En la era de las arquitecturas serverless y microservicios, un SLA se ha convertido en una métrica de riesgo operacional más que en un simple acuerdo legal. Un SLA obsoleto impacta directamente tu error budget.
Define qué puede esperar un cliente, qué nivel de servicio está garantizado y qué ocurre cuando ese nivel no se cumple. En teoría, es una herramienta para generar confianza. En la práctica, muchas veces ocurre lo contrario.
SLAs mal diseñados generan:
- Expectativas irreales
- Incumplimientos frecuentes
- Fricción entre equipos técnicos y negocio
- Conflictos con clientes
- Pérdida de credibilidad
El problema no suele ser la intención, sino el enfoque.
En arquitecturas modernas —distribuidas, basadas en APIs, con múltiples dependencias— definir un SLA efectivo ya no es simplemente prometer “99.9% uptime”. Hoy implica entender cómo funciona realmente el sistema, qué experimenta el usuario y qué nivel de fiabilidad es sostenible en el tiempo.
Un buen SLA no es el más alto. Es el más realista, medible y alineado con el negocio.
Uno de los errores más comunes es usar estos términos como sinónimos. No lo son.
Entender su diferencia es clave para diseñar SLAs efectivos.
Es la métrica que mide el comportamiento real del sistema.
Ejemplos:
- % de requests exitosas
- Latencia de respuesta
- Tiempo de carga de una página
- Éxito de un flujo (checkout, login)
El SLI responde a:
¿Qué estamos midiendo?
Es el objetivo que defines para ese indicador.
Ejemplos:
- 99.9% de solicitudes exitosas
- Latencia < 500 ms en el 95% de los casos
- 99.5% de éxito en el flujo de pago
El SLO responde a:
¿Qué nivel consideramos aceptable?
Es el compromiso formal (contractual o interno) basado en uno o varios SLOs, que incluye consecuencias si no se cumple.
Ejemplo:
- Garantizamos 99.9% de disponibilidad mensual
- Si no se cumple, se aplican créditos al cliente
El SLA responde a:
¿Qué estamos prometiendo formalmente?
