Durante años, el monitoreo de sistemas se apoyó en un enfoque basado en reglas y alertamiento rígido por umbrales: definir métricas, fijar límites y generar alertas cuando algo los superaba.
Si la CPU pasaba del 80%, si la latencia promedio subía por encima de cierto valor o si el error rate se disparaba, el sistema avisaba.
Pero este modelo —centrado muchas veces en promedios y no en métricas más representativas como p95 o p99— empieza a fallar cuando se enfrenta a la variabilidad real de sistemas distribuidos.
Sigue teniendo valor, pero quedó corto frente a la complejidad de las arquitecturas modernas.
Hoy, las aplicaciones viven en entornos distribuidos, con:
- microservicios
- APIs internas y externas
- colas
- workers
- bases de datos
- cachés
- servicios serverless
- enorme variabilidad de tráfico
En ese contexto, el problema no siempre aparece como una ruptura abrupta.
Muchas veces comienza como una anomalía sutil:
- una latencia que aumenta lentamente
- un servicio que responde bien pero con más jitter
- una dependencia externa que empieza a fallar solo en ciertos picos
- un flujo crítico que sigue funcionando, pero de forma inconsistente
Este cambio de paradigma permite pasar del Mean Time To Detect (MTTD) al Mean Time To Predict (MTTP), moviendo la operación desde la reacción hacia la anticipación.
Desde la perspectiva de un sistema de IA, una anomalía no es simplemente “algo malo”.
Tampoco es necesariamente un error.
Una anomalía es un comportamiento que se desvía significativamente del patrón esperado, aprendido o históricamente observado para una señal, un servicio o un flujo.
Eso es importante porque una anomalía puede aparecer mucho antes de que exista un incidente.
Por ejemplo:
- una API que normalmente responde en 180 ms empieza a responder en 260 ms de forma sostenida
- el p95 de un endpoint crece un 20%, pero el promedio sigue pareciendo aceptable
- un flujo de login mantiene 200 OK, pero su tiempo de finalización sube de 1.1 s a 3.8 s
- una base de datos no está saturada, pero la variabilidad en tiempos de query cambia respecto a su patrón normal
- un worker sigue “vivo”, pero procesa eventos a un ritmo anómalo
En todos esos casos, el sistema puede no estar “roto” todavía.
Pero sí está comportándose de una forma distinta a la normal.
Eso, para un modelo de IA, ya es una señal valiosa.
La clave está en que el modelo no necesita una caída total para aprender.
Le basta con reconocer:
- patrones históricos
- estacionalidad
- ruido esperable
- rangos de variación normales
Cuando algo se aparta demasiado de ese marco, lo marca como anómalo.
Por eso la detección de anomalías funciona especialmente bien en monitoreo moderno: porque muchos incidentes no empiezan con errores visibles, sino con desviaciones pequeñas que solo cobran sentido cuando se miran con contexto.
No existe un único algoritmo mágico para detectar anomalías.
En la práctica, las plataformas modernas combinan varias técnicas según:
- tipo de señal
- volumen de datos
- frecuencia de muestreo
- complejidad del entorno
Los enfoques estadísticos siguen siendo muy relevantes, especialmente cuando se trabaja con métricas bien estructuradas y series de tiempo relativamente estables.
Aquí se usan técnicas como:
- medias móviles
- desviación estándar
- z-score
- bandas de confianza
- análisis de residuos
- modelos ARIMA o SARIMA
Estos modelos son cruciales porque predicen el próximo valor esperado en la serie (latencia, throughput).
La anomalía se detecta al medir la desviación entre el valor real y la predicción (residual).
La lógica básica es esta:
Si una señal suele moverse dentro de un rango estadísticamente esperable y de pronto se aleja de ese rango, hay una anomalía potencial.
Por ejemplo:
Si la latencia promedio de una API suele estar entre 120 y 180 ms con una desviación conocida, una subida sostenida a 260 ms puede marcarse como anómala aunque todavía no haya superado un umbral manual de 500 ms.
- interpretables
- livianos
- útiles para detectar cambios sutiles
- limitados en patrones muy complejos
- problemas con múltiples estacionalidades
- dificultades con alta no linealidad
Cuando el contexto se vuelve más complejo, entran en juego algoritmos de machine learning clásico.
Aquí aparecen métodos como:
- clustering
- k-nearest neighbors
- one-class SVM
- random forests adaptados
- isolation forest
Estos modelos aprenden a reconocer qué puntos se parecen al comportamiento normal y cuáles parecen estar lejos de él.
