Las APIs se han convertido en la columna vertebral de las aplicaciones modernas. Desde plataformas de e-commerce y sistemas fintech hasta soluciones SaaS y arquitecturas basadas en microservicios, prácticamente toda experiencia digital depende de múltiples APIs funcionando de forma correcta, rápida y consistente. Sin embargo, muchas organizaciones todavía miden su “uptime” únicamente desde la disponibilidad de servidores o desde la capa frontend, sin visibilidad real de lo que ocurre en las APIs que sostienen los flujos críticos del negocio.
El problema es claro: una aplicación puede estar “en línea” y aun así fallar para los usuarios finales si una API responde lentamente, devuelve errores intermitentes o se degrada bajo carga. En estos casos, el downtime no siempre es absoluto; suele manifestarse como degradación silenciosa, transacciones fallidas, errores parciales o experiencias inconsistentes que impactan directamente en ingresos, confianza y reputación.
Aquí es donde el monitoreo de APIs juega un rol crítico. No se trata solo de saber si un endpoint responde, sino de entender cómo se comporta, qué tan rápido lo hace, con qué calidad devuelve los datos y cómo evoluciona su desempeño en el tiempo. El monitoreo de APIs permite pasar de una visión reactiva del uptime a una gestión proactiva y predictiva de la fiabilidad digital.
El monitoreo de APIs es el proceso de observar, medir y validar de forma continua el comportamiento de las interfaces de programación que conectan servicios, sistemas y aplicaciones. A diferencia del monitoreo tradicional de infraestructura, que se enfoca en servidores, CPU o memoria, el monitoreo de APIs se centra en la capa lógica donde realmente ocurren las transacciones de negocio.
En términos prácticos, un monitor de APIs ejecuta solicitudes programadas a endpoints específicos y analiza la respuesta. Estas solicitudes pueden simular llamadas reales de clientes, aplicaciones móviles, sistemas externos o microservicios internos. El monitor valida no solo que la API responda, sino que lo haga correctamente según parámetros definidos: tiempo de respuesta, códigos de estado, estructura del payload, valores esperados y comportamiento bajo distintos escenarios.
Así, el monitoreo de infraestructura es ver el motor encendido, y el de APIs es ver si el auto realmente avanza y toma la ruta correcta.
El funcionamiento típico incluye la ejecución periódica de requests desde distintas ubicaciones geográficas, la medición de métricas clave, la comparación contra umbrales y la generación de alertas cuando se detectan anomalías. A lo largo del tiempo, esta información se transforma en series históricas que permiten identificar tendencias, degradaciones progresivas y patrones que anticipan incidentes.
Un punto clave es que el monitoreo de APIs no reemplaza las pruebas de desarrollo ni la observabilidad interna, sino que las complementa desde una perspectiva externa y centrada en el uptime real. Mientras las pruebas validan funcionalidad antes del despliegue, el monitoreo garantiza que esa funcionalidad se mantenga estable en producción.
