¿Está su inversión en observabilidad realmente protegiendo su negocio, o solo generando más facturas de ingestión de logs?
El dilema entre observabilidad avanzada y monitoreo predictivo ya no es técnico, sino estratégico. En la práctica, muchas decisiones de arquitectura y de inversión en fiabilidad se siguen tomando sobre una confusión conceptual bastante extendida: tratar la observabilidad avanzada y el monitoreo predictivo como si fueran equivalentes, o peor, como si uno pudiera reemplazar por completo al otro.
Para un CTO, esto no es una discusión semántica. Tiene consecuencias directas en presupuesto, complejidad operativa, velocidad de resolución de incidentes y capacidad real de escalar una plataforma sin degradar la experiencia del usuario. A medida que las arquitecturas evolucionan desde aplicaciones relativamente simples hacia ecosistemas distribuidos con microservicios, APIs, colas, workers, dependencias externas y despliegues continuos, el monitoreo deja de ser una función táctica y se convierte en una capa estratégica del negocio.
El problema es que, en ese camino, aparecen dos necesidades distintas. La primera es entender qué pasó y por qué pasó cuando algo se degrada o falla. La segunda es detectar señales tempranas para actuar antes de que el usuario sufra el impacto. La observabilidad avanzada resuelve muy bien la primera. El monitoreo predictivo está diseñado para la segunda.
Por eso el punto central de este artículo es simple, pero importante: no son lo mismo, no compiten y no deberían evaluarse como sustitutos directos. Son capas complementarias dentro de una estrategia moderna de fiabilidad. Una ayuda a observar y entender. La otra ayuda a anticipar y prevenir.
Para líderes de ingeniería, esta diferencia es crítica porque determina cómo se asigna el presupuesto, cómo se construye la plataforma y cómo se reparte la carga cognitiva del equipo. Invertir solo en profundidad sin anticipación puede dejar a la organización atrapada en un modelo reactivo. Invertir solo en anticipación sin contexto puede generar acciones rápidas, pero con diagnósticos incompletos. La combinación correcta, en cambio, puede reducir MTTD, bajar MTTR, mejorar cumplimiento de SLAs y proteger mejor el negocio.
La observabilidad avanzada está diseñada para responder una pregunta muy concreta:
¿Por qué el sistema se está comportando de esta manera?
Ese “por qué” es el núcleo de su valor. Cuando una plataforma entra en un estado inesperado, la observabilidad permite explorar señales internas y reconstruir el comportamiento del sistema con suficiente detalle como para entender la causa técnica del problema.
En términos prácticos, sus capacidades más reconocibles son:
- análisis de logs
- métricas detalladas
- trazas distribuidas
- debugging profundo
- análisis post-incidente
- exploración de dependencias y comportamiento interno
Esto la vuelve especialmente poderosa en entornos distribuidos donde los síntomas visibles rara vez coinciden con la causa real. Un aumento de latencia en el frontend puede originarse en una consulta lenta a base de datos, una dependencia externa degradada, un cambio de configuración o un comportamiento anómalo en una cola interna. La observabilidad avanzada permite seguir ese hilo.
Para un equipo SRE o de plataforma, esto significa poder responder preguntas como:
- ¿En qué servicio empezó la degradación?
- ¿Qué versión estaba corriendo?
- ¿Qué request type estuvo afectado?
- ¿Qué dependencia falló primero?
- ¿Qué cambió respecto al estado normal?
Esa capacidad de inspección profunda tiene un valor enorme, especialmente en debugging, análisis postmortem y mejora estructural del sistema.
Pero su fortaleza también marca su límite. La observabilidad avanzada, en la mayoría de los casos, es más fuerte explicando que anticipando. Es muy buena para dar profundidad, contexto y detalle una vez que el problema ya existe o ya dejó rastros suficientes. En otras palabras, suele ser más reactiva que preventiva.
Además, en muchas implementaciones depende bastante de interpretación humana. Aunque las plataformas modernas ofrecen capacidades de consulta, visualización y cierta asistencia automatizada, el salto desde “aquí hay datos” hasta “esta es la causa más probable y esta debería ser la acción” todavía suele recaer sobre el equipo. Eso implica tiempo, experiencia y madurez operativa.