El clustering agrupa comportamientos similares.
Si la mayoría de los datos cae dentro de ciertos grupos normales y un nuevo comportamiento queda fuera de esos grupos, se considera sospechoso.
En monitoreo, esto puede servir para identificar patrones operativos regulares y detectar puntos que no encajan.
Isolation Forest es uno de los algoritmos más populares en detección de anomalías porque funciona bien sobre grandes volúmenes de datos.
La intuición es interesante:
Los puntos anómalos son más fáciles de aislar que los normales.
Los puntos comunes requieren muchas divisiones para aislarse.
Los puntos raros quedan aislados rápidamente.
Esto permite detectar observaciones inusuales sin necesidad de ejemplos explícitos de fallas.
Muy útil cuando hay múltiples dimensiones:
- latencia
- errores
- tráfico
- memoria
- regiones
- dependencias
Cuando el comportamiento del sistema es muy dinámico y complejo, entran modelos de deep learning.
Aquí destacan:
- autoencoders
- LSTM
- redes recurrentes
- transformers para series temporales
Los autoencoders aprenden a reconstruir patrones normales.
Se entrenan sobre datos sanos y aprenden a comprimir y reconstruir esa normalidad.
Cuando reciben algo distinto, la reconstrucción falla más de lo habitual.
Esa diferencia se usa como señal de anomalía.
En esencia, el sistema dice:
“Esto no se parece a los comportamientos normales que aprendí”.
Los modelos LSTM capturan dependencias temporales de largo plazo.
Esto importa porque no solo interesa el valor actual, sino también la secuencia previa.
Por ejemplo:
Una latencia de 300 ms puede ser normal a cierta hora, pero anómala si viene precedida por saturación, jitter y errores intermitentes.
LSTM y RNNs funcionan especialmente bien para:
- traces distribuidos
- logs
- eventos secuenciales
Una de las grandes fortalezas de la IA en monitoreo es que no analiza solo valores puntuales.
Analiza comportamiento.
El sistema aprende qué señales suelen aparecer juntas.
Por ejemplo:
Puede reconocer que cierto tráfico con cierta latencia y consumo de caché es normal en horario pico, pero sospechoso de madrugada.
No hace falta que la métrica explote.
Una subida lenta y sostenida puede ser más importante que un pico aislado.
La IA detecta:
- cambios de pendiente
- degradaciones progresivas
Muchos sistemas tienen patrones:
- diarios
- semanales
- estacionales
Un lunes por la mañana no se comporta igual que un sábado por la noche.
Los modelos modernos incorporan esa estacionalidad para evitar falsas alarmas.
Toda señal tiene ruido.
No todo cambio pequeño importa.
La IA busca distinguir entre:
- variación normal
- anomalía real
Eso es clave para reducir falsos positivos.
Los umbrales estáticos tienen tres problemas principales:
- No entienden contexto
- Llegan tarde
- Generan ruido o ceguera
La IA mejora esto porque trabaja con:
- líneas base dinámicas
- comportamiento histórico
- análisis contextual
- detecta degradaciones antes de cruzar límites
- reduce falsos positivos
- entiende estacionalidad
- prioriza patrones anómalos
Los umbrales siguen siendo útiles como red de seguridad.
Pero la IA permite pasar de un monitoreo reactivo a uno preventivo.
Una API suele tener un p95 de 220 ms.
Durante una campaña:
- sube a 310 ms
- luego a 420 ms
- después a 650 ms
El error rate sigue bajo.
Una alerta tradicional no se dispara.
La IA sí detecta la desviación y permite actuar antes de los timeouts masivos.
El checkout funciona para la mayoría, pero falla en el 1% de los usuarios.
El promedio parece sano.
Sin embargo, la IA detecta anomalías en:
- p99
- tiempos de respuesta
- dependencias externas
La CPU no llegó al límite.
No faltan conexiones.
Pero cambia la variabilidad de los tiempos de query.
Un modelo estadístico o Isolation Forest detecta la anomalía antes del colapso.
El servicio sigue respondiendo.
No hay caída visible.
Pero:
- la memoria crece distinto a lo habitual
- cambian los tiempos de garbage collection
Un modelo secuencial detecta el patrón antes del impacto real.
UptimeBolt combina varias de estas técnicas para construir una capa de monitoreo más predictiva y accionable.