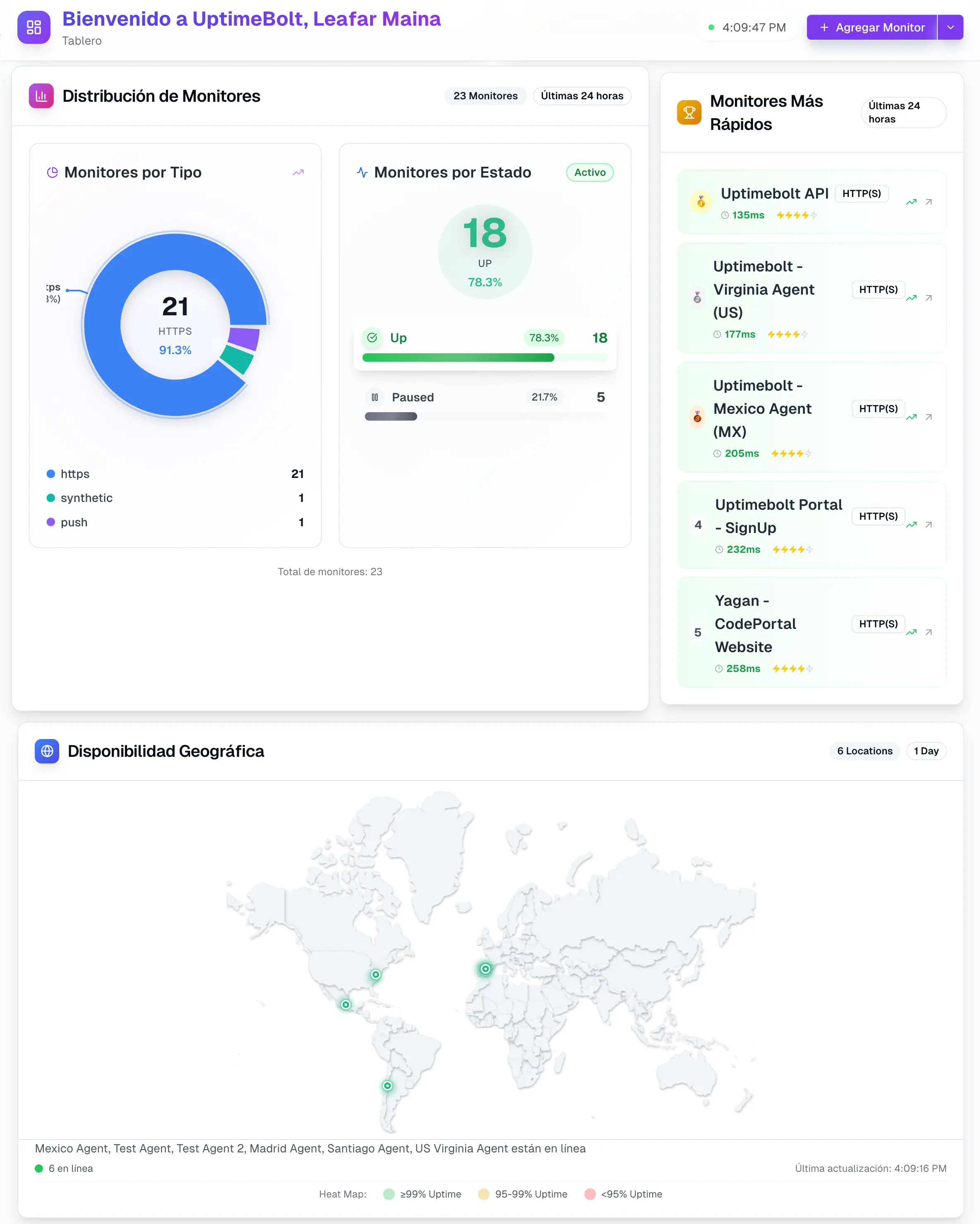
Para que el monitoreo de APIs sea realmente efectivo, no basta con comprobar disponibilidad básica. Existen métricas críticas que deben analizarse de forma conjunta para obtener una visión completa del estado de una API.
Es una de las métricas más importantes. Mide cuánto tiempo tarda la API en responder desde que recibe una solicitud hasta que entrega una respuesta completa. Incrementos graduales en la latencia suelen ser la primera señal de saturación, problemas de base de datos, dependencias lentas o cuellos de botella internos. Incluso cuando la API no “cae”, una latencia elevada puede romper la experiencia del usuario final.
Proporcionan información directa sobre el estado lógico de la API. Errores 4xx pueden indicar problemas de validación, cambios incompatibles o clientes mal configurados, mientras que errores 5xx suelen revelar fallos internos del servicio. El monitoreo debe identificar no solo la presencia de errores, sino su frecuencia, distribución y evolución en el tiempo.
Son especialmente peligrosos porque muchas veces no se registran como errores explícitos. Una API que no responde dentro de un tiempo aceptable puede bloquear flujos completos, generar reintentos en cascada y amplificar el impacto en otros servicios. Detectar timeouts de forma temprana es clave para evitar fallos sistémicos.