Si la observabilidad avanzada responde el “por qué”, el monitoreo predictivo responde una pregunta distinta:
¿Qué está empezando a comportarse de forma anómala y qué podría fallar si no actuamos?
Ese cambio de enfoque es fundamental. El monitoreo predictivo no está construido para explicar cada detalle interno de un incidente una vez ocurrido, sino para identificar señales tempranas que preceden degradaciones, saturaciones o fallos visibles.
Sus capacidades clave suelen incluir:
- detección de anomalías
- análisis de patrones históricos
- alertas anticipadas
- identificación de desviaciones respecto al comportamiento normal
- priorización según riesgo o impacto
- correlación automatizada de señales operativas
La fortaleza principal del monitoreo predictivo está en detectar problemas antes de que el usuario los sienta. Un aumento progresivo de latencia, una variación anómala en el p95, errores intermitentes que todavía no cruzan el umbral de alerta, saturación incipiente en una dependencia crítica o un cambio de patrón después de un deployment pueden ser señales suficientes para intervenir antes del daño visible.
Esto tiene implicancias muy concretas para CTOs. Cuando una plataforma puede actuar antes del impacto, no solo mejora sus métricas técnicas. También reduce pérdida de ingresos, protege experiencia de cliente, baja presión sobre el equipo y mejora el cumplimiento operativo.
Su limitación, sin embargo, también es importante: el monitoreo predictivo no siempre explica completamente el “por qué”. Puede decir con mucha precisión que algo está entrando en una zona de riesgo, que cierto flujo está degradándose o que un patrón histórico asociado a incidentes se está repitiendo. Pero eso no significa que siempre pueda ofrecer por sí solo el nivel de detalle forense que una plataforma de observabilidad avanzada sí entrega.
Por eso, un sistema predictivo puede señalar antes, priorizar mejor y reducir tiempo de reacción, pero el análisis profundo del incidente todavía puede requerir capacidades observables más extensas.
La comparación más útil no es filosófica, sino operativa. La siguiente tabla resume cómo se reparte el valor entre ambos enfoques.
| Capacidad | Observabilidad avanzada | Monitoreo predictivo | Ambos |
|---|
| Análisis de logs, métricas y traces | ✔️ | ❌ | |
| Diagnóstico profundo y debugging | ✔️ | ⚠️ Parcial | |