La plataforma:
- analiza comportamiento histórico
- detecta anomalías en tiempo real
- correlaciona señales entre servicios y APIs
- monitorea journeys críticos
- predice incidentes con anticipación
- detección temprana de degradaciones
- análisis avanzado de series temporales
- correlación funcional y técnica
- monitoreo E2E
- predicción de incidentes
La idea no es reemplazar el monitoreo tradicional.
Es mejorarlo radicalmente.
Donde un sistema clásico dice:
“Algo ya está mal”
UptimeBolt busca decir:
“Esto está empezando a desviarse y podría convertirse en un incidente”.
Ese cambio reduce:
- MTTD
- impacto sobre SLOs
- operación reactiva
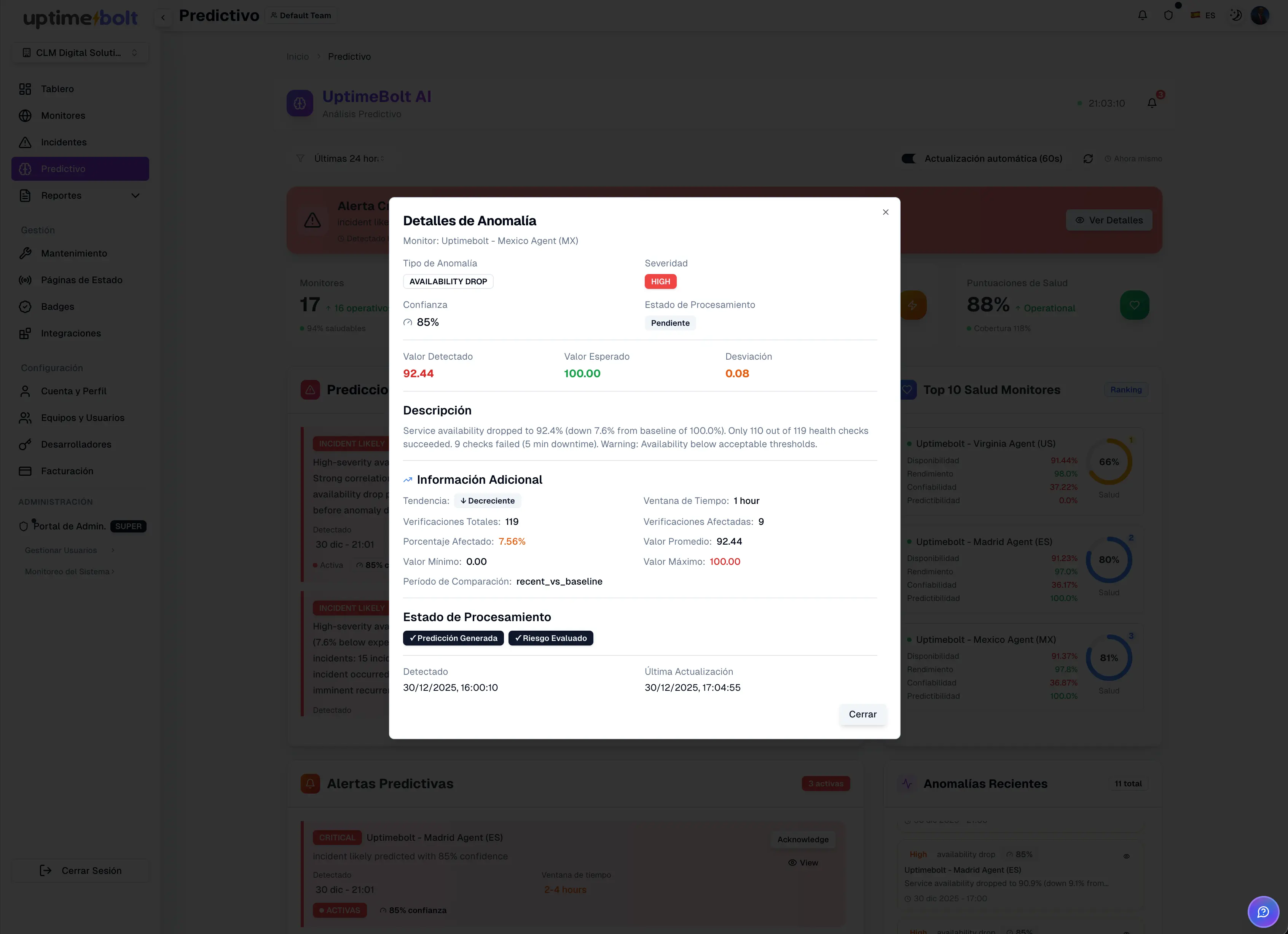
La IA aplicada al monitoreo no es magia ni una caja negra inexplicable.