- SLI → lo que mides
- SLO → el objetivo
- SLA → el compromiso
Un SLA sin SLIs claros o SLOs bien definidos es solo un documento sin base técnica.
En un sistema de monitoreo:
- El SLI es la serie temporal de datos
- El SLO es la regla de alerta definida sobre esa serie
- El SLA es el informe mensual que usa esas reglas
Uno de los errores más críticos al crear SLAs es medir lo que es fácil, no lo que importa.
Un sistema puede estar:
- Disponible (200 OK)
- Pero lento
- O con errores funcionales
- O con flujos rotos
Desde el SLA: todo bien
Desde el usuario: todo mal
Los SLIs más valiosos están ligados a acciones reales:
- Login exitoso
- Checkout completado
- Pago procesado
- Respuesta válida de una API crítica
Ejemplo:
- ❌ SLA basado en uptime
- ✔️ SLA basado en éxito de flujo de pago
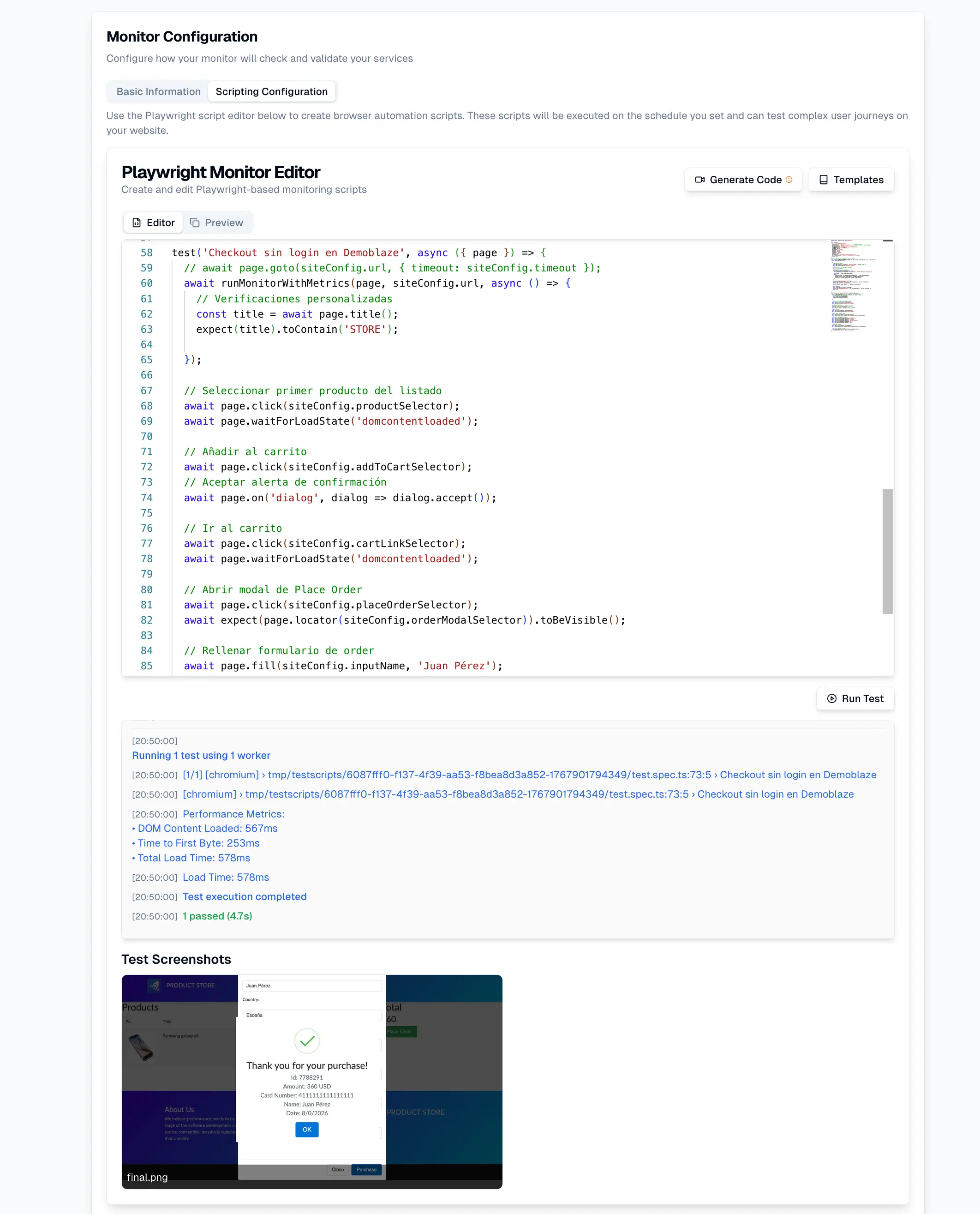
Para el flujo "Checkout completado", el SLI no es solo un 200 OK del balanceador, sino un cálculo compuesto que requiere:
- Latencia < 2s del servicio de carrito
- Éxito del 100% en la API de pagos
- Latencia < 500ms del servicio de inventario
Esto refleja el rendimiento end-to-end (E2E).
- Disponibilidad real (% éxito requests)
- Latencia (p95 / p99)
- Tasa de errores
- Éxito de flujos E2E
- Tiempo de respuesta en APIs críticas
Regla clave:
Si una métrica no refleja impacto en usuario o negocio, no debería estar en tu SLA.
Uno de los mayores errores es definir SLAs aspiracionales en lugar de realistas.
Un SLA de 99.999% (five nines):
- Permite ~5 minutos de downtime al año
- Requiere arquitectura altamente resiliente
- Requiere monitoreo avanzado
- Requiere equipos maduros
Pasar de 99.9% a 99.99% puede duplicar el costo operacional (redundancia, DR, infraestructura multisitio).
La pregunta clave:
¿Cuál es el valor de negocio de esos minutos extra de uptime?
- ¿Cuál es tu disponibilidad real actual?
- ¿Cuál es tu latencia promedio y p95?
No inventes objetivos. Mide primero.