| Detección de anomalías | ⚠️ Limitada o dependiente de herramienta | ✔️ | |
| Anticipación de incidentes | ❌ | ✔️ | |
| Correlación automática de señales | ⚠️ Depende de herramienta y configuración | ✔️ | |
| Prevención de fallos | ❌ | ✔️ | |
| Visión end-to-end | ✔️ | ✔️ | ✔️ |
| Análisis post-incidente | ✔️ | ⚠️ Apoya, pero no reemplaza | |
| Priorización por riesgo operativo | ⚠️ Limitada | ✔️ | |
| Comprensión del contexto arquitectónico | ✔️ | ⚠️ Parcial | |
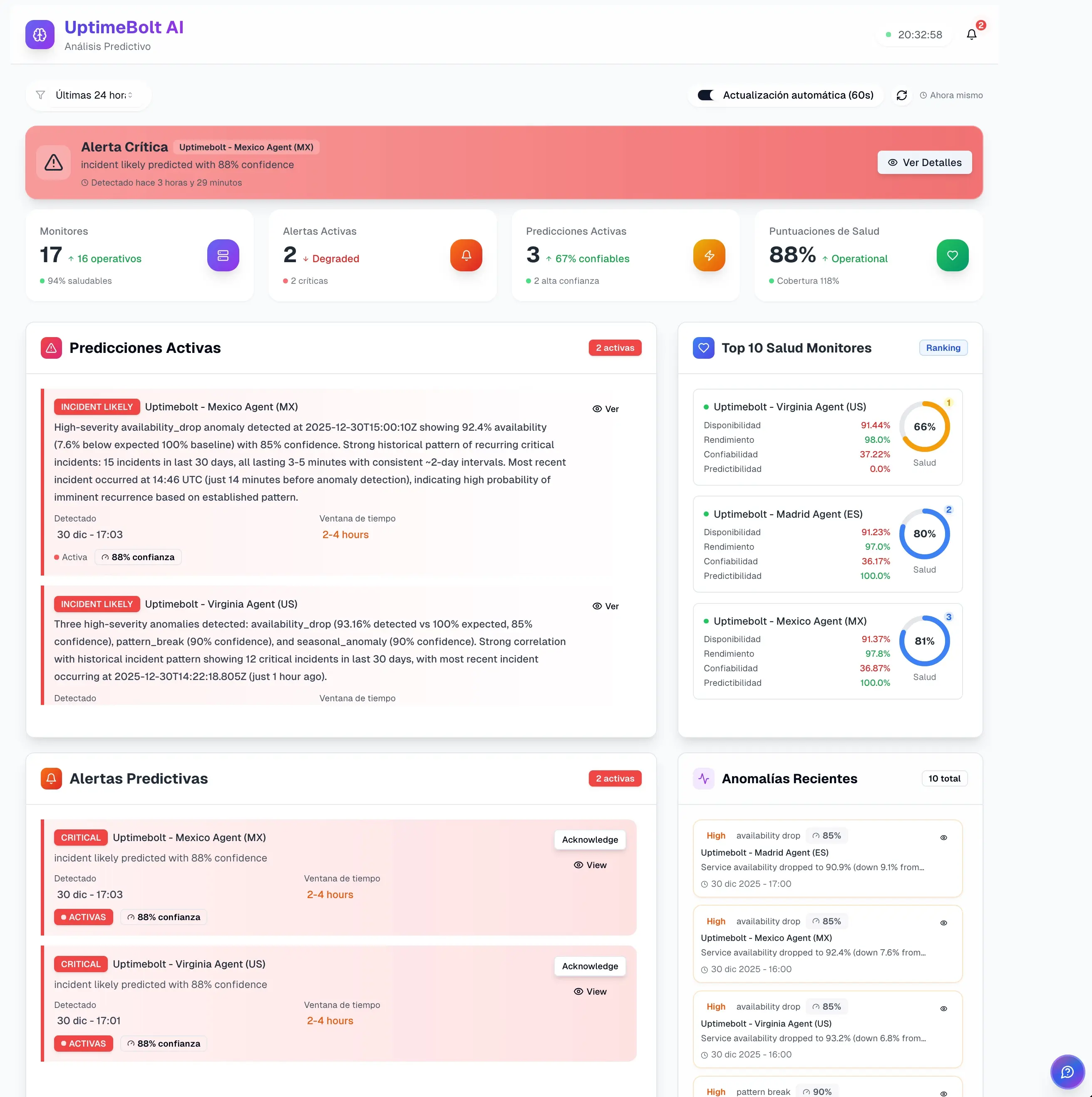
La lectura correcta de esta tabla no es “cuál gana”, sino “qué hueco deja cada una si la uso sola”.
Aquí aparece uno de los puntos más sensibles para cualquier líder de tecnología: el costo total de operar estas capacidades.
La observabilidad avanzada aporta profundidad. Pero esa profundidad suele venir acompañada de costos importantes a escala, especialmente cuando la plataforma se apoya en grandes volúmenes de logs, trazas y datos de ingestión continua.
Herramientas como Datadog o New Relic son reconocidas precisamente por esa riqueza de datos, pero también por cómo ese modelo puede escalar en costos si no se gestiona con rigor.
En contraste, las soluciones de monitoreo predictivo y AIOps priorizan la eficiencia en la ingesta y el procesamiento, enfocándose en extraer señal relevante antes que acumular volumen.
En entornos grandes, el costo no está solo en la licencia o en la plataforma: también está en el tiempo del equipo para gobernar, tunear, consultar, mantener dashboards, optimizar ingestión y evitar que el sistema se convierta en una fábrica de datos con poco valor accionable.
Ese es uno de los grandes dilemas ejecutivos: mucho dato no significa necesariamente más valor. Muchas organizaciones descubren que tienen una observabilidad técnicamente poderosa, pero operativamente costosa. Saben muchísimo del sistema, pero tardan demasiado en convertir esa profundidad en decisiones rápidas.
El monitoreo predictivo, en cambio, suele ser más eficiente en el uso de señales. No necesita necesariamente ingerir toda la profundidad posible de cada capa del stack para generar valor. Su lógica es más selectiva: identificar patrones críticos, detectar anomalías relevantes, anticipar degradaciones y reducir ruido operativo.
Eso no lo hace “mejor” en todos los casos. Lo hace distinto.
