Last week I asked how much you pay for AI APIs. The responses: between $500-$5,000/month.
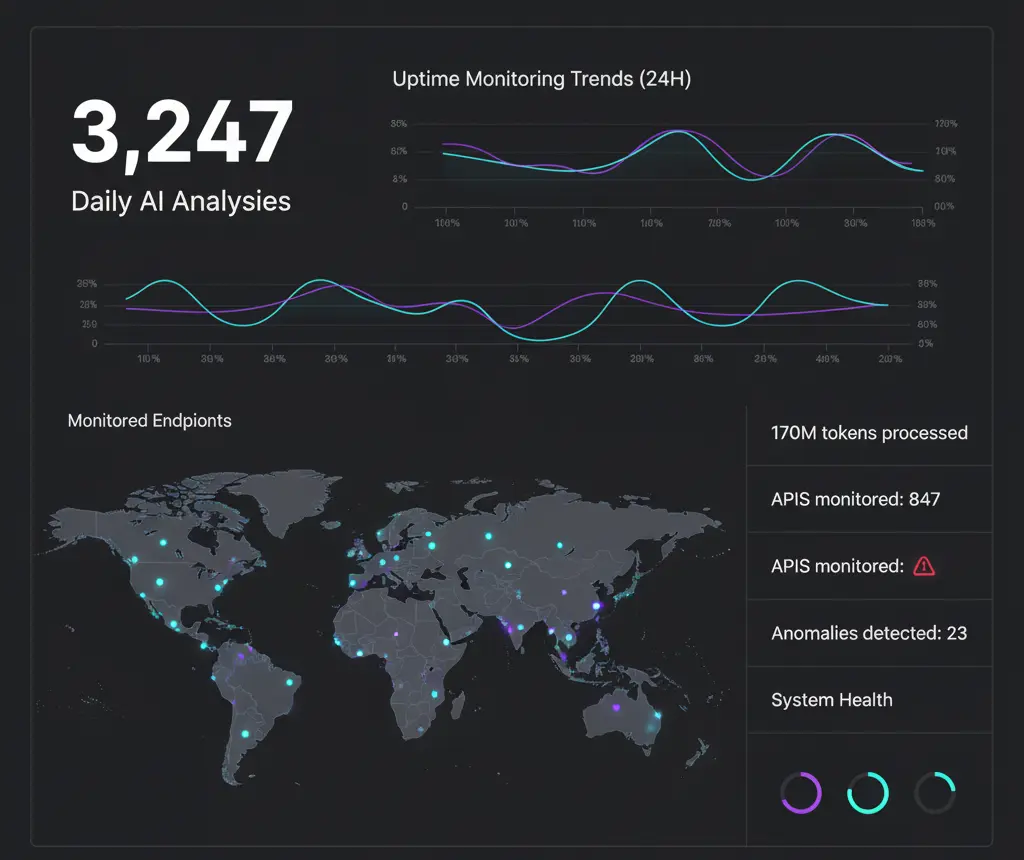
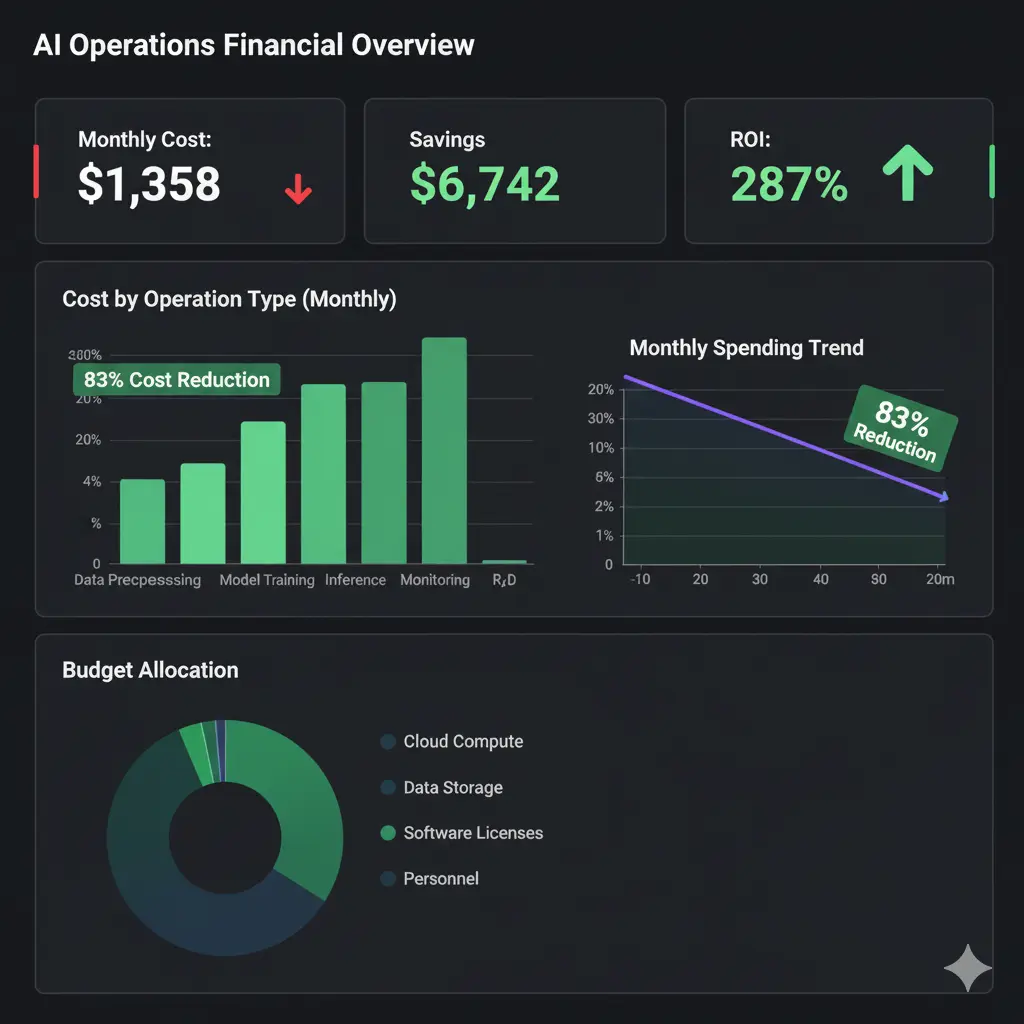
Today I'm sharing how at UptimeBolt we process 170 million tokens with a projected cost not exceeding $100/month. A reduction of over 83% without cutting a single feature.
And no, it was NOT just "enabling prompt caching" (that only gives 10-15% savings).
UptimeBolt monitors 24/7:
- Websites and APIs
- Complex transactions
- Databases
- Email services
- Complete infrastructure
Every day, AI analyzes thousands of metrics to:
- Real-time anomaly detection
- Predicting incidents before they happen
- Automatic root cause analysis
- Predictive capacity optimization
Without optimization, this would be economically unviable.
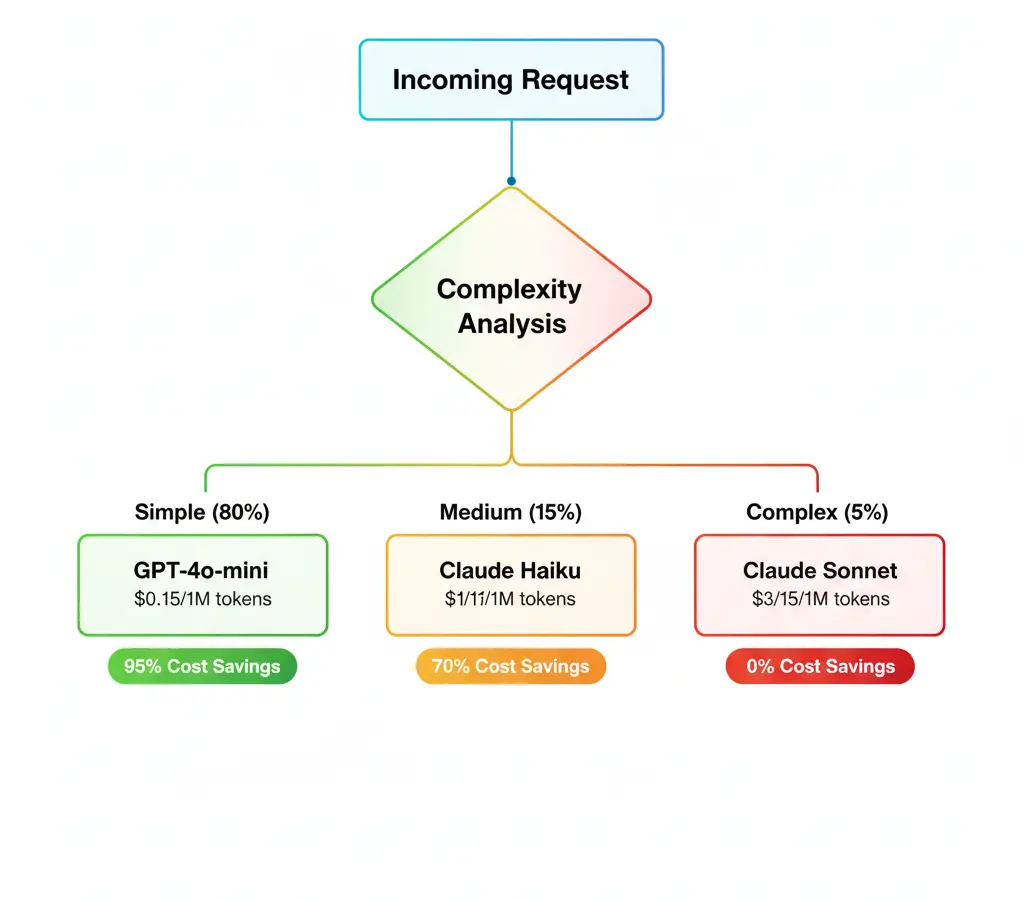
This is secret #1.
I don't send everything to GPT-5 or Claude Sonnet 4.5. I created a matrix that decides the model based on:
- Task complexity
- Acceptable latency