No todos los servicios requieren el mismo nivel:
- Landing page → mayor tolerancia
- Checkout → tolerancia mínima
Ejemplo:
- SLO: 99.9%
- Error budget: 0.1%
El error budget es la moneda de cambio entre SRE y Producto.
Cuando se agota:
- Se detienen deployments
- Se prioriza estabilidad
Esto permite:
- Equilibrar innovación vs estabilidad
- Tomar decisiones informadas
Ejemplo:
- Medir infraestructura en lugar de experiencia
- Definir SLAs sin datos
- No diferenciar entre servicios
- No monitorear lo que se promete
- Ignorar degradaciones
- No alinear negocio y tecnología
Muchas fallas no son caídas totales, sino:
- Latencias altas
- Errores intermitentes
- Flujos lentos
Definir el SLA es solo el inicio. Cumplirlo es el verdadero reto.
- Automatizada
- En tiempo real
- Sin intervención manual
Permite validar:
- Flujos completos
- Experiencia real
- Impacto en usuario
Ejemplo:
- Error en API secundaria → bajo impacto
- Error en checkout → crítico
Esperar a romper el SLA es demasiado tarde.
Se debe detectar:
- Tendencias negativas
- Cambios de comportamiento
- Anomalías
Los SLAs deben ser visibles para:
- Ingeniería
- Producto
- Negocio
UptimeBolt no reemplaza la observabilidad, pero la hace accionable en el contexto de SLAs.
Permite:
- Monitorear SLIs reales (no solo uptime)
- Validar flujos E2E críticos
- Detectar anomalías antes de romper el SLA
- Predecir incidentes con anticipación
- Reducir MTTD y MTTR
- Priorizar alertas por impacto
El viernes a las 14:00, UptimeBolt detecta un aumento inusual de latencia en la API de User Microservice (patrón anómalo vs baseline histórica).
La predicción indica que el SLO de p95 se romperá en las próximas 3 horas.
Esto le da al equipo de SRE:
- 180 minutos para actuar
- Escalar infraestructura
- Revertir un deployment
Antes de afectar el SLA contractual.
Sin predicción:
- SLA se rompe
- Se genera alerta
- Reacción tardía
Con UptimeBolt:
- Detecta degradación temprana
- Alerta antes del impacto
- Permite actuar proactivamente
- Menos incumplimientos
- Menor impacto en negocio
- Mayor confianza del cliente
Un SLA no es una promesa aspiracional.
Es un compromiso operativo basado en realidad.
Un SLA efectivo:
- Está basado en métricas reales
- Refleja la experiencia del usuario
- Es medible continuamente
- Es alcanzable con la arquitectura actual
- Permite tomar decisiones
Las organizaciones más maduras no son las que prometen más, sino las que cumplen consistentemente.
El SLA se convierte en un componente clave del Reliability Lifecycle, impulsando una cultura de ingeniería basada en datos.
Accede a nuestra plataforma para alinear los SLAs de tu empresa.
¡Obtén una prueba gratuita!
En la era de las arquitecturas serverless y microservicios, un SLA se ha convertido en una métrica de riesgo operacional más que en un simple acuerdo legal. Un SLA obsoleto impacta directamente tu error budget.
Define qué puede esperar un cliente, qué nivel de servicio está garantizado y qué ocurre cuando ese nivel no se cumple. En teoría, es una herramienta para generar confianza. En la práctica, muchas veces ocurre lo contrario.
SLAs mal diseñados generan:
El problema no suele ser la intención, sino el enfoque.
En arquitecturas modernas —distribuidas, basadas en APIs, con múltiples dependencias— definir un SLA efectivo ya no es simplemente prometer “99.9% uptime”. Hoy implica entender cómo funciona realmente el sistema, qué experimenta el usuario y qué nivel de fiabilidad es sostenible en el tiempo.
Un buen SLA no es el más alto. Es el más realista, medible y alineado con el negocio.
SLA vs SLO vs SLI: diferencias claras con ejemplos prácticos
Uno de los errores más comunes es usar estos términos como sinónimos. No lo son.