También conocido como contenido de la respuesta, es otra dimensión crítica. Una API puede responder con código 200 pero devolver datos incompletos, mal formateados o inconsistentes. El monitoreo avanzado valida esquemas, campos obligatorios, valores esperados y reglas de negocio básicas, asegurando que la respuesta no solo exista, sino que sea correcta y útil.
No todas las APIs son iguales, y cada tipo presenta desafíos específicos de monitoreo. Comprender estas diferencias es fundamental para diseñar una estrategia efectiva.
Las APIs REST son las más comunes y generalmente operan sobre HTTP con métodos estándar como GET, POST, PUT y DELETE. Su monitoreo suele centrarse en endpoints individuales, autenticación, códigos de estado y payloads JSON. Aunque parecen simples, su dependencia de múltiples servicios internos puede ocultar fallos complejos.
Las APIs GraphQL introducen un enfoque distinto, donde una sola consulta puede resolver múltiples recursos. Esto hace que la latencia y el payload sean aún más críticos, ya que una consulta mal optimizada puede generar respuestas lentas o excesivamente grandes. El monitoreo debe considerar consultas representativas y validar tanto la estructura como el rendimiento.
Las APIs SOAP, aún presentes en entornos empresariales y financieros, requieren validación de mensajes XML, esquemas estrictos y contratos bien definidos. Pequeños cambios o incompatibilidades pueden generar errores difíciles de diagnosticar sin monitoreo especializado.
Los webhooks representan un caso particular, ya que la comunicación es inversa: la API externa envía eventos a tu sistema. Aquí el monitoreo debe validar recepción, tiempos de procesamiento y manejo de fallos, asegurando que los eventos no se pierdan ni se procesen con retraso.
Cada uno de estos tipos requiere configuraciones, métricas y validaciones específicas. Un enfoque genérico de “ping” es insuficiente para garantizar uptime real en arquitecturas modernas.
El monitoreo de APIs permite detectar una amplia gama de problemas que suelen pasar desapercibidos con enfoques tradicionales.
Uno de los más frecuentes es la degradación progresiva del rendimiento. Antes de una caída total, muchas APIs comienzan a responder cada vez más lento, afectando gradualmente a los usuarios.
Otro problema común son los errores intermitentes. Una API puede fallar solo bajo ciertas condiciones, volúmenes de tráfico o dependencias externas. Estos fallos son difíciles de reproducir manualmente, pero el monitoreo continuo los expone rápidamente.
Los cambios no documentados o despliegues defectuosos también se reflejan en el monitoreo. Modificaciones en el payload, campos eliminados o cambios en la lógica de negocio pueden romper integraciones sin generar una caída evidente. La validación automática del contenido permite detectar estos problemas de inmediato.
Las dependencias externas son otra fuente frecuente de incidentes. Muchas APIs dependen de terceros para pagos, autenticación, logística o datos. Cuando uno de estos servicios se degrada, el impacto se propaga. El monitoreo ayuda a identificar si el problema es interno o externo y a responder con mayor precisión.
Desde un punto de vista operativo, el monitoreo de APIs reduce significativamente el downtime y el tiempo de resolución de incidentes. Al detectar problemas antes de que escalen, los equipos pueden actuar de forma preventiva en lugar de reactiva.
La visibilidad continua proporciona mayor control sobre sistemas complejos. Los equipos DevOps y SRE dejan de depender exclusivamente de alertas tardías o quejas de usuarios y pasan a gestionar la fiabilidad con datos objetivos y en tiempo real.
Para el usuario final, esto se traduce en experiencias más consistentes y confiables: menos errores en pagos, menos fallos en login y menos operaciones incompletas. En entornos competitivos, esta estabilidad se convierte en una ventaja clara frente a alternativas menos confiables.
En e-commerce, cada API caída o degradada puede significar carritos abandonados y pérdidas directas de ingresos. El monitoreo de APIs permite asegurar flujos críticos como búsqueda, checkout, pagos y confirmaciones, incluso durante picos de tráfico.
En fintech, donde la confiabilidad y la precisión son esenciales, el monitoreo reduce riesgos operativos y regulatorios. Detectar errores en transacciones, validaciones o integraciones bancarias antes de que afecten a clientes es fundamental para mantener la confianza.