- Available budget
'anomaly-simple': 'gpt-4o-mini',
'anomaly-complex': 'claude-haiku-4.5',
'incident-analysis': 'claude-sonnet-4.5',
'batch-predictions': 'gpt-4o-mini'
Result: 80% of my tasks use economical models. Only 20% use the expensive ones.
Savings: 60-70%
Instead of hundreds or thousands of individual calls per day, I group similar analyses:
- Anomaly detection: up to 50 monitors in one call
- Predictive analysis: by service type and region
- Reports: nightly batch processing
async processBatchAnomalies(monitors: Monitor[]) {
const batches = this.createOptimalBatches(monitors, {
maxTokensPerBatch: 100000,
maxMonitorsPerBatch: 50
});
return Promise.all(batches.map(batch =>
this.analyzeWithRateLimit(batch)
));
}
Advantages:
- 50% discount on OpenAI Batch API
- Less request overhead
- Better prompt caching utilization
Savings: 40-50%
Monitoring metrics are time series. Here's the change that had the most impact:
❌ BEFORE (8,000 average tokens):
[
{"timestamp": "2025-10-21T10:00:00Z", "responseTime": 234, "status": "ok"},
{"timestamp": "2025-10-21T10:01:00Z", "responseTime": 245, "status": "ok"},
]
✅ AFTER (1,200 average tokens):
{
period: "2025-10-21",
stats: {min: 180, max: 450, avg: 234, p95: 380, p99: 420},
trends: "stable_spike_14:00",
samples: 1440,
anomalies: [{time: "14:00", val: 450, delta: "+87%"}]
}
Reduction: 85% in input tokens
Additionally:
- Plain text instead of verbose JSON
- Abbreviated IDs:
srv:a1b2c3 vs server-id: a1b2c3d4-e5f6-7890-abcd-ef1234567890
- Symbols for states:
✅ ⚠️ 🔴 vs "operational, warning, critical"
Additional savings: 40-60% in input tokens

Every word in a prompt costs money. I optimized without mercy:
❌ BEFORE (250 instruction tokens):
"Please analyze the following monitoring data carefully and tell me
if there are any anomalies present. Consider historical patterns,
trends, seasonality effects, and provide detailed explanations
about your findings..."
✅ AFTER (45 tokens):
"Analyze metrics for anomalies.