Si hubiera que resumirlo en una frase útil para CTOs, sería esta:
Observabilidad equivale a profundidad.
Monitoreo predictivo equivale a eficiencia.
La observabilidad permite entrar más hondo. El monitoreo predictivo permite actuar antes con menos fricción.
Desde la perspectiva de escalabilidad, este equilibrio importa mucho. Equipos pequeños o medianos pueden ahogarse si intentan operar plataformas extremadamente profundas sin automatización suficiente. Equipos más grandes pueden beneficiarse mucho de esa profundidad, pero aun así necesitar una capa predictiva para evitar que todo se vuelva reactivo.
La mejor estrategia no consiste en elegir entre observabilidad avanzada y monitoreo predictivo. Consiste en diseñar cómo trabajan juntas.
- La observabilidad explica el incidente.
- El monitoreo predictivo ayuda a evitar que ocurra o a detectarlo antes de que escale.
Ese es el flujo ideal en operaciones modernas:
- El monitoreo predictivo detecta una anomalía o patrón de riesgo.
- Se genera una alerta anticipada o un incidente contextualizado.
- La observabilidad avanzada permite investigar en profundidad el componente, servicio o dependencia afectada.
- El equipo actúa con mejor información y menos tiempo perdido.
Ese encadenamiento reduce tanto el MTTD como el MTTR.
- Reduce MTTD porque detectas antes.
- Reduce MTTR porque llegas al análisis profundo con una hipótesis mejor orientada.
Además, esta combinación baja el impacto de negocio. Un problema detectado temprano y explicado rápidamente suele requerir menos war room, menos tiempo de exposición y menos fricción para el usuario final.
En otras palabras, la fiabilidad end-to-end no viene de una sola capa tecnológica. Viene de conectar bien la capacidad de anticipar con la capacidad de entender.
Aquí es donde la inteligencia artificial gana un papel especialmente relevante.
La IA no es importante solo porque “automatiza cosas”. Su aporte más útil es que convierte datos dispersos en decisiones operativamente accionables. Funciona como un puente entre la profundidad de la observabilidad y la velocidad del monitoreo predictivo.
- correlación automática de señales
- reducción de ruido operativo
- detección de patrones invisibles para análisis manual
- contextualización de anomalías con cambios recientes, tráfico o dependencias
- priorización por riesgo real y no solo por umbral técnico
Esto es importante porque, en muchos equipos, el verdadero cuello de botella ya no es recolectar datos. Es interpretarlos lo suficientemente rápido como para que el negocio no sufra.
La IA ayuda precisamente ahí. No elimina la necesidad de criterio humano, pero sí reduce trabajo mecánico y acorta el camino entre señal y decisión.
Para un CTO, esta capa tiene un valor claro: permite que la inversión en observabilidad genere más retorno operativo y que el monitoreo deje de ser una cadena de alertas aisladas para convertirse en una herramienta más estratégica.
UptimeBolt se posiciona justamente en ese espacio intermedio donde muchas organizaciones tienen una necesidad no cubierta del todo: no solo observar lo que ocurre, sino interpretar y anticipar.
La plataforma combina:
- monitoreo predictivo integrado
- detección de anomalías
- correlación inteligente de eventos
- visibilidad sobre flujos críticos
- contexto útil para diagnóstico
- lectura operativa de degradaciones y riesgo
Esto significa que correlaciona automáticamente un aumento anómalo de la latencia en el API Gateway con un despliegue reciente en el servicio de autenticación y una caída en el uso de la cache distribuida, identificando la raíz del problema en segundos, en lugar de horas de análisis manual.
Eso significa que no se limita a decir “algo está fallando”. Busca entender qué señales están relacionadas, qué flujo de negocio está en riesgo, si hubo deployments recientes, si una dependencia externa está involucrada y qué patrón previo a incidente se está repitiendo.
Ese es el diferencial más fuerte: no solo observa, interpreta y anticipa.
Desde una perspectiva estratégica, eso le permite complementar capacidades de observabilidad más profundas con una capa enfocada en prevención, priorización y reducción de ruido. No intenta reemplazar toda la profundidad diagnóstica de una plataforma enterprise clásica. Intenta hacer que la operación sea más accionable y menos reactiva.