En modelos SaaS, la disponibilidad percibida es parte central de la propuesta de valor. Los clientes esperan servicios siempre disponibles y rápidos. El monitoreo de APIs permite cumplir SLAs, justificar métricas de uptime y diferenciarse por calidad operativa.
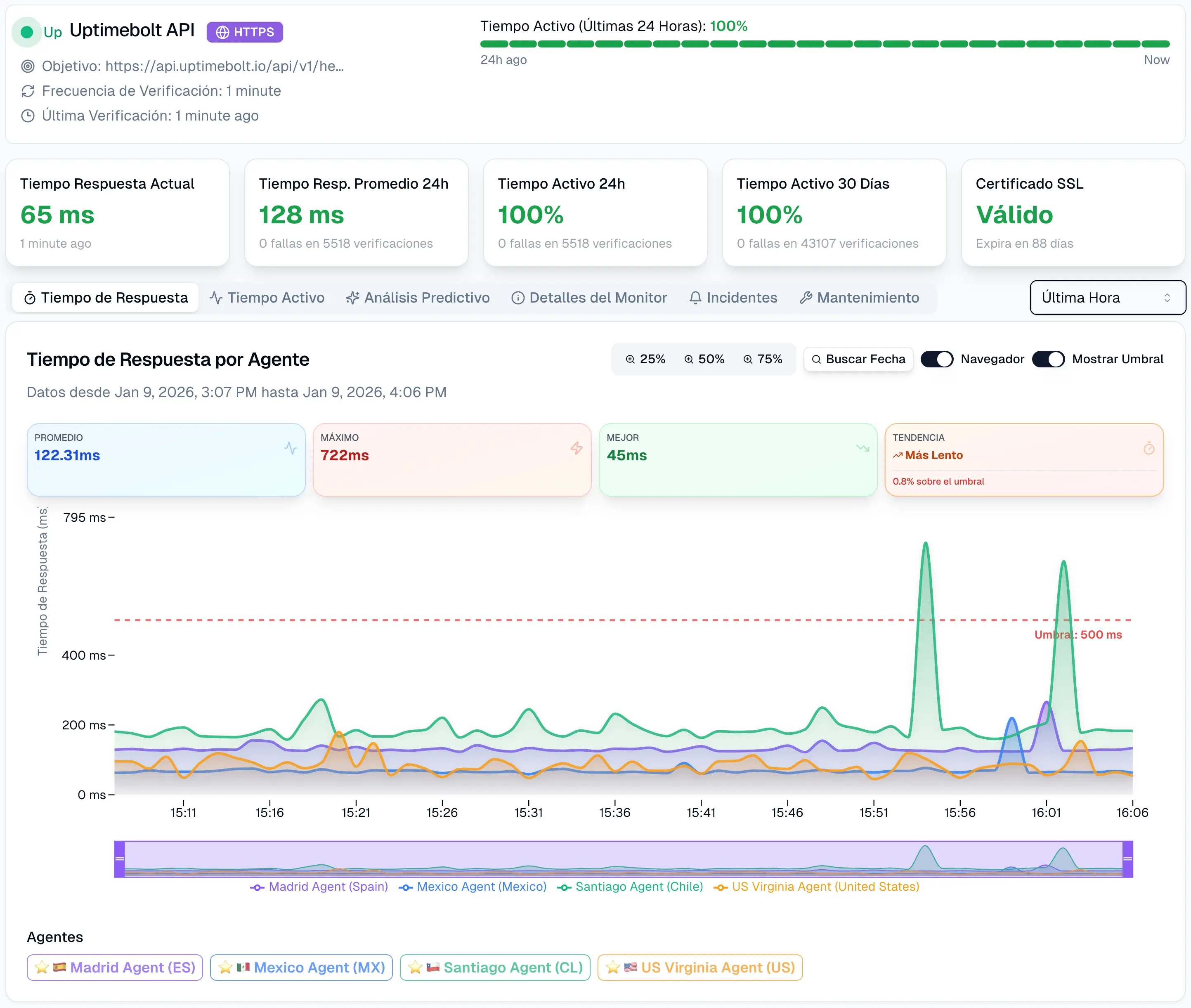
UptimeBolt aborda el monitoreo de APIs desde una perspectiva profunda y predictiva. No se limita a verificar si un endpoint responde, sino que ejecuta validaciones completas de comportamiento, rendimiento y contenido, simulando escenarios reales de uso.
La plataforma permite definir monitores avanzados para distintos tipos de APIs, configurar umbrales dinámicos y analizar tendencias históricas. Mediante el análisis continuo de latencia, errores y patrones de respuesta, UptimeBolt identifica señales tempranas de degradación antes de que se conviertan en incidentes visibles.
Además, el monitoreo distribuido desde múltiples ubicaciones ayuda a detectar problemas regionales, dependencias externas y fallos de red. Las alertas inteligentes reducen el ruido y priorizan los eventos.
En arquitecturas modernas, el uptime real no se define por servidores encendidos o dashboards verdes, sino por APIs funcionando correctamente para los usuarios. Sin monitoreo de APIs, las organizaciones operan a ciegas, reaccionando tarde y asumiendo riesgos innecesarios.
El monitoreo de APIs es una práctica esencial para asegurar fiabilidad, rendimiento y continuidad del negocio. Permite detectar degradaciones silenciosas, prevenir incidentes y ofrecer experiencias digitales consistentes. En un entorno donde cada interacción depende de múltiples servicios conectados, una API sin monitoreo simplemente no puede garantizar uptime real.
Las APIs se han convertido en la columna vertebral de las aplicaciones modernas. Desde plataformas de e-commerce y sistemas fintech hasta soluciones SaaS y arquitecturas basadas en microservicios, prácticamente toda experiencia digital depende de múltiples APIs funcionando de forma correcta, rápida y consistente. Sin embargo, muchas organizaciones todavía miden su “uptime” únicamente desde la disponibilidad de servidores o desde la capa frontend, sin visibilidad real de lo que ocurre en las APIs que sostienen los flujos críticos del negocio.
El problema es claro: una aplicación puede estar “en línea” y aun así fallar para los usuarios finales si una API responde lentamente, devuelve errores intermitentes o se degrada bajo carga. En estos casos, el downtime no siempre es absoluto; suele manifestarse como degradación silenciosa, transacciones fallidas, errores parciales o experiencias inconsistentes que impactan directamente en ingresos, confianza y reputación.
Aquí es donde el monitoreo de APIs juega un rol crítico. No se trata solo de saber si un endpoint responde, sino de entender cómo se comporta, qué tan rápido lo hace, con qué calidad devuelve los datos y cómo evoluciona su desempeño en el tiempo. El monitoreo de APIs permite pasar de una visión reactiva del uptime a una gestión proactiva y predictiva de la fiabilidad digital.
Qué es el monitoreo de APIs y cómo funciona
El monitoreo de APIs es el proceso de observar, medir y validar de forma continua el comportamiento de las interfaces de programación que conectan servicios, sistemas y aplicaciones. A diferencia del monitoreo tradicional de infraestructura, que se enfoca en servidores, CPU o memoria, el monitoreo de APIs se centra en la capa lógica donde realmente ocurren las transacciones de negocio.
En términos prácticos, un monitor de APIs ejecuta solicitudes programadas a endpoints específicos y analiza la respuesta. Estas solicitudes pueden simular llamadas reales de clientes, aplicaciones móviles, sistemas externos o microservicios internos. El monitor valida no solo que la API responda, sino que lo haga correctamente según parámetros definidos: tiempo de respuesta, códigos de estado, estructura del payload, valores esperados y comportamiento bajo distintos escenarios.
Así, el monitoreo de infraestructura es ver el motor encendido, y el de APIs es ver si el auto realmente avanza y toma la ruta correcta.
El funcionamiento típico incluye la ejecución periódica de requests desde distintas ubicaciones geográficas, la medición de métricas clave, la comparación contra umbrales y la generación de alertas cuando se detectan anomalías. A lo largo del tiempo, esta información se transforma en series históricas que permiten identificar tendencias, degradaciones progresivas y patrones que anticipan incidentes.
Un punto clave es que el monitoreo de APIs no reemplaza las pruebas de desarrollo ni la observabilidad interna, sino que las complementa desde una perspectiva externa y centrada en el uptime real. Mientras las pruebas validan funcionalidad antes del despliegue, el monitoreo garantiza que esa funcionalidad se mantenga estable en producción.
Métricas clave a monitorear: latencia, códigos de error, timeouts, payload
Para que el monitoreo de APIs sea realmente efectivo, no basta con comprobar disponibilidad básica. Existen métricas críticas que deben analizarse de forma conjunta para obtener una visión completa del estado de una API.
Latencia
Es una de las métricas más importantes. Mide cuánto tiempo tarda la API en responder desde que recibe una solicitud hasta que entrega una respuesta completa. Incrementos graduales en la latencia suelen ser la primera señal de saturación, problemas de base de datos, dependencias lentas o cuellos de botella internos. Incluso cuando la API no “cae”, una latencia elevada puede romper la experiencia del usuario final.
Códigos de error
Proporcionan información directa sobre el estado lógico de la API. Errores 4xx pueden indicar problemas de validación, cambios incompatibles o clientes mal configurados, mientras que errores 5xx suelen revelar fallos internos del servicio. El monitoreo debe identificar no solo la presencia de errores, sino su frecuencia, distribución y evolución en el tiempo.
Timeouts
Son especialmente peligrosos porque muchas veces no se registran como errores explícitos. Una API que no responde dentro de un tiempo aceptable puede bloquear flujos completos, generar reintentos en cascada y amplificar el impacto en otros servicios. Detectar timeouts de forma temprana es clave para evitar fallos sistémicos.
Payload
También conocido como contenido de la respuesta, es otra dimensión crítica. Una API puede responder con código 200 pero devolver datos incompletos, mal formateados o inconsistentes. El monitoreo avanzado valida esquemas, campos obligatorios, valores esperados y reglas de negocio básicas, asegurando que la respuesta no solo exista, sino que sea correcta y útil.
Tipos de APIs y por qué su monitoreo es diferente
No todas las APIs son iguales, y cada tipo presenta desafíos específicos de monitoreo. Comprender estas diferencias es fundamental para diseñar una estrategia efectiva.
Las APIs REST son las más comunes y generalmente operan sobre HTTP con métodos estándar como GET, POST, PUT y DELETE. Su monitoreo suele centrarse en endpoints individuales, autenticación, códigos de estado y payloads JSON. Aunque parecen simples, su dependencia de múltiples servicios internos puede ocultar fallos complejos.
Las APIs GraphQL introducen un enfoque distinto, donde una sola consulta puede resolver múltiples recursos. Esto hace que la latencia y el payload sean aún más críticos, ya que una consulta mal optimizada puede generar respuestas lentas o excesivamente grandes. El monitoreo debe considerar consultas representativas y validar tanto la estructura como el rendimiento.
Las APIs SOAP, aún presentes en entornos empresariales y financieros, requieren validación de mensajes XML, esquemas estrictos y contratos bien definidos. Pequeños cambios o incompatibilidades pueden generar errores difíciles de diagnosticar sin monitoreo especializado.
Los webhooks representan un caso particular, ya que la comunicación es inversa: la API externa envía eventos a tu sistema. Aquí el monitoreo debe validar recepción, tiempos de procesamiento y manejo de fallos, asegurando que los eventos no se pierdan ni se procesen con retraso.
Cada uno de estos tipos requiere configuraciones, métricas y validaciones específicas. Un enfoque genérico de “ping” es insuficiente para garantizar uptime real en arquitecturas modernas.
Problemas más comunes detectados por monitores de API
El monitoreo de APIs permite detectar una amplia gama de problemas que suelen pasar desapercibidos con enfoques tradicionales.
Uno de los más frecuentes es la degradación progresiva del rendimiento. Antes de una caída total, muchas APIs comienzan a responder cada vez más lento, afectando gradualmente a los usuarios.