Return JSON: {hasAnomaly: bool, type: string, confidence: 0-1, reason: string}"
Real impact:
- Original prompts: ~8K average tokens
- After optimization: ~3K tokens
- Reduction: 62%
- Bonus: 40% faster responses
Savings: 80% in system tokens
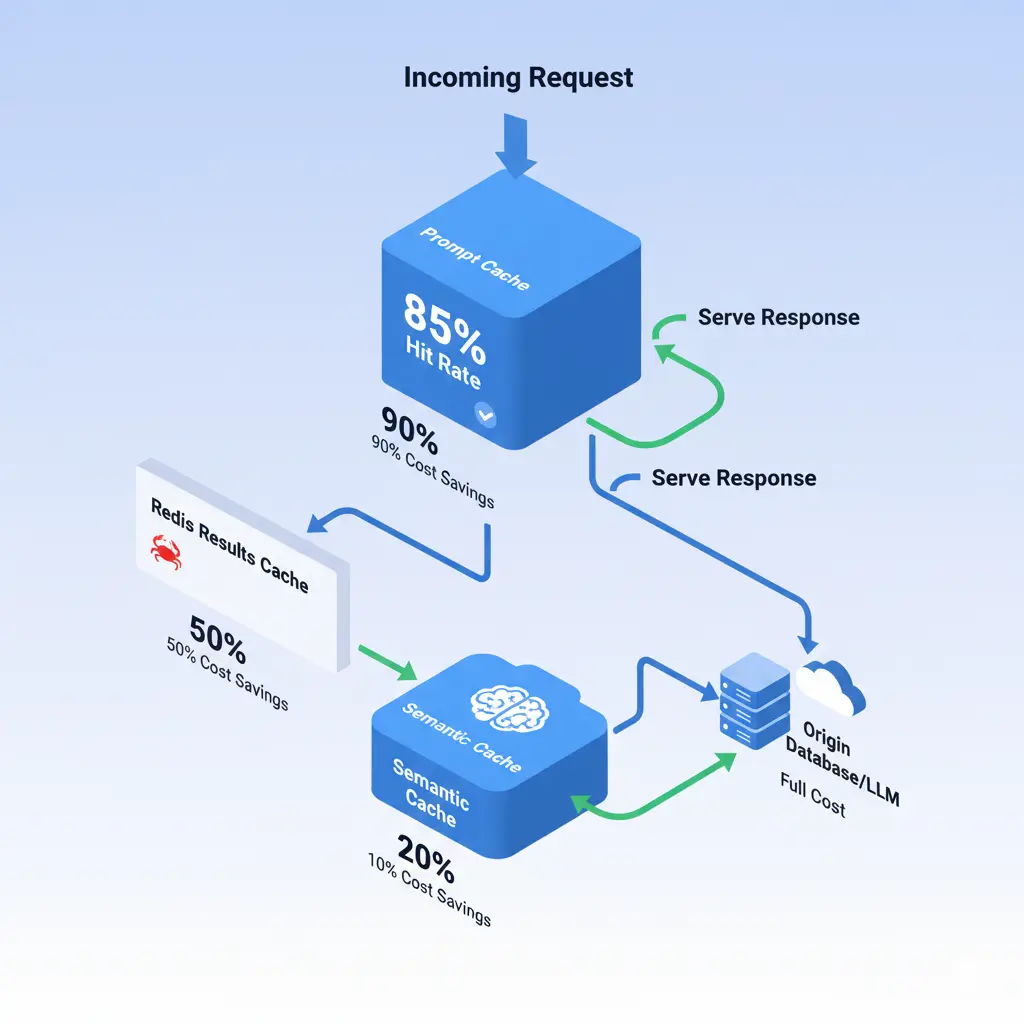
Here's the trap: Claude's prompt caching expires every 5 minutes (or 1 hour paying extra). My solution: three cache levels.
Level 1: Prompt Caching (Claude/OpenAI)
- For contexts that repeat in < 5 min
- Real hit rate: 85%
- Savings: 10-15%
Level 2: Result Cache (Redis)
- Identical analyses in 24h are reused
- Hit rate: 30%
- Savings: 100% of cost in those cases
Level 3: Semantic Cache
- If metrics change < 5%, I reuse analysis
- Hit rate: 20%
- Savings: 100% in stable scenarios
async analyzeWithCache(data: MetricData) {
const semanticHash = this.generateSemanticHash(data);
const cached = await redis.get(semanticHash);
if (cached && this.isDataSimilar(data, cached.original, 0.05)) {
return cached.result;
}
return this.callAI(data);
}
Combined savings: 30-45%
Not everything requires AI. I implemented a three-layer system:
Layer 1: Simple Rules (Cost: $0)
if (responseTime > threshold * 3) {
return {anomaly: true, confidence: 0.95, type: 'spike'};
}
Layer 2: Light Analysis (GPT-4o-mini / Haiku 4.5)
- For cases that pass Layer 1
- 20% of alerts reach here
Layer 3: Deep Analysis (Claude Sonnet)
- Only for complex cases that fail in Layer 2
- 5% of alerts reach here
async detectAnomaly(metrics: Metric[]) {
const simple = this.ruleBasedDetection(metrics);
if (simple.confidence > 0.9) return simple;
const light = await this.lightAIAnalysis(metrics);
if (light.confidence > 0.85) return light;
return this.deepAIAnalysis(metrics);
}
Result: 50% of AI calls avoided completely.