Para CTOs, ese matiz importa porque evita una falsa dicotomía. No se trata de elegir entre “ver todo” y “anticipar bien”. Se trata de entender dónde una plataforma puede aportar profundidad, dónde puede aportar eficiencia y cómo evitar que la complejidad operativa consuma el valor de ambas.
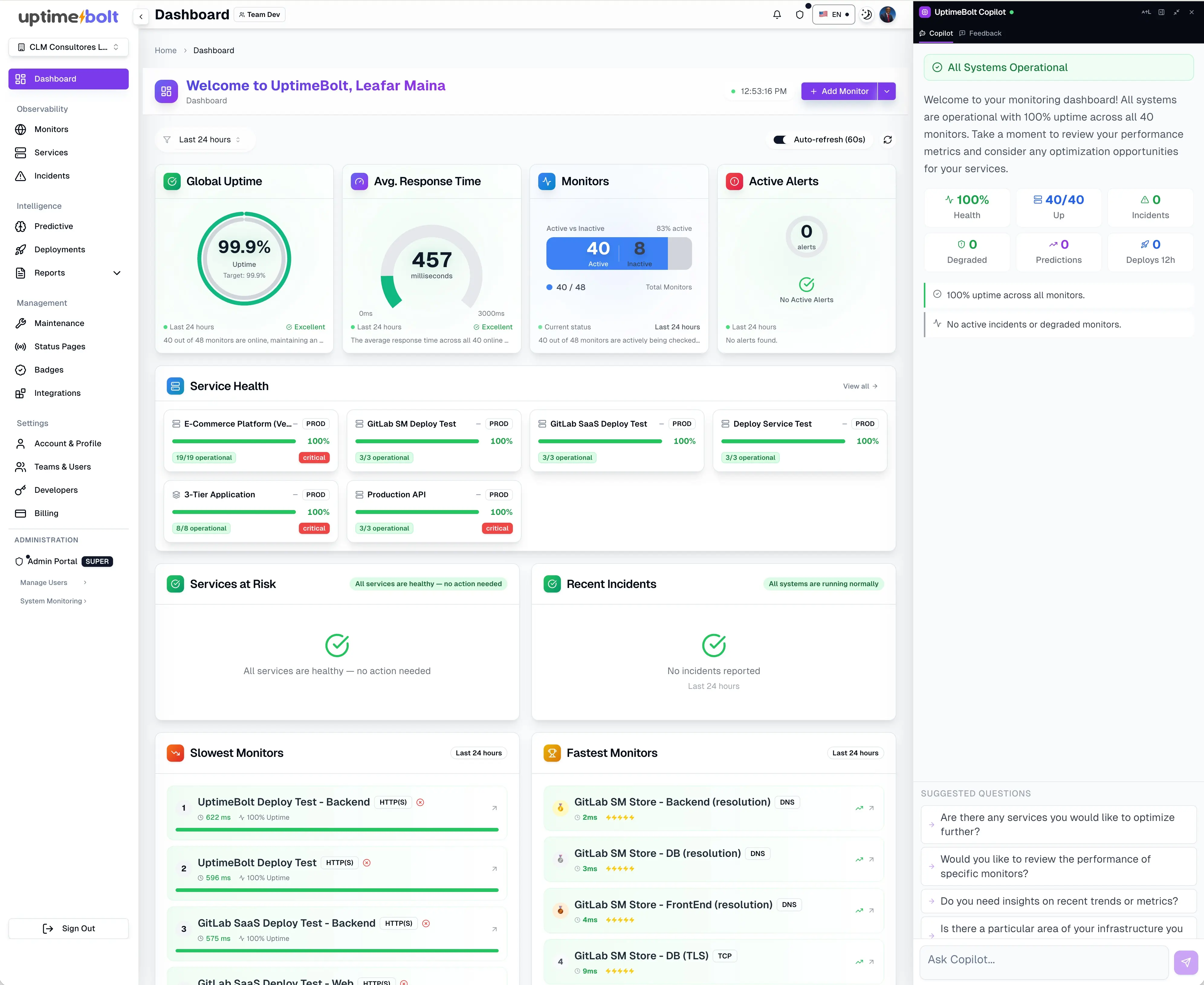
La discusión entre observabilidad avanzada y monitoreo predictivo pierde valor cuando se plantea como competencia. La pregunta correcta no es cuál reemplaza a cuál, sino qué capa de la fiabilidad moderna resuelve cada una.
