solo en reglas fijas suele llegar tarde. Uno predictivo puede ver la tendencia.
Imaginemos una arquitectura bastante plausible:
- Frontend de compra desplegado en AWS
- Motor de pagos operando en GCP
- Base de datos de órdenes también en AWS
- Servicio externo de validación antifraude fuera del perímetro de ambos proveedores
Durante un pico de tráfico, el comportamiento empieza a cambiar.
El frontend sigue cargando.
La API principal sigue respondiendo.
No hay una caída total.
Pero el flujo de pago comienza a mostrar lo siguiente:
- La latencia entre frontend y servicio de pagos aumenta 3x
- Aparecen timeouts intermitentes en la validación antifraude
- El p95 del paso “Confirmar pago” sube de 1.1 s a 3.4 s
- El éxito del checkout cae lentamente, pero no de forma dramática al inicio
- AWS: frontend y base de datos “sanos”
- GCP: servicio de pagos bajo más carga, pero todavía disponible
- Dependencia externa: visibilidad limitada
Resultado:
Nadie detecta un problema claro al inicio.
- aumento anómalo de latencia cross-cloud
- degradación funcional del flujo de pago
- señales consistentes con un incidente en formación
Esa diferencia entre:
“No vemos un problema claro”
y
“Vemos un patrón anómalo en la interacción”
es precisamente la ventaja operativa.
Esto se traduce en alertas basadas en:
- SLOs de latencia end-to-end
- detección de outliers
- degradación funcional de journeys críticos
y no solamente en CPU o uso de disco.
El monitoreo multicloud no es solo una cuestión de fiabilidad técnica. También tiene impacto financiero y arquitectónico.
Uno de los costos menos visibles está en el egress entre clouds.
Cuando servicios distribuidos entre proveedores intercambian grandes volúmenes de datos o incrementan reintentos por degradación, el costo de transferencia puede crecer rápidamente.
Considerando que el egress puede costar alrededor de:
:contentReference[oaicite:0]{index=0}
una degradación funcional puede multiplicar rápidamente este coste por 5x o 10x debido a:
- reintentos innecesarios
- re-sincronizaciones de datos
- tráfico redundante
Además, los fallos y retries tienen un costo doble:
- aumentan consumo de recursos
- prolongan la duración del problema
- generan más carga en servicios ya tensionados
- disparan costos indirectos de infraestructura
A eso se suman otros costos ocultos:
- más tiempo de investigación
- equipos más tiempo en war rooms
- pérdida de productividad operativa
- impacto en soporte
- daño reputacional
El insight importante para dirección es este:
Los problemas técnicos en entornos multicloud se convierten muy rápido en costos operativos reales.
Por eso la visibilidad no es un lujo. Es una herramienta de eficiencia.
Aquí existe una decisión arquitectónica importante.
Las herramientas nativas de cada cloud suelen ofrecer ventajas claras:
- integración profunda con servicios propios
- métricas detalladas
- acceso natural a eventos
- diagnósticos muy buenos dentro de ese entorno
Pero su limitación es evidente:
La visión suele ser más fuerte dentro del cloud que fuera de él.
Cuando el sistema depende de varias nubes, las herramientas cloud-native pueden dejar puntos ciegos entre proveedores.
Cada una te muestra muy bien “su mundo”, pero no necesariamente las interacciones que conectan ese mundo con el resto.
Las soluciones agnósticas sacrifican parte de profundidad nativa a cambio de algo muy valioso:
visibilidad cross-cloud.
Sus fortalezas suelen ser:
- observar comportamiento global
- monitorear journeys E2E
- reducir dependencia de proveedor
- facilitar operación híbrida y multicloud
Su limitación es que no siempre alcanzan el mismo detalle interno de una herramienta profundamente integrada con un único proveedor.
Por eso, para un CTO, la decisión real no es blanco o negro.
Es una decisión entre:
- profundidad local
- visibilidad global
Y en sistemas multicloud, esta segunda suele ser mucho más importante de lo que parece.
UptimeBolt no depende de integraciones nativas con cada cloud para aportar valor en entornos multicloud.
No intenta convertirse en la consola profunda de AWS, GCP o Azure.
Su enfoque es distinto.