Savings: 50% in call volume
You can't optimize what you don't measure. I implemented complete tracking:
class AIBudgetManager {
async trackUsage(operation: string, tokens: TokenUsage, cost: number) {
await db.aiUsage.create({
operation,
model: tokens.model,
inputTokens: tokens.input,
outputTokens: tokens.output,
cachedTokens: tokens.cached,
totalCost: cost,
timestamp: new Date()
});
await this.checkBudgetThreshold();
}
async getROI(operationType: string) {
const cost = await this.getOperationCost(operationType);
const value = await this.getBusinessValue(operationType);
return {cost, value, roi: (value - cost) / cost};
}
}
This allows me to:
- Identify most expensive operations
- Measure ROI of each analysis type
- Alerts before exceeding budget
- Continuous optimization based on data
Key discoveries:
- 10% of operations consumed 70% of budget
- Some "cheap" operations generated more value than expensive ones
- I eliminated 3 analysis types with negative ROI
Savings breakdown:
- Model selection matrix: 60%
- Batch processing: 40%
- Token optimization: 60%
- Prompt engineering: 80%
- Multi-level cache: 35%
- Lazy analysis: 50%
- Combined: +83% total reduction
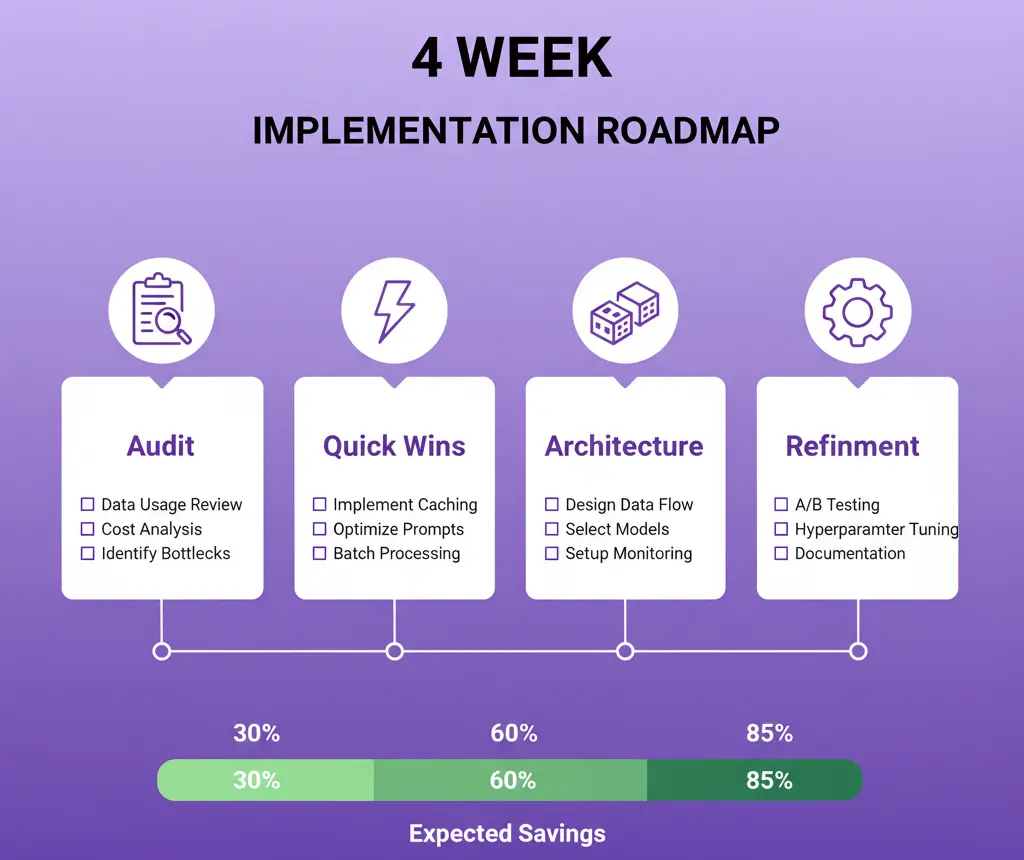
Week 1: Audit 📋
Week 2: Quick Wins ⚡
Week 3: Architecture 🏗️
Week 4: Refinement 🔧
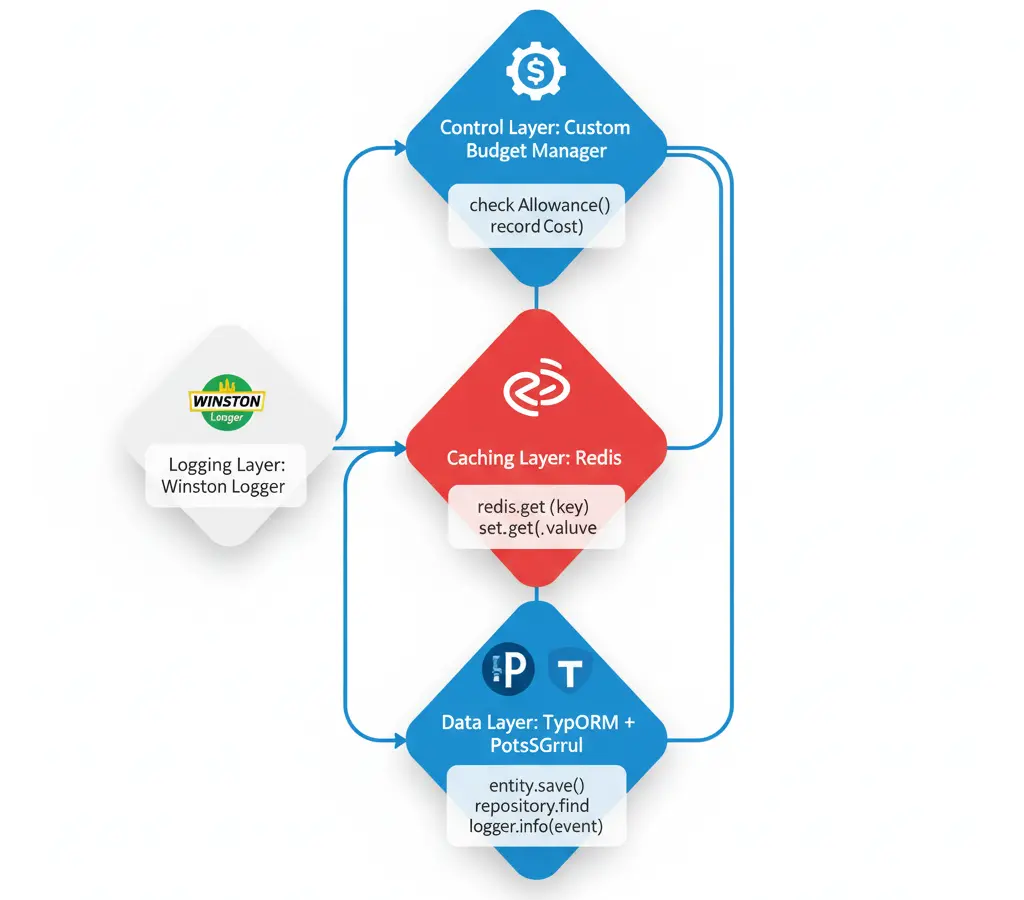
My implementation uses:
- TypeORM + PostgreSQL: Historical usage tracking
- Redis: Multi-level cache and rate limiting
