Website uptime monitoring is the practice of continuously checking whether your website or web application is accessible and functioning correctly. In today's digital landscape, even a few minutes of downtime can result in lost revenue, damaged reputation, and frustrated users.
Uptime monitoring involves automated systems that periodically check your website's availability from multiple locations around the world. These systems send requests to your site and verify that it responds correctly within an acceptable timeframe.
When your site fails to respond or returns an error, the monitoring system immediately alerts you through your preferred channels - email, SMS, Slack, or other integrations. This allows you to respond quickly and minimize the impact of downtime.

For e-commerce sites, every minute of downtime directly translates to lost sales. Studies show that even a single hour of downtime can cost businesses thousands to millions of dollars, depending on their size and industry.
Modern users expect websites to be available 24/7. When your site is down, users don't wait - they go to competitors. A single bad experience can permanently lose a customer.
Search engines like Google factor site reliability into their rankings. Frequent downtime signals to search engines that your site provides a poor user experience, potentially harming your search visibility.
If you provide services to other businesses, you likely have Service Level Agreements (SLAs) guaranteeing specific uptime percentages. Monitoring helps you track and maintain these commitments.
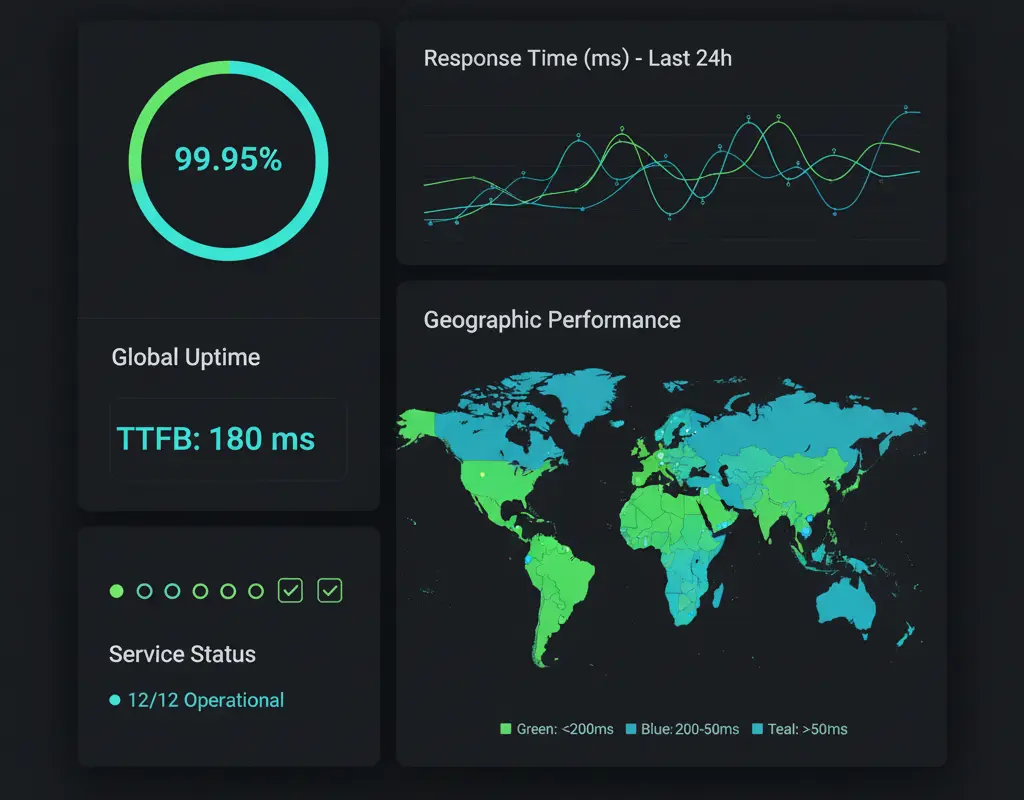
This is the most fundamental metric - the percentage of time your site is available and functioning. Industry standard targets are typically 99.9% (three nines) or higher, which allows for approximately 8.76 hours of downtime per year.
How quickly your site responds to requests matters almost as much as availability. Slow response times frustrate users and can indicate underlying performance issues before they become full outages.
TTFB measures how long it takes for your server to start sending data after receiving a request. This metric helps identify server-side performance bottlenecks.
Your site may perform differently in various regions due to CDN coverage, routing issues, or regional infrastructure problems. Monitoring from multiple locations helps identify geographic disparities.
The most basic form checks if your website returns a successful HTTP status code (typically 200 OK). You can configure checks to verify specific response codes, response times, and even content on the page.
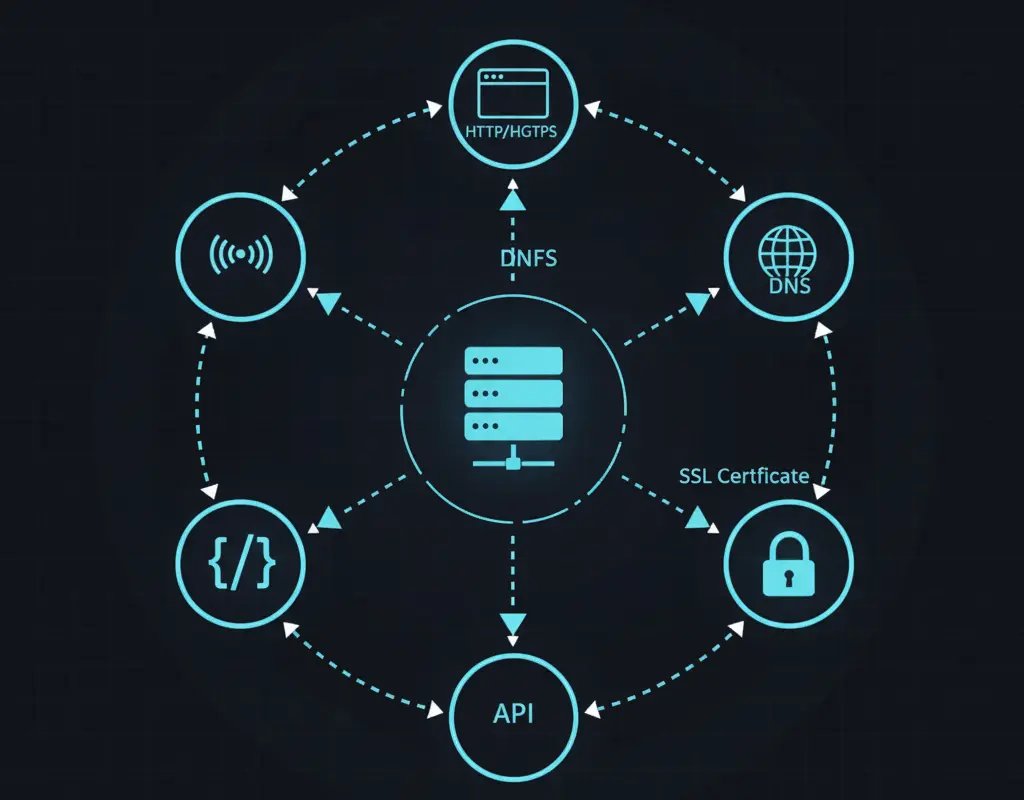
ICMP ping checks verify basic network connectivity to your server. While simpler than HTTP monitoring, ping checks can help identify network-level issues.
Monitors specific TCP or UDP ports to ensure services like databases, mail servers, or custom applications are accessible. Essential for backend infrastructure monitoring.
Verifies that your domain name resolves correctly to the right IP addresses. DNS failures can make your site completely unreachable even if your servers are running perfectly.
Tracks SSL certificate expiration dates and validity. Expired certificates cause browsers to show scary warnings, effectively making your site unusable for most visitors.
For applications with APIs, specialized monitoring can verify endpoints return correct data and meet performance expectations. This goes beyond simple availability checks.
Also called synthetic monitoring, this simulates real user interactions like logging in, adding items to a cart, or completing a checkout. It ensures critical user flows work end-to-end.
Check your site from different geographic regions to catch regional outages and CDN issues. What works in North America might be broken in Asia or Europe.
Balance between catching issues quickly and avoiding unnecessary load on your servers. For critical production sites, 1-5 minute intervals are common. Less critical services might check every 15-30 minutes.
Avoid alert fatigue by setting up intelligent notification rules. Use escalation policies that alert different people based on severity and duration. Consider using multiple confirmation checks before triggering an alert to reduce false positives.
Don't just check your homepage. Monitor critical pages, APIs, databases, and third-party integrations. A failure anywhere in your stack can impact users.
Understanding normal performance patterns makes it easier to spot anomalies. Track trends over time to identify gradual degradation before it becomes critical.