Monitorea:
- endpoints
- APIs
- flujos E2E
- comportamiento real del sistema
- degradaciones funcionales
- señales anómalas en la interacción entre servicios
Este enfoque centrado en comportamiento E2E y synthetic monitoring le permite operar como una capa superior de visibilidad global, agnóstica al proveedor cloud.
Ese es su diferencial real:
Visibilidad desde el comportamiento del sistema, no solo desde la infraestructura.
En arquitecturas distribuidas, eso permite detectar problemas que una vista puramente cloud-native puede fragmentar:
- degradaciones entre servicios
- fallos en journeys críticos
- comportamiento anómalo en endpoints
- señales previas a incidentes cross-cloud
El beneficio más importante del monitoreo predictivo en multicloud no es solo detectar más cosas.
Es reducir incertidumbre operativa.
Lo hace porque:
- detecta degradaciones antes del impacto visible
- identifica dependencias críticas en riesgo
- correlaciona incidentes cross-cloud
- reduce tiempo de investigación
- baja el MTTD
- reduce el MTTR
El resultado práctico suele reflejarse en tres dimensiones.
Detectar antes permite actuar antes.
Eso reduce tanto incidentes completos como ventanas de degradación funcional.
Cuando el problema se contiene antes de que el flujo crítico colapse, el usuario sufre menos impacto.
No elimina la complejidad del multicloud, pero sí reduce el nivel de incertidumbre con el que el equipo opera.
Y eso es fundamental:
En multicloud, no siempre se puede simplificar la arquitectura. Pero sí se puede operar con mejores señales.
Cuantas más nubes, más interacciones.
Y cuantas más interacciones, más puntos potenciales de falla.
Ese es el verdadero reto del monitoreo multicloud.
No basta con tener más dashboards ni más datos. De hecho, más datos sin contexto pueden empeorar el problema.
Lo que realmente importa es poder entender el comportamiento global del sistema y anticipar cuándo una interacción empieza a degradarse.
Ese es el mensaje clave:
En entornos multicloud, la fiabilidad depende de entender las interacciones y anticipar los problemas.
Más clouds significan más riesgo si la visibilidad sigue fragmentada.
Más señales no significan más control si nadie correlaciona lo importante.
Y más herramientas no significan más resiliencia si todas miran solo una parte del sistema.
Por eso el monitoreo predictivo se vuelve una capa crítica en infraestructuras distribuidas.
No porque reemplace todo lo demás, sino porque ayuda a ver antes lo que el monitoreo tradicional suele entender demasiado tarde.
El rol del monitoreo predictivo en infraestructuras multicloud
Operar una aplicación en una sola nube ya implica complejidad. Operarla en varias cambia por completo las reglas del juego. Cada vez más empresas distribuyen componentes entre AWS, GCP, Azure u otros proveedores por razones perfectamente válidas: resiliencia, costos, compliance, proximidad geográfica, especialización de servicios o decisiones históricas de arquitectura.
El resultado es una realidad que muchos equipos conocen demasiado bien: una plataforma que ya no vive en un solo entorno, sino en una malla de servicios, regiones, APIs y dependencias repartidas entre múltiples clouds.
El reto real: la falla ocurre en la interacción, no en el componente
El problema no es únicamente que existan más componentes. El problema es que, cuanto más distribuido está el sistema, más difícil se vuelve entender su comportamiento como un todo.
Un frontend puede vivir en AWS, una API crítica en GCP, una capa analítica en Azure y una pasarela externa de pagos fuera de todo ese perímetro. En ese escenario, el fallo rara vez ocurre “dentro” de un solo componente. Muchas veces ocurre en la interacción entre ellos.
Ese matiz es decisivo.
En entornos multicloud, la fiabilidad no depende solo de que cada pieza individual esté sana. Depende de que las relaciones entre piezas sigan siendo rápidas, consistentes y estables bajo carga.
Una llamada entre servicios que cruza clouds, una autenticación que pasa por un proveedor externo, una diferencia de latencia entre regiones o un timeout intermitente en una dependencia compartida puede convertirse en un incidente visible sin que ningún dashboard aislado lo muestre con claridad.
Por eso el monitoreo multicloud no puede limitarse a ver componentes de forma separada. Necesita observar comportamiento global.
Y ahí es donde el monitoreo predictivo se vuelve especialmente valioso: permite detectar anomalías y degradaciones antes de que se conviertan en fallas visibles para el usuario.