Detrás existen algoritmos concretos:
- modelos estadísticos
- machine learning clásico
- clustering
- Isolation Forest
- autoencoders
- LSTM
- análisis de series temporales
Todos apuntan a la misma idea:
Detectar comportamientos anómalos antes de que se conviertan en incidentes críticos.
Entender cómo funcionan ayuda a confiar en ellos.
No hace falta ser experto en cada algoritmo.
Pero sí entender que la detección de anomalías se basa en:
- patrones
- contexto
- comportamiento histórico
- señales reales
Y en monitoreo moderno, eso marca la diferencia entre reaccionar tarde o actuar con anticipación.
Integrar detección de anomalías basada en IA es un paso clave para:
- asegurar SLOs
- reducir ruido de alertas
- mejorar observabilidad
- fortalecer operaciones DevOps
Cómo la IA detecta anomalías antes de que ocurran incidentes
Durante años, el monitoreo de sistemas se apoyó en un enfoque basado en reglas y alertamiento rígido por umbrales: definir métricas, fijar límites y generar alertas cuando algo los superaba.
Si la CPU pasaba del 80%, si la latencia promedio subía por encima de cierto valor o si el error rate se disparaba, el sistema avisaba.
Pero este modelo —centrado muchas veces en promedios y no en métricas más representativas como p95 o p99— empieza a fallar cuando se enfrenta a la variabilidad real de sistemas distribuidos.
Sigue teniendo valor, pero quedó corto frente a la complejidad de las arquitecturas modernas.
Por qué los umbrales estáticos quedaron cortos
Hoy, las aplicaciones viven en entornos distribuidos, con:
En ese contexto, el problema no siempre aparece como una ruptura abrupta.
Muchas veces comienza como una anomalía sutil:
Este cambio de paradigma permite pasar del Mean Time To Detect (MTTD) al Mean Time To Predict (MTTP), moviendo la operación desde la reacción hacia la anticipación.
Qué es una anomalía desde la perspectiva de un sistema de IA
Desde la perspectiva de un sistema de IA, una anomalía no es simplemente “algo malo”.
Tampoco es necesariamente un error.
Una anomalía es un comportamiento que se desvía significativamente del patrón esperado, aprendido o históricamente observado para una señal, un servicio o un flujo.
Eso es importante porque una anomalía puede aparecer mucho antes de que exista un incidente.
Por ejemplo:
En todos esos casos, el sistema puede no estar “roto” todavía.
Pero sí está comportándose de una forma distinta a la normal.
Eso, para un modelo de IA, ya es una señal valiosa.
La clave está en que el modelo no necesita una caída total para aprender.
Le basta con reconocer:
Cuando algo se aparta demasiado de ese marco, lo marca como anómalo.
Por eso la detección de anomalías funciona especialmente bien en monitoreo moderno: porque muchos incidentes no empiezan con errores visibles, sino con desviaciones pequeñas que solo cobran sentido cuando se miran con contexto.
Algoritmos más usados: estadísticos, machine learning clásico y deep learning
No existe un único algoritmo mágico para detectar anomalías.
En la práctica, las plataformas modernas combinan varias técnicas según:
Modelos estadísticos avanzados
Los enfoques estadísticos siguen siendo muy relevantes, especialmente cuando se trabaja con métricas bien estructuradas y series de tiempo relativamente estables.
Aquí se usan técnicas como:
Estos modelos son cruciales porque predicen el próximo valor esperado en la serie (latencia, throughput).
La anomalía se detecta al medir la desviación entre el valor real y la predicción (residual).
La lógica básica es esta:
Por ejemplo:
Si la latencia promedio de una API suele estar entre 120 y 180 ms con una desviación conocida, una subida sostenida a 260 ms puede marcarse como anómala aunque todavía no haya superado un umbral manual de 500 ms.
Ventajas
Desventajas
Machine Learning clásico
Cuando el contexto se vuelve más complejo, entran en juego algoritmos de machine learning clásico.
Aquí aparecen métodos como:
Estos modelos aprenden a reconocer qué puntos se parecen al comportamiento normal y cuáles parecen estar lejos de él.
Clustering
El clustering agrupa comportamientos similares.
Si la mayoría de los datos cae dentro de ciertos grupos normales y un nuevo comportamiento queda fuera de esos grupos, se considera sospechoso.