When downtime occurs, every second counts. Have clear runbooks and escalation procedures so your team knows exactly what to do and who to contact.
Periodically verify that your monitoring system itself is working correctly. Set up a test endpoint that you can intentionally break to confirm alerts fire as expected.
Hardware failures, resource exhaustion (CPU, memory, disk), or operating system problems can take servers offline.
Bugs in your code, memory leaks, or unhandled exceptions can crash your application or make it unresponsive.
Database connection pool exhaustion, query timeouts, or database server failures are common culprits behind application downtime.
Issues with your hosting provider's network, DDoS attacks, or routing problems can make your site unreachable.
Problems with your DNS provider or misconfigurations can prevent users from reaching your site even when servers are healthy.
External APIs, payment processors, or other services you depend on can fail and take your site down with them.
Bad deployments are a leading cause of downtime. Always have rollback procedures and consider blue-green or canary deployments.
Evaluate what you need to monitor, how frequently, and from how many locations. A small blog has different requirements than a global e-commerce platform.
Ensure the monitoring solution integrates with your existing tools - alerting channels, incident management systems, and status page providers.
Understand the pricing model. Some charge per check, others per monitored endpoint. Calculate projected costs as you scale.
Your monitoring system needs to be more reliable than what you're monitoring. Look for providers with proven track records and their own status pages.
Can you customize check intervals, timeout thresholds, and alert conditions? Flexibility matters as your needs evolve.
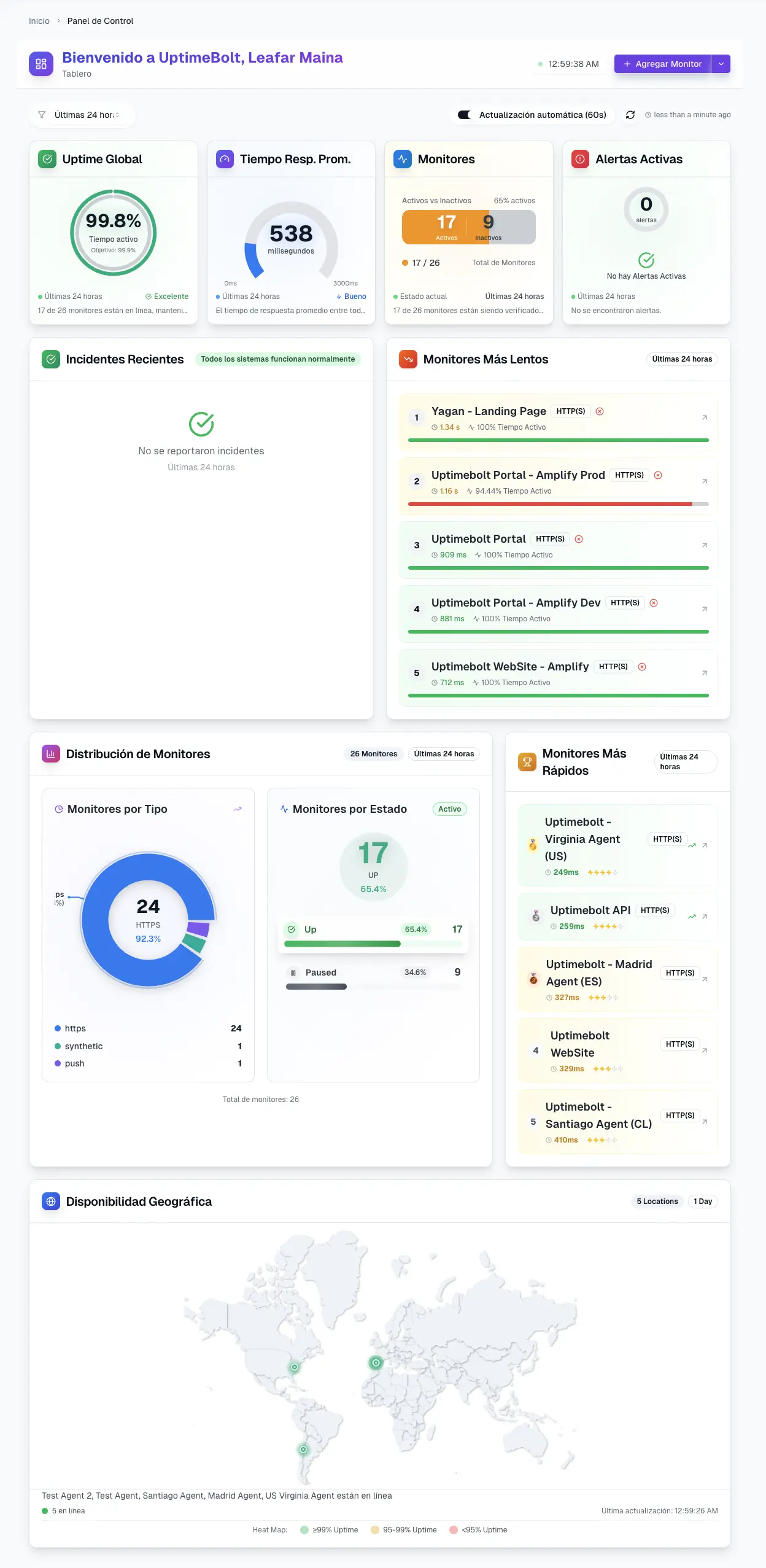
UptimeBolt provides comprehensive uptime monitoring with a straightforward setup process:
Quick Setup: Add your first monitor in under a minute. No complex configuration required.