- La observabilidad avanzada permite observar y entender.
- El monitoreo predictivo permite anticipar y priorizar.
- La IA conecta ambas cosas y acelera el paso desde dato hasta decisión.
Por eso el mensaje final para CTOs es simple, pero importante:
Observabilidad sin predicción deja a la organización demasiado reactiva.
Predicción sin contexto deja a la organización incompleta.
La fiabilidad moderna requiere observar, entender y predecir.
Cuando esas tres capacidades trabajan juntas, los equipos no solo resuelven mejor los incidentes. También reducen ruido, mejoran costos operativos, escalan con más control y protegen mejor la experiencia del usuario y el negocio.
Esa es la diferencia entre tener herramientas de monitoreo y tener una estrategia real de fiabilidad.
Aprenda a aplicar esta estrategia y cómo la tecnología de UptimeBolt puede cerrar el ciclo de fiabilidad en su plataforma.
¿Está su inversión en observabilidad realmente protegiendo su negocio, o solo generando más facturas de ingestión de logs?
El dilema entre observabilidad avanzada y monitoreo predictivo ya no es técnico, sino estratégico. En la práctica, muchas decisiones de arquitectura y de inversión en fiabilidad se siguen tomando sobre una confusión conceptual bastante extendida: tratar la observabilidad avanzada y el monitoreo predictivo como si fueran equivalentes, o peor, como si uno pudiera reemplazar por completo al otro.
Para un CTO, esto no es una discusión semántica. Tiene consecuencias directas en presupuesto, complejidad operativa, velocidad de resolución de incidentes y capacidad real de escalar una plataforma sin degradar la experiencia del usuario. A medida que las arquitecturas evolucionan desde aplicaciones relativamente simples hacia ecosistemas distribuidos con microservicios, APIs, colas, workers, dependencias externas y despliegues continuos, el monitoreo deja de ser una función táctica y se convierte en una capa estratégica del negocio.
El problema es que, en ese camino, aparecen dos necesidades distintas. La primera es entender qué pasó y por qué pasó cuando algo se degrada o falla. La segunda es detectar señales tempranas para actuar antes de que el usuario sufra el impacto. La observabilidad avanzada resuelve muy bien la primera. El monitoreo predictivo está diseñado para la segunda.
Por eso el punto central de este artículo es simple, pero importante: no son lo mismo, no compiten y no deberían evaluarse como sustitutos directos. Son capas complementarias dentro de una estrategia moderna de fiabilidad. Una ayuda a observar y entender. La otra ayuda a anticipar y prevenir.
Para líderes de ingeniería, esta diferencia es crítica porque determina cómo se asigna el presupuesto, cómo se construye la plataforma y cómo se reparte la carga cognitiva del equipo. Invertir solo en profundidad sin anticipación puede dejar a la organización atrapada en un modelo reactivo. Invertir solo en anticipación sin contexto puede generar acciones rápidas, pero con diagnósticos incompletos. La combinación correcta, en cambio, puede reducir MTTD, bajar MTTR, mejorar cumplimiento de SLAs y proteger mejor el negocio.
Qué aporta la observabilidad avanzada: entender el “por qué”
La observabilidad avanzada está diseñada para responder una pregunta muy concreta:
Ese “por qué” es el núcleo de su valor. Cuando una plataforma entra en un estado inesperado, la observabilidad permite explorar señales internas y reconstruir el comportamiento del sistema con suficiente detalle como para entender la causa técnica del problema.
En términos prácticos, sus capacidades más reconocibles son:
Esto la vuelve especialmente poderosa en entornos distribuidos donde los síntomas visibles rara vez coinciden con la causa real. Un aumento de latencia en el frontend puede originarse en una consulta lenta a base de datos, una dependencia externa degradada, un cambio de configuración o un comportamiento anómalo en una cola interna. La observabilidad avanzada permite seguir ese hilo.
Para un equipo SRE o de plataforma, esto significa poder responder preguntas como:
Esa capacidad de inspección profunda tiene un valor enorme, especialmente en debugging, análisis postmortem y mejora estructural del sistema.
Pero su fortaleza también marca su límite. La observabilidad avanzada, en la mayoría de los casos, es más fuerte explicando que anticipando. Es muy buena para dar profundidad, contexto y detalle una vez que el problema ya existe o ya dejó rastros suficientes. En otras palabras, suele ser más reactiva que preventiva.