Entender su diferencia es clave para diseñar SLAs efectivos.
SLI (Service Level Indicator)
Es la métrica que mide el comportamiento real del sistema.
Ejemplos:
El SLI responde a:
¿Qué estamos midiendo?
SLO (Service Level Objective)
Es el objetivo que defines para ese indicador.
Ejemplos:
El SLO responde a:
¿Qué nivel consideramos aceptable?
SLA (Service Level Agreement)
Es el compromiso formal (contractual o interno) basado en uno o varios SLOs, que incluye consecuencias si no se cumple.
Ejemplo:
El SLA responde a:
¿Qué estamos prometiendo formalmente?
Relación entre los tres
Un SLA sin SLIs claros o SLOs bien definidos es solo un documento sin base técnica.
En un sistema de monitoreo:
Cómo definir métricas que realmente reflejen la experiencia del usuario
Uno de los errores más críticos al crear SLAs es medir lo que es fácil, no lo que importa.
El problema del uptime técnico
Un sistema puede estar:
Desde el SLA: todo bien
Desde el usuario: todo mal
Métricas centradas en el usuario
Los SLIs más valiosos están ligados a acciones reales:
Ejemplo:
Para el flujo "Checkout completado", el SLI no es solo un 200 OK del balanceador, sino un cálculo compuesto que requiere:
Esto refleja el rendimiento end-to-end (E2E).
Métricas recomendadas para SLAs modernos
Regla clave:
Si una métrica no refleja impacto en usuario o negocio, no debería estar en tu SLA.
Cómo establecer objetivos realistas: ni demasiado laxos ni imposibles
Uno de los mayores errores es definir SLAs aspiracionales en lugar de realistas.
El problema de los SLAs irreales
Un SLA de 99.999% (five nines):
Pasar de 99.9% a 99.99% puede duplicar el costo operacional (redundancia, DR, infraestructura multisitio).
La pregunta clave:
¿Cuál es el valor de negocio de esos minutos extra de uptime?
Cómo definir objetivos correctamente
1. Usa datos históricos
No inventes objetivos. Mide primero.
2. Considera el impacto en negocio
No todos los servicios requieren el mismo nivel:
3. Introduce el concepto de error budget
Ejemplo:
El error budget es la moneda de cambio entre SRE y Producto.
Cuando se agota:
Esto permite:
4. Define rangos, no solo valores absolutos
Ejemplo:
Errores comunes que generan conflictos o incumplimientos
Muchas fallas no son caídas totales, sino:
Cómo monitorear continuamente el cumplimiento del SLA
Definir el SLA es solo el inicio. Cumplirlo es el verdadero reto.
1. Medición continua de SLIs
2. Monitoreo E2E
Permite validar:
3. Alertas basadas en riesgo
Ejemplo:
4. Detección temprana de degradaciones
Esperar a romper el SLA es demasiado tarde.
Se debe detectar:
5. Visibilidad compartida
Los SLAs deben ser visibles para:
Cómo UptimeBolt ayuda a alcanzar SLAs con predicción y anomalías
UptimeBolt no reemplaza la observabilidad, pero la hace accionable en el contexto de SLAs.
Permite:
Ejemplo práctico
El viernes a las 14:00, UptimeBolt detecta un aumento inusual de latencia en la API de User Microservice (patrón anómalo vs baseline histórica).
La predicción indica que el SLO de p95 se romperá en las próximas 3 horas.
Esto le da al equipo de SRE:
Antes de afectar el SLA contractual.
Comparación
Sin predicción:
Con UptimeBolt:
Resultado
Conclusión: un SLA efectivo es medible, claro y basado en datos
Un SLA no es una promesa aspiracional.
Es un compromiso operativo basado en realidad.
Un SLA efectivo:
Las organizaciones más maduras no son las que prometen más, sino las que cumplen consistentemente.
El SLA se convierte en un componente clave del Reliability Lifecycle, impulsando una cultura de ingeniería basada en datos.
Accede a nuestra plataforma para alinear los SLAs de tu empresa.
¡Obtén una prueba gratuita!