Global Monitoring: We check your sites from multiple continents to ensure global availability.
Instant Alerts: Get notified immediately via email, SMS, Slack, or webhooks when issues are detected.
Detailed Analytics: View uptime history, response times, and incident reports to understand your site's reliability.
Multiple Monitor Types: HTTP(S), ping, port, DNS, and SSL certificate monitoring all in one platform.
Affordable Pricing: Start free and scale as you grow. No surprise charges or hidden fees.
Website uptime monitoring isn't optional - it's essential infrastructure for any online business. The cost of downtime far exceeds the investment in monitoring tools.
By implementing comprehensive monitoring, setting up intelligent alerting, and following best practices, you can minimize downtime, respond faster to incidents, and provide the reliable experience your users expect.
Don't wait for a catastrophic outage to realize the importance of monitoring. Start today, and gain the peace of mind that comes from knowing you'll be the first to know when something goes wrong.
Website uptime monitoring is the practice of continuously checking whether your website or web application is accessible and functioning correctly. In today's digital landscape, even a few minutes of downtime can result in lost revenue, damaged reputation, and frustrated users.
What is Uptime Monitoring?
Uptime monitoring involves automated systems that periodically check your website's availability from multiple locations around the world. These systems send requests to your site and verify that it responds correctly within an acceptable timeframe.
When your site fails to respond or returns an error, the monitoring system immediately alerts you through your preferred channels - email, SMS, Slack, or other integrations. This allows you to respond quickly and minimize the impact of downtime.
Why Uptime Monitoring Matters
Financial Impact
For e-commerce sites, every minute of downtime directly translates to lost sales. Studies show that even a single hour of downtime can cost businesses thousands to millions of dollars, depending on their size and industry.
User Experience
Modern users expect websites to be available 24/7. When your site is down, users don't wait - they go to competitors. A single bad experience can permanently lose a customer.
SEO Consequences
Search engines like Google factor site reliability into their rankings. Frequent downtime signals to search engines that your site provides a poor user experience, potentially harming your search visibility.
SLA Compliance
If you provide services to other businesses, you likely have Service Level Agreements (SLAs) guaranteeing specific uptime percentages. Monitoring helps you track and maintain these commitments.
Key Metrics to Track
Uptime Percentage
This is the most fundamental metric - the percentage of time your site is available and functioning. Industry standard targets are typically 99.9% (three nines) or higher, which allows for approximately 8.76 hours of downtime per year.
Response Time
How quickly your site responds to requests matters almost as much as availability. Slow response times frustrate users and can indicate underlying performance issues before they become full outages.
Time to First Byte (TTFB)
TTFB measures how long it takes for your server to start sending data after receiving a request. This metric helps identify server-side performance bottlenecks.
Geographic Performance
Your site may perform differently in various regions due to CDN coverage, routing issues, or regional infrastructure problems. Monitoring from multiple locations helps identify geographic disparities.
Types of Uptime Monitoring
HTTP(S) Monitoring
The most basic form checks if your website returns a successful HTTP status code (typically 200 OK). You can configure checks to verify specific response codes, response times, and even content on the page.
Ping Monitoring
ICMP ping checks verify basic network connectivity to your server. While simpler than HTTP monitoring, ping checks can help identify network-level issues.
Port Monitoring
Monitors specific TCP or UDP ports to ensure services like databases, mail servers, or custom applications are accessible. Essential for backend infrastructure monitoring.