En monitoreo, esto puede servir para identificar patrones operativos regulares y detectar puntos que no encajan.
Isolation Forest
Isolation Forest es uno de los algoritmos más populares en detección de anomalías porque funciona bien sobre grandes volúmenes de datos.
La intuición es interesante:
Los puntos comunes requieren muchas divisiones para aislarse.
Los puntos raros quedan aislados rápidamente.
Esto permite detectar observaciones inusuales sin necesidad de ejemplos explícitos de fallas.
Muy útil cuando hay múltiples dimensiones:
Deep Learning
Cuando el comportamiento del sistema es muy dinámico y complejo, entran modelos de deep learning.
Aquí destacan:
Autoencoders
Los autoencoders aprenden a reconstruir patrones normales.
Se entrenan sobre datos sanos y aprenden a comprimir y reconstruir esa normalidad.
Cuando reciben algo distinto, la reconstrucción falla más de lo habitual.
Esa diferencia se usa como señal de anomalía.
En esencia, el sistema dice:
LSTM y modelos secuenciales
Los modelos LSTM capturan dependencias temporales de largo plazo.
Esto importa porque no solo interesa el valor actual, sino también la secuencia previa.
Por ejemplo:
Una latencia de 300 ms puede ser normal a cierta hora, pero anómala si viene precedida por saturación, jitter y errores intermitentes.
LSTM y RNNs funcionan especialmente bien para:
Detección por patrones, tendencias, estacionalidad y ruido
Una de las grandes fortalezas de la IA en monitoreo es que no analiza solo valores puntuales.
Analiza comportamiento.
Patrones
El sistema aprende qué señales suelen aparecer juntas.
Por ejemplo:
Puede reconocer que cierto tráfico con cierta latencia y consumo de caché es normal en horario pico, pero sospechoso de madrugada.
Tendencias
No hace falta que la métrica explote.
Una subida lenta y sostenida puede ser más importante que un pico aislado.
La IA detecta:
Estacionalidad
Muchos sistemas tienen patrones:
Un lunes por la mañana no se comporta igual que un sábado por la noche.
Los modelos modernos incorporan esa estacionalidad para evitar falsas alarmas.
Ruido
Toda señal tiene ruido.
No todo cambio pequeño importa.
La IA busca distinguir entre:
Eso es clave para reducir falsos positivos.
Ventajas frente a umbrales estáticos
Los umbrales estáticos tienen tres problemas principales:
La IA mejora esto porque trabaja con:
Ventajas concretas
Los umbrales siguen siendo útiles como red de seguridad.
Pero la IA permite pasar de un monitoreo reactivo a uno preventivo.
Ejemplos reales de anomalías detectadas antes de incidentes
Caso 1: degradación de API de pagos
Una API suele tener un p95 de 220 ms.
Durante una campaña:
El error rate sigue bajo.
Una alerta tradicional no se dispara.
La IA sí detecta la desviación y permite actuar antes de los timeouts masivos.
Caso 2: errores intermitentes en checkout
El checkout funciona para la mayoría, pero falla en el 1% de los usuarios.
El promedio parece sano.
Sin embargo, la IA detecta anomalías en:
Caso 3: saturación progresiva en base de datos
La CPU no llegó al límite.
No faltan conexiones.
Pero cambia la variabilidad de los tiempos de query.
Un modelo estadístico o Isolation Forest detecta la anomalía antes del colapso.
Caso 4: memory leak en microservicio
El servicio sigue respondiendo.
No hay caída visible.
Pero:
Un modelo secuencial detecta el patrón antes del impacto real.
Cómo UptimeBolt aplica estas técnicas
UptimeBolt combina varias de estas técnicas para construir una capa de monitoreo más predictiva y accionable.
La plataforma:
Capacidades
La idea no es reemplazar el monitoreo tradicional.
Es mejorarlo radicalmente.
Donde un sistema clásico dice:
UptimeBolt busca decir:
Ese cambio reduce:
Conclusión
La IA aplicada al monitoreo no es magia ni una caja negra inexplicable.
Detrás existen algoritmos concretos:
Todos apuntan a la misma idea:
Entender cómo funcionan ayuda a confiar en ellos.
No hace falta ser experto en cada algoritmo.
Pero sí entender que la detección de anomalías se basa en:
Y en monitoreo moderno, eso marca la diferencia entre reaccionar tarde o actuar con anticipación.
Integrar detección de anomalías basada en IA es un paso clave para: