El 80% de los fallos de rendimiento y seguridad se origina en procesos internos y en segundo plano, no en los componentes visibles para el usuario. Sin embargo, estos procesos suelen quedar fuera del radar de muchas estrategias de monitoreo modernas.
El heartbeat monitoring es una de las prácticas más subestimadas —y a la vez más críticas— dentro del monitoreo moderno. Mientras la mayoría de los equipos se enfoca en monitorear sitios web, APIs o flujos visibles para el usuario, muchos de los fallos más graves ocurren dentro del sistema, en procesos que no tienen interfaz, no responden a HTTP y no generan errores evidentes.
Workers que dejan de ejecutarse, cron jobs que fallan silenciosamente, pipelines que se quedan atascados o microservicios event-driven que dejan de procesar mensajes pueden provocar impactos operativos y de negocio enormes sin disparar ninguna alerta tradicional. Aquí es donde el heartbeat monitoring se vuelve esencial.
Esta guía explica en profundidad qué son los heartbeat monitors, cómo funcionan, cuándo utilizarlos, qué tipo de fallos detectan y cómo integrarlos correctamente en equipos de desarrollo modernos, para pasar de una observabilidad reactiva a un control real de la salud interna del sistema.
Un heartbeat monitor es un tipo de monitoreo activo diseñado para validar que un proceso interno sigue vivo y ejecutándose como se espera. En lugar de “preguntar” a un servicio si está disponible, el heartbeat espera recibir señales periódicas (“latidos”) desde el propio proceso monitoreado.
Si esa señal no llega dentro del intervalo esperado, el sistema asume que algo no está funcionando correctamente y genera una alerta.
El heartbeat monitoring es esencial porque cubre un tipo de riesgo que otros monitores no pueden detectar: los fallos silenciosos. Estos fallos no siempre generan errores visibles, pero pueden detener operaciones críticas durante horas sin que nadie lo note.
A diferencia de un monitor web o de API, el heartbeat monitoring funciona de manera inversa. No es el sistema de monitoreo quien consulta al servicio, sino el servicio quien “avisa” periódicamente que sigue activo.
Flujo típico:
- Un proceso (worker, job, pipeline, microservicio) envía una señal periódica
- El sistema de monitoreo espera esa señal dentro de un intervalo definido
- Si la señal llega a tiempo, todo está correcto
- Si la señal no llega, se genera una alerta
Lo que valida un heartbeat monitor no es solo que el proceso esté “arriba”, sino que:
- Se esté ejecutando
- Se esté ejecutando en el tiempo esperado
- No esté bloqueado o colgado
- No haya quedado detenido por un error interno
- Se haya ejecutado hasta su finalización lógica (no solo un ping inicial)
Por eso, el heartbeat monitoring es una forma de monitoreo interno y funcional, no superficial.
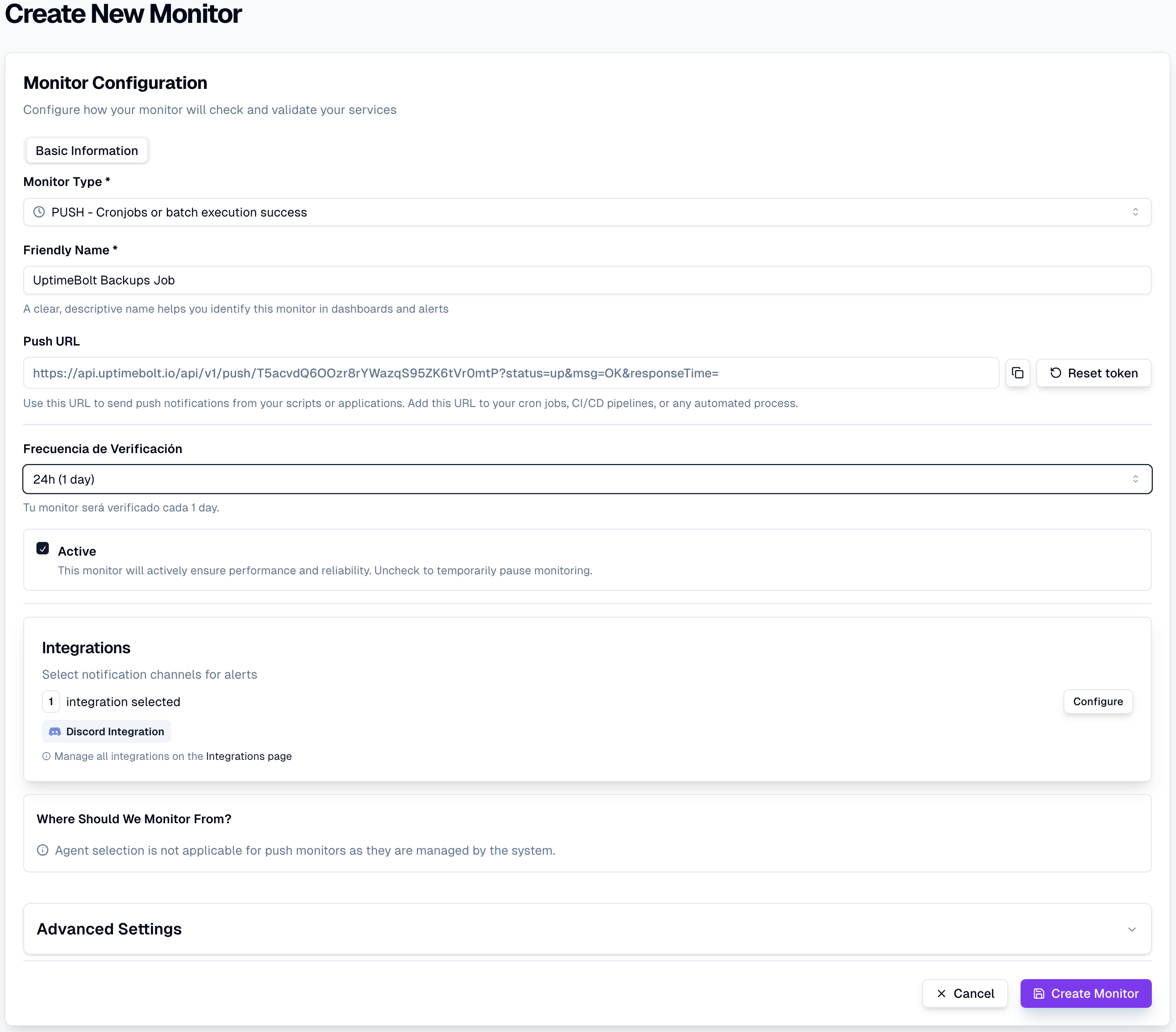
El heartbeat monitoring es especialmente útil cuando no existe un endpoint HTTP claro o cuando el fallo no se manifiesta como un error visible.
Workers que procesan tareas asincrónicas pueden detenerse sin que la aplicación principal falle.
Recomendación práctica:
Integrar el envío del latido justo después de que el worker haya procesado exitosamente el lote o la tarea.
curl -X POST [URL_Heartbeat_API]
El 80% de los fallos de rendimiento y seguridad se origina en procesos internos y en segundo plano, no en los componentes visibles para el usuario. Sin embargo, estos procesos suelen quedar fuera del radar de muchas estrategias de monitoreo modernas.
El heartbeat monitoring es una de las prácticas más subestimadas —y a la vez más críticas— dentro del monitoreo moderno. Mientras la mayoría de los equipos se enfoca en monitorear sitios web, APIs o flujos visibles para el usuario, muchos de los fallos más graves ocurren dentro del sistema, en procesos que no tienen interfaz, no responden a HTTP y no generan errores evidentes.
Workers que dejan de ejecutarse, cron jobs que fallan silenciosamente, pipelines que se quedan atascados o microservicios event-driven que dejan de procesar mensajes pueden provocar impactos operativos y de negocio enormes sin disparar ninguna alerta tradicional. Aquí es donde el heartbeat monitoring se vuelve esencial.
Esta guía explica en profundidad qué son los heartbeat monitors, cómo funcionan, cuándo utilizarlos, qué tipo de fallos detectan y cómo integrarlos correctamente en equipos de desarrollo modernos, para pasar de una observabilidad reactiva a un control real de la salud interna del sistema.
Introducción: qué es un heartbeat monitor y por qué es esencial
Un heartbeat monitor es un tipo de monitoreo activo diseñado para validar que un proceso interno sigue vivo y ejecutándose como se espera. En lugar de “preguntar” a un servicio si está disponible, el heartbeat espera recibir señales periódicas (“latidos”) desde el propio proceso monitoreado.
Si esa señal no llega dentro del intervalo esperado, el sistema asume que algo no está funcionando correctamente y genera una alerta.
El heartbeat monitoring es esencial porque cubre un tipo de riesgo que otros monitores no pueden detectar: los fallos silenciosos. Estos fallos no siempre generan errores visibles, pero pueden detener operaciones críticas durante horas sin que nadie lo note.
Cómo funcionan los heartbeats y qué validan realmente
A diferencia de un monitor web o de API, el heartbeat monitoring funciona de manera inversa. No es el sistema de monitoreo quien consulta al servicio, sino el servicio quien “avisa” periódicamente que sigue activo.
Flujo típico:
Lo que valida un heartbeat monitor no es solo que el proceso esté “arriba”, sino que:
Por eso, el heartbeat monitoring es una forma de monitoreo interno y funcional, no superficial.
Cuándo utilizar heartbeat monitoring en un equipo de desarrollo
El heartbeat monitoring es especialmente útil cuando no existe un endpoint HTTP claro o cuando el fallo no se manifiesta como un error visible.
Workers y procesos en segundo plano
Workers que procesan tareas asincrónicas pueden detenerse sin que la aplicación principal falle.
Recomendación práctica:
Integrar el envío del latido justo después de que el worker haya procesado exitosamente el lote o la tarea.