- Winston Logger: Structured logs of all calls
- Custom Budget Manager: Own budget system
Budget Manager starter code:
import Anthropic from '@anthropic-ai/sdk';
import OpenAI from 'openai';
class SimpleBudgetTracker {
private costs = {
'gpt-4o-mini': {input: 0.15, output: 0.60},
'claude-haiku-4.5': {input: 1.00, output: 5.00},
'claude-sonnet-4.5': {input: 3.00, output: 15.00}
};
async trackCall(model: string, input: number, output: number) {
const cost = (input/1000000 * this.costs[model].input) +
(output/1000000 * this.costs[model].output);
await db.insert({model, input, output, cost, date: new Date()});
console.log(`💰 ${model}: $${cost.toFixed(4)}`);
}
}
- Prompt caching isn't magic: Only 10-15% savings
- 1hr cache only worth it with high volume: Miscalculating ROI is common
- Prompt changes = invalid cache: Version your prompts
- Not everything benefits from batch: Urgent requests go direct
- Measuring hit rate wrong destroys your ROI: Implement tracking from day 1
- Optimization is iterative: You don't achieve 83% in one day
- Architecture > Prompt: A good system beats a good prompt
- 80/20 works here: 20% of operations consume 80% of budget
- Most expensive model ≠ the best for every case: GPT-4o-mini or Haiku 4.5 solves 90% of my cases
- ROI > absolute cost: Some expensive operations generate much more value

If you pay more than $500/month for AI APIs, you're probably leaving $400+ on the table every month.