Otro problema común son los errores intermitentes. Una API puede fallar solo bajo ciertas condiciones, volúmenes de tráfico o dependencias externas. Estos fallos son difíciles de reproducir manualmente, pero el monitoreo continuo los expone rápidamente.
Los cambios no documentados o despliegues defectuosos también se reflejan en el monitoreo. Modificaciones en el payload, campos eliminados o cambios en la lógica de negocio pueden romper integraciones sin generar una caída evidente. La validación automática del contenido permite detectar estos problemas de inmediato.
Las dependencias externas son otra fuente frecuente de incidentes. Muchas APIs dependen de terceros para pagos, autenticación, logística o datos. Cuando uno de estos servicios se degrada, el impacto se propaga. El monitoreo ayuda a identificar si el problema es interno o externo y a responder con mayor precisión.
Beneficios operativos: menos downtime, más control, mejor experiencia del usuario
Desde un punto de vista operativo, el monitoreo de APIs reduce significativamente el downtime y el tiempo de resolución de incidentes. Al detectar problemas antes de que escalen, los equipos pueden actuar de forma preventiva en lugar de reactiva.
La visibilidad continua proporciona mayor control sobre sistemas complejos. Los equipos DevOps y SRE dejan de depender exclusivamente de alertas tardías o quejas de usuarios y pasan a gestionar la fiabilidad con datos objetivos y en tiempo real.
Para el usuario final, esto se traduce en experiencias más consistentes y confiables: menos errores en pagos, menos fallos en login y menos operaciones incompletas. En entornos competitivos, esta estabilidad se convierte en una ventaja clara frente a alternativas menos confiables.
Beneficios estratégicos para e-commerce, fintech y SaaS
En e-commerce, cada API caída o degradada puede significar carritos abandonados y pérdidas directas de ingresos. El monitoreo de APIs permite asegurar flujos críticos como búsqueda, checkout, pagos y confirmaciones, incluso durante picos de tráfico.
En fintech, donde la confiabilidad y la precisión son esenciales, el monitoreo reduce riesgos operativos y regulatorios. Detectar errores en transacciones, validaciones o integraciones bancarias antes de que afecten a clientes es fundamental para mantener la confianza.
En modelos SaaS, la disponibilidad percibida es parte central de la propuesta de valor. Los clientes esperan servicios siempre disponibles y rápidos. El monitoreo de APIs permite cumplir SLAs, justificar métricas de uptime y diferenciarse por calidad operativa.
Cómo UptimeBolt realiza monitoreo predictivo de APIs
UptimeBolt aborda el monitoreo de APIs desde una perspectiva profunda y predictiva. No se limita a verificar si un endpoint responde, sino que ejecuta validaciones completas de comportamiento, rendimiento y contenido, simulando escenarios reales de uso.
La plataforma permite definir monitores avanzados para distintos tipos de APIs, configurar umbrales dinámicos y analizar tendencias históricas. Mediante el análisis continuo de latencia, errores y patrones de respuesta, UptimeBolt identifica señales tempranas de degradación antes de que se conviertan en incidentes visibles.
Además, el monitoreo distribuido desde múltiples ubicaciones ayuda a detectar problemas regionales, dependencias externas y fallos de red. Las alertas inteligentes reducen el ruido y priorizan los eventos.
Conclusión: Una API sin monitoreo no puede garantizar uptime real
En arquitecturas modernas, el uptime real no se define por servidores encendidos o dashboards verdes, sino por APIs funcionando correctamente para los usuarios. Sin monitoreo de APIs, las organizaciones operan a ciegas, reaccionando tarde y asumiendo riesgos innecesarios.
El monitoreo de APIs es una práctica esencial para asegurar fiabilidad, rendimiento y continuidad del negocio. Permite detectar degradaciones silenciosas, prevenir incidentes y ofrecer experiencias digitales consistentes. En un entorno donde cada interacción depende de múltiples servicios conectados, una API sin monitoreo simplemente no puede garantizar uptime real.