Por qué el monitoreo tradicional falla en entornos multicloud
La mayoría de las herramientas tradicionales fueron pensadas para operar dentro de un perímetro relativamente homogéneo. Aunque hoy muchas ofrecen capacidades más amplias, la lógica subyacente de muchos equipos sigue siendo trabajar por silos.
El problema de la fragmentación por silos
Ese enfoque tiene una limitación estructural: no hay una visión unificada del sistema.
Y cuando el problema nace en la interacción entre clouds, esa fragmentación se vuelve muy costosa. Cada plataforma muestra “su parte” del incidente, pero nadie ve fácilmente la historia completa.
Un equipo puede observar que una API en AWS responde más lento. Otro detecta timeouts en un servicio en GCP. Un tercero ve un aumento de retries desde el frontend. Pero si nadie correlaciona esas señales como parte de un mismo patrón, el diagnóstico llega tarde.
El resultado es conocido:
El monitoreo tradicional basado en silos también tiende a apoyarse en umbrales simples. Eso funciona para detectar caídas claras o saturaciones extremas, pero falla cuando el problema es más sutil:
En multicloud, esa sutileza es exactamente donde se esconden los problemas más costosos.
Qué aporta el monitoreo predictivo en infraestructuras multicloud
El monitoreo predictivo aporta algo que el monitoreo tradicional rara vez logra por sí solo: capacidad de anticipación sobre el comportamiento global del sistema, no solo sobre el estado de cada componente aislado.
Eso cambia radicalmente la lógica operativa.
En lugar de preguntar:
El monitoreo predictivo pregunta:
Esa diferencia importa mucho en multicloud, porque muchos incidentes no comienzan con una caída evidente, sino con pequeñas desviaciones en las interacciones.
Detección de anomalías entre servicios
Puede identificar cuando dos servicios que normalmente se comunican dentro de cierto patrón de latencia empiezan a desviarse, aunque ninguno esté formalmente “down”.
Identificación de patrones cross-cloud
Puede detectar correlaciones entre señales que viven en clouds distintas.
Por ejemplo:
Anticipación de degradaciones
Puede marcar desviaciones tempranas antes de que el usuario note el fallo:
Este es el cambio clave:
Pasamos de monitorear componentes a monitorear comportamiento global.
Y en arquitecturas distribuidas, ese comportamiento global es el que realmente determina si el sistema está sano o no.
Señales típicas de problemas en entornos multicloud
Latencias inter-cloud
Cuando un servicio en AWS depende de otro en GCP o Azure, la latencia entre ambos no siempre es estable.
Puede cambiar por:
Ejemplo típico:
Una API en AWS llama a un servicio de cálculo de riesgo en GCP. Bajo tráfico normal, el tiempo total es aceptable. Durante un pico, esa interacción empieza a demorarse 2x o 3x, generando una cascada de degradación.
Timeouts entre servicios
Los timeouts suelen ser uno de los primeros síntomas de una interacción multicloud inestable.
A veces no son masivos al principio, sino intermitentes y difíciles de diagnosticar.
Dependencias externas inestables
En muchos entornos multicloud existen dependencias críticas externas:
Una pequeña degradación en ellas puede afectar solo ciertos caminos del sistema, pero con impacto real.
Inconsistencia en respuestas
Dos servicios pueden seguir respondiendo, pero con diferencias sutiles de comportamiento según región, cloud o camino de ejecución.
Eso genera errores que no siempre aparecen como indisponibilidad, sino como:
Diferencias entre regiones o clouds
Un patrón muy común en multicloud es que el problema no afecta a todo el sistema, sino a una interacción específica entre:
Degradación progresiva
Este es quizá el caso más peligroso.
Ninguna métrica cruza un umbral drástico, pero el sistema va entrando en una zona de riesgo:
Un monitoreo basado solo en reglas fijas suele llegar tarde. Uno predictivo puede ver la tendencia.
Ejemplo realista para entenderlo mejor
Imaginemos una arquitectura bastante plausible:
Durante un pico de tráfico, el comportamiento empieza a cambiar.
El frontend sigue cargando.
La API principal sigue respondiendo.
No hay una caída total.
Pero el flujo de pago comienza a mostrar lo siguiente:
Qué mostraría un monitoreo tradicional
Resultado:
Nadie detecta un problema claro al inicio.