Start today:
- Measure your current usage (script above)
- Implement model selection (start with 2 models)
- Optimize your 3 most expensive prompts (plain text + compression)
That 70-85% savings is there, waiting for you.
What strategy will you implement first? Comment and I'll help you prioritize.
Want the complete Budget Manager code? Let me know in comments.
Follow me for more no-BS optimizations from a SaaS founder in the trenches.
Last week I asked how much you pay for AI APIs. The responses: between $500-$5,000/month.
Today I'm sharing how at UptimeBolt we process 170 million tokens with a projected cost not exceeding $100/month. A reduction of over 83% without cutting a single feature.
And no, it was NOT just "enabling prompt caching" (that only gives 10-15% savings).
📊 The Real Context
UptimeBolt monitors 24/7:
Every day, AI analyzes thousands of metrics to:
Without optimization, this would be economically unviable.
The 7 Tricks That Actually Work
1. 🎯 Smart Architecture: Model Selection Matrix
This is secret #1.
I don't send everything to GPT-5 or Claude Sonnet 4.5. I created a matrix that decides the model based on:
Result: 80% of my tasks use economical models. Only 20% use the expensive ones.
Savings: 60-70%
2. 📦 Batch Processing (Where the Gold Is)
Instead of hundreds or thousands of individual calls per day, I group similar analyses:
Advantages:
Savings: 40-50%
3. 🗜️ Token Optimization: Data Compression
Monitoring metrics are time series. Here's the change that had the most impact:
❌ BEFORE (8,000 average tokens):
✅ AFTER (1,200 average tokens):
Reduction: 85% in input tokens
Additionally:
srv:a1b2c3vsserver-id: a1b2c3d4-e5f6-7890-abcd-ef1234567890✅ ⚠️ 🔴vs"operational, warning, critical"Additional savings: 40-60% in input tokens
4. 🎣 Surgical Prompt Engineering
Every word in a prompt costs money. I optimized without mercy:
❌ BEFORE (250 instruction tokens):
✅ AFTER (45 tokens):
Real impact:
Savings: 80% in system tokens
5. 🔄 Multi-Level Cache (Not Just Prompt Caching)
Here's the trap: Claude's prompt caching expires every 5 minutes (or 1 hour paying extra). My solution: three cache levels.
Level 1: Prompt Caching (Claude/OpenAI)
Level 2: Result Cache (Redis)
Level 3: Semantic Cache
Combined savings: 30-45%
6. 🤖 Lazy Analysis: Only When Necessary
Not everything requires AI. I implemented a three-layer system:
Layer 1: Simple Rules (Cost: $0)
Layer 2: Light Analysis (GPT-4o-mini / Haiku 4.5)
Layer 3: Deep Analysis (Claude Sonnet)
Result: 50% of AI calls avoided completely.
Savings: 50% in call volume
7. 📊 Budget Management and ROI Tracking
You can't optimize what you don't measure. I implemented complete tracking:
This allows me to:
Key discoveries:
📈 The Real Numbers (No Marketing)
Savings breakdown:
🚀 Implementation: Your 4-Week Plan
Week 1: Audit 📋
Week 2: Quick Wins ⚡
Week 3: Architecture 🏗️
Week 4: Refinement 🔧
🛠️ Tech Stack
My implementation uses:
Budget Manager starter code:
⚠️ The Traps You Must Avoid
💡 Lessons Learned
✅ Your Immediate Action
If you pay more than $500/month for AI APIs, you're probably leaving $400+ on the table every month.
Start today:
That 70-85% savings is there, waiting for you.
What strategy will you implement first? Comment and I'll help you prioritize.
Want the complete Budget Manager code? Let me know in comments.
Follow me for more no-BS optimizations from a SaaS founder in the trenches.