Además, en muchas implementaciones depende bastante de interpretación humana. Aunque las plataformas modernas ofrecen capacidades de consulta, visualización y cierta asistencia automatizada, el salto desde “aquí hay datos” hasta “esta es la causa más probable y esta debería ser la acción” todavía suele recaer sobre el equipo. Eso implica tiempo, experiencia y madurez operativa.
Qué aporta el monitoreo predictivo: anticipar antes del impacto
Si la observabilidad avanzada responde el “por qué”, el monitoreo predictivo responde una pregunta distinta:
Ese cambio de enfoque es fundamental. El monitoreo predictivo no está construido para explicar cada detalle interno de un incidente una vez ocurrido, sino para identificar señales tempranas que preceden degradaciones, saturaciones o fallos visibles.
Sus capacidades clave suelen incluir:
La fortaleza principal del monitoreo predictivo está en detectar problemas antes de que el usuario los sienta. Un aumento progresivo de latencia, una variación anómala en el p95, errores intermitentes que todavía no cruzan el umbral de alerta, saturación incipiente en una dependencia crítica o un cambio de patrón después de un deployment pueden ser señales suficientes para intervenir antes del daño visible.
Esto tiene implicancias muy concretas para CTOs. Cuando una plataforma puede actuar antes del impacto, no solo mejora sus métricas técnicas. También reduce pérdida de ingresos, protege experiencia de cliente, baja presión sobre el equipo y mejora el cumplimiento operativo.
Su limitación, sin embargo, también es importante: el monitoreo predictivo no siempre explica completamente el “por qué”. Puede decir con mucha precisión que algo está entrando en una zona de riesgo, que cierto flujo está degradándose o que un patrón histórico asociado a incidentes se está repitiendo. Pero eso no significa que siempre pueda ofrecer por sí solo el nivel de detalle forense que una plataforma de observabilidad avanzada sí entrega.
Por eso, un sistema predictivo puede señalar antes, priorizar mejor y reducir tiempo de reacción, pero el análisis profundo del incidente todavía puede requerir capacidades observables más extensas.
Comparación clara para CTOs
La comparación más útil no es filosófica, sino operativa. La siguiente tabla resume cómo se reparte el valor entre ambos enfoques.
La lectura correcta de esta tabla no es “cuál gana”, sino “qué hueco deja cada una si la uso sola”.
Costos y eficiencia: lo que los CTOs deben considerar
Aquí aparece uno de los puntos más sensibles para cualquier líder de tecnología: el costo total de operar estas capacidades.
La observabilidad avanzada aporta profundidad. Pero esa profundidad suele venir acompañada de costos importantes a escala, especialmente cuando la plataforma se apoya en grandes volúmenes de logs, trazas y datos de ingestión continua.
Herramientas como Datadog o New Relic son reconocidas precisamente por esa riqueza de datos, pero también por cómo ese modelo puede escalar en costos si no se gestiona con rigor.
En contraste, las soluciones de monitoreo predictivo y AIOps priorizan la eficiencia en la ingesta y el procesamiento, enfocándose en extraer señal relevante antes que acumular volumen.
En entornos grandes, el costo no está solo en la licencia o en la plataforma: también está en el tiempo del equipo para gobernar, tunear, consultar, mantener dashboards, optimizar ingestión y evitar que el sistema se convierta en una fábrica de datos con poco valor accionable.
Ese es uno de los grandes dilemas ejecutivos: mucho dato no significa necesariamente más valor. Muchas organizaciones descubren que tienen una observabilidad técnicamente poderosa, pero operativamente costosa. Saben muchísimo del sistema, pero tardan demasiado en convertir esa profundidad en decisiones rápidas.
El monitoreo predictivo, en cambio, suele ser más eficiente en el uso de señales. No necesita necesariamente ingerir toda la profundidad posible de cada capa del stack para generar valor. Su lógica es más selectiva: identificar patrones críticos, detectar anomalías relevantes, anticipar degradaciones y reducir ruido operativo.
Eso no lo hace “mejor” en todos los casos. Lo hace distinto.
Si hubiera que resumirlo en una frase útil para CTOs, sería esta:
La observabilidad permite entrar más hondo. El monitoreo predictivo permite actuar antes con menos fricción.