Qué detectaría el monitoreo predictivo
Esa diferencia entre:
y
es precisamente la ventaja operativa.
Esto se traduce en alertas basadas en:
y no solamente en CPU o uso de disco.
Costos ocultos en multicloud: más allá del downtime
El monitoreo multicloud no es solo una cuestión de fiabilidad técnica. También tiene impacto financiero y arquitectónico.
Uno de los costos menos visibles está en el egress entre clouds.
Cuando servicios distribuidos entre proveedores intercambian grandes volúmenes de datos o incrementan reintentos por degradación, el costo de transferencia puede crecer rápidamente.
Considerando que el egress puede costar alrededor de:
:contentReference[oaicite:0]{index=0}
una degradación funcional puede multiplicar rápidamente este coste por 5x o 10x debido a:
Además, los fallos y retries tienen un costo doble:
A eso se suman otros costos ocultos:
El insight importante para dirección es este:
Por eso la visibilidad no es un lujo. Es una herramienta de eficiencia.
Cloud-native vs herramientas agnósticas
Aquí existe una decisión arquitectónica importante.
Herramientas cloud-native
Las herramientas nativas de cada cloud suelen ofrecer ventajas claras:
Pero su limitación es evidente:
La visión suele ser más fuerte dentro del cloud que fuera de él.
Cuando el sistema depende de varias nubes, las herramientas cloud-native pueden dejar puntos ciegos entre proveedores.
Cada una te muestra muy bien “su mundo”, pero no necesariamente las interacciones que conectan ese mundo con el resto.
Herramientas agnósticas
Las soluciones agnósticas sacrifican parte de profundidad nativa a cambio de algo muy valioso:
visibilidad cross-cloud.
Sus fortalezas suelen ser:
Su limitación es que no siempre alcanzan el mismo detalle interno de una herramienta profundamente integrada con un único proveedor.
Por eso, para un CTO, la decisión real no es blanco o negro.
Es una decisión entre:
Y en sistemas multicloud, esta segunda suele ser mucho más importante de lo que parece.
Cómo UptimeBolt encaja en entornos multicloud
UptimeBolt no depende de integraciones nativas con cada cloud para aportar valor en entornos multicloud.
No intenta convertirse en la consola profunda de AWS, GCP o Azure.
Su enfoque es distinto.
Monitorea:
Este enfoque centrado en comportamiento E2E y synthetic monitoring le permite operar como una capa superior de visibilidad global, agnóstica al proveedor cloud.
Ese es su diferencial real:
En arquitecturas distribuidas, eso permite detectar problemas que una vista puramente cloud-native puede fragmentar:
Cómo el monitoreo predictivo reduce riesgo en multicloud
El beneficio más importante del monitoreo predictivo en multicloud no es solo detectar más cosas.
Es reducir incertidumbre operativa.
Lo hace porque:
El resultado práctico suele reflejarse en tres dimensiones.
Menor downtime
Detectar antes permite actuar antes.
Eso reduce tanto incidentes completos como ventanas de degradación funcional.
Mejor experiencia de usuario
Cuando el problema se contiene antes de que el flujo crítico colapse, el usuario sufre menos impacto.
Mayor control operativo
No elimina la complejidad del multicloud, pero sí reduce el nivel de incertidumbre con el que el equipo opera.
Y eso es fundamental:
En multicloud, no siempre se puede simplificar la arquitectura. Pero sí se puede operar con mejores señales.
Conclusión
Cuantas más nubes, más interacciones.
Y cuantas más interacciones, más puntos potenciales de falla.
Ese es el verdadero reto del monitoreo multicloud.
No basta con tener más dashboards ni más datos. De hecho, más datos sin contexto pueden empeorar el problema.
Lo que realmente importa es poder entender el comportamiento global del sistema y anticipar cuándo una interacción empieza a degradarse.
Ese es el mensaje clave:
Más clouds significan más riesgo si la visibilidad sigue fragmentada.
Más señales no significan más control si nadie correlaciona lo importante.
Y más herramientas no significan más resiliencia si todas miran solo una parte del sistema.
Por eso el monitoreo predictivo se vuelve una capa crítica en infraestructuras distribuidas.
No porque reemplace todo lo demás, sino porque ayuda a ver antes lo que el monitoreo tradicional suele entender demasiado tarde.