DNS Monitoring
Verifies that your domain name resolves correctly to the right IP addresses. DNS failures can make your site completely unreachable even if your servers are running perfectly.
SSL Certificate Monitoring
Tracks SSL certificate expiration dates and validity. Expired certificates cause browsers to show scary warnings, effectively making your site unusable for most visitors.
API Monitoring
For applications with APIs, specialized monitoring can verify endpoints return correct data and meet performance expectations. This goes beyond simple availability checks.
Transaction Monitoring
Also called synthetic monitoring, this simulates real user interactions like logging in, adding items to a cart, or completing a checkout. It ensures critical user flows work end-to-end.
Best Practices for Uptime Monitoring
Monitor from Multiple Locations
Check your site from different geographic regions to catch regional outages and CDN issues. What works in North America might be broken in Asia or Europe.
Set Appropriate Check Intervals
Balance between catching issues quickly and avoiding unnecessary load on your servers. For critical production sites, 1-5 minute intervals are common. Less critical services might check every 15-30 minutes.
Configure Smart Alerting
Avoid alert fatigue by setting up intelligent notification rules. Use escalation policies that alert different people based on severity and duration. Consider using multiple confirmation checks before triggering an alert to reduce false positives.
Monitor the Full Stack
Don't just check your homepage. Monitor critical pages, APIs, databases, and third-party integrations. A failure anywhere in your stack can impact users.
Establish Baselines
Understanding normal performance patterns makes it easier to spot anomalies. Track trends over time to identify gradual degradation before it becomes critical.
Document Response Procedures
When downtime occurs, every second counts. Have clear runbooks and escalation procedures so your team knows exactly what to do and who to contact.
Test Your Monitoring
Periodically verify that your monitoring system itself is working correctly. Set up a test endpoint that you can intentionally break to confirm alerts fire as expected.
Common Causes of Downtime
Server Issues
Hardware failures, resource exhaustion (CPU, memory, disk), or operating system problems can take servers offline.
Application Errors
Bugs in your code, memory leaks, or unhandled exceptions can crash your application or make it unresponsive.
Database Problems
Database connection pool exhaustion, query timeouts, or database server failures are common culprits behind application downtime.
Network Problems
Issues with your hosting provider's network, DDoS attacks, or routing problems can make your site unreachable.
DNS Failures
Problems with your DNS provider or misconfigurations can prevent users from reaching your site even when servers are healthy.
Third-Party Dependencies
External APIs, payment processors, or other services you depend on can fail and take your site down with them.
Deployment Issues
Bad deployments are a leading cause of downtime. Always have rollback procedures and consider blue-green or canary deployments.
Choosing a Monitoring Solution
Consider Your Needs
Evaluate what you need to monitor, how frequently, and from how many locations. A small blog has different requirements than a global e-commerce platform.
Integration Capabilities
Ensure the monitoring solution integrates with your existing tools - alerting channels, incident management systems, and status page providers.
Pricing Structure
Understand the pricing model. Some charge per check, others per monitored endpoint. Calculate projected costs as you scale.
Reliability of the Monitor
Your monitoring system needs to be more reliable than what you're monitoring. Look for providers with proven track records and their own status pages.
Customization Options
Can you customize check intervals, timeout thresholds, and alert conditions? Flexibility matters as your needs evolve.
Getting Started with UptimeBolt
UptimeBolt provides comprehensive uptime monitoring with a straightforward setup process:
Quick Setup: Add your first monitor in under a minute. No complex configuration required.
Global Monitoring: We check your sites from multiple continents to ensure global availability.
Instant Alerts: Get notified immediately via email, SMS, Slack, or webhooks when issues are detected.
Detailed Analytics: View uptime history, response times, and incident reports to understand your site's reliability.
Multiple Monitor Types: HTTP(S), ping, port, DNS, and SSL certificate monitoring all in one platform.
Affordable Pricing: Start free and scale as you grow. No surprise charges or hidden fees.
Conclusion
Website uptime monitoring isn't optional - it's essential infrastructure for any online business. The cost of downtime far exceeds the investment in monitoring tools.
By implementing comprehensive monitoring, setting up intelligent alerting, and following best practices, you can minimize downtime, respond faster to incidents, and provide the reliable experience your users expect.
Don't wait for a catastrophic outage to realize the importance of monitoring. Start today, and gain the peace of mind that comes from knowing you'll be the first to know when something goes wrong.