Desde la perspectiva de escalabilidad, este equilibrio importa mucho. Equipos pequeños o medianos pueden ahogarse si intentan operar plataformas extremadamente profundas sin automatización suficiente. Equipos más grandes pueden beneficiarse mucho de esa profundidad, pero aun así necesitar una capa predictiva para evitar que todo se vuelva reactivo.
Cómo se complementan para ofrecer fiabilidad end-to-end
La mejor estrategia no consiste en elegir entre observabilidad avanzada y monitoreo predictivo. Consiste en diseñar cómo trabajan juntas.
Ese es el flujo ideal en operaciones modernas:
Ese encadenamiento reduce tanto el MTTD como el MTTR.
Además, esta combinación baja el impacto de negocio. Un problema detectado temprano y explicado rápidamente suele requerir menos war room, menos tiempo de exposición y menos fricción para el usuario final.
En otras palabras, la fiabilidad end-to-end no viene de una sola capa tecnológica. Viene de conectar bien la capacidad de anticipar con la capacidad de entender.
La IA como puente entre observabilidad y prevención
Aquí es donde la inteligencia artificial gana un papel especialmente relevante.
La IA no es importante solo porque “automatiza cosas”. Su aporte más útil es que convierte datos dispersos en decisiones operativamente accionables. Funciona como un puente entre la profundidad de la observabilidad y la velocidad del monitoreo predictivo.
¿Dónde agrega valor concreto?
Esto es importante porque, en muchos equipos, el verdadero cuello de botella ya no es recolectar datos. Es interpretarlos lo suficientemente rápido como para que el negocio no sufra.
La IA ayuda precisamente ahí. No elimina la necesidad de criterio humano, pero sí reduce trabajo mecánico y acorta el camino entre señal y decisión.
Para un CTO, esta capa tiene un valor claro: permite que la inversión en observabilidad genere más retorno operativo y que el monitoreo deje de ser una cadena de alertas aisladas para convertirse en una herramienta más estratégica.
Cómo UptimeBolt potencia ambas capacidades en una sola plataforma
UptimeBolt se posiciona justamente en ese espacio intermedio donde muchas organizaciones tienen una necesidad no cubierta del todo: no solo observar lo que ocurre, sino interpretar y anticipar.
La plataforma combina:
Esto significa que correlaciona automáticamente un aumento anómalo de la latencia en el API Gateway con un despliegue reciente en el servicio de autenticación y una caída en el uso de la cache distribuida, identificando la raíz del problema en segundos, en lugar de horas de análisis manual.
Eso significa que no se limita a decir “algo está fallando”. Busca entender qué señales están relacionadas, qué flujo de negocio está en riesgo, si hubo deployments recientes, si una dependencia externa está involucrada y qué patrón previo a incidente se está repitiendo.
Ese es el diferencial más fuerte: no solo observa, interpreta y anticipa.
Desde una perspectiva estratégica, eso le permite complementar capacidades de observabilidad más profundas con una capa enfocada en prevención, priorización y reducción de ruido. No intenta reemplazar toda la profundidad diagnóstica de una plataforma enterprise clásica. Intenta hacer que la operación sea más accionable y menos reactiva.
Para CTOs, ese matiz importa porque evita una falsa dicotomía. No se trata de elegir entre “ver todo” y “anticipar bien”. Se trata de entender dónde una plataforma puede aportar profundidad, dónde puede aportar eficiencia y cómo evitar que la complejidad operativa consuma el valor de ambas.
Conclusión
La discusión entre observabilidad avanzada y monitoreo predictivo pierde valor cuando se plantea como competencia. La pregunta correcta no es cuál reemplaza a cuál, sino qué capa de la fiabilidad moderna resuelve cada una.
Por eso el mensaje final para CTOs es simple, pero importante:
Cuando esas tres capacidades trabajan juntas, los equipos no solo resuelven mejor los incidentes. También reducen ruido, mejoran costos operativos, escalan con más control y protegen mejor la experiencia del usuario y el negocio.
Esa es la diferencia entre tener herramientas de monitoreo y tener una estrategia real de fiabilidad.
Aprenda a aplicar esta estrategia y cómo la tecnología de UptimeBolt puede cerrar el ciclo de fiabilidad en su plataforma.