Para equipos DevOps y SRE, la simple métrica de uptime es hoy una reliquia insuficiente. En la era de los microservicios y la observabilidad, un 99.9% de disponibilidad ya no es garantía de fiabilidad.
En arquitecturas modernas —distribuidas, basadas en APIs, microservicios y múltiples dependencias— un sistema puede estar técnicamente disponible y, aun así, ofrecer una mala experiencia. Latencias altas, errores intermitentes o flujos incompletos pueden afectar directamente el negocio sin generar una caída evidente.
La fiabilidad digital ya no se mide solo con uptime, sino con la capacidad del sistema de operar correctamente bajo los principios que guían la ingeniería de confiabilidad (SRE):
- Mantener baja latencia (Latency)
- Gestionar correctamente el tráfico (Traffic)
- Minimizar y controlar errores (Errors)
- Detectar problemas a tiempo
- Recuperarse rápidamente
- Cumplir expectativas del usuario
En este artículo te presentamos las 7 métricas esenciales que realmente importan, con una estructura clara para cada una:
- Qué mide
- Cómo calcularla
- Benchmarks reales
- Cómo mejorarla
La disponibilidad real mide el porcentaje de solicitudes exitosas desde la perspectiva del usuario, no solo si el sistema responde.
Disponibilidad (%) = (Solicitudes exitosas / Solicitudes totales) × 100
- 99% → aceptable (servicios no críticos)
- 99.9% → estándar SaaS
- 99.99% → sistemas críticos (fintech, pagos)
Un sistema puede devolver 200 OK pero con datos incorrectos o incompletos.
Por ejemplo, un liveness probe en Kubernetes puede devolver 200, pero un retry loop en un servicio downstream o una conexión lenta a un datastore pueden estar causando fallos en el 1% de las transacciones sin generar una alerta crítica.
- Monitorear SLIs basados en éxito real
- Validar respuestas funcionales, no solo técnicas
- Implementar monitoreo E2E
Mide cuánto tarda el sistema en responder a una solicitud.
Latencia SLI = Percentil (pXX) del tiempo de respuesta (ej: p95 o p99 en los últimos 5 minutos).
Usar el promedio es peligroso para la fiabilidad.
- <300 ms → excelente
- 300–800 ms → aceptable
- 1 s → riesgo de abandono
En particular:
El promedio oculta problemas. Lo crítico está en los percentiles altos.
- Optimizar queries y llamadas a APIs
- Usar caché estratégicamente
- Monitorear p95 y p99, no solo promedio
Porcentaje de solicitudes que fallan.
Error rate (%) = (Errores / Total de solicitudes) × 100
- <0.1% → excelente
- 0.1% – 1% → aceptable
-
1% → crítico
No todos los errores son visibles (errores silenciosos).
Ejemplo:
- API responde 200, pero el body está vacío
- Clasificar errores técnicos vs funcionales
- Monitorear flujos completos
- Detectar anomalías tempranas
Usar modelos de Machine Learning para detectar cambios sutiles en el patrón de errores (ej: aumento del 0.05% en errores 5xx), incluso si no cruzan umbrales. Esto es monitoreo predictivo.
Tiempo promedio que tarda el sistema en recuperarse después de un incidente.
MTTR = Tiempo total de recuperación / Número de incidentes
- <30 min → excelente
- 30 min – 2 h → aceptable
-
2 h → alto impacto
El MTTR alto suele ser consecuencia de diagnóstico lento.
- Automatizar respuestas
- Tener runbooks claros
- Mejorar visibilidad y correlación de eventos
Implementar AIOps para agrupar alertas y reducir el Time To Triage, impactando directamente el MTTR.
Tiempo promedio que tarda el equipo en detectar un problema.
MTTD = Tiempo total hasta detección / Número de incidentes
- <5 min → excelente
- 5–15 min → aceptable
-
15 min → riesgo operativo
Muchas fallas se detectan por usuarios, no por monitoreo.
- Implementar monitoreo E2E
- Usar detección de anomalías
- Reducir dependencia de umbrales
La detección con IA es clave para bajar el MTTD por debajo de 5 minutos.
Mide el porcentaje de veces que un flujo completo se ejecuta correctamente.
Flow success rate (%) = (Flujos exitosos / Flujos totales) × 100
- 99.5% → excelente
- 98–99.5% → riesgo moderado
- <98% → impacto directo en negocio
Es la métrica más cercana a la experiencia real.
Ejemplo:
- API OK
- Base de datos OK
- Pero el checkout falla
Solo el monitoreo E2E lo detecta.
- Monitoreo end-to-end continuo
- Validar pasos intermedios
- Detectar degradaciones parciales
Cantidad de fallos permitidos según el SLO.
Error budget = 100% - SLO
- SLO: 99.9%
- Error budget: 0.1%
- Usarlo para decisiones de despliegue
- Balancear estabilidad vs velocidad
- Integrarlo en planificación
Precisión de las predicciones de incidentes con IA.
Prediction accuracy (%) = (Predicciones correctas / Total de predicciones) × 100
- 85% → alto nivel
- 70–85% → útil
- <70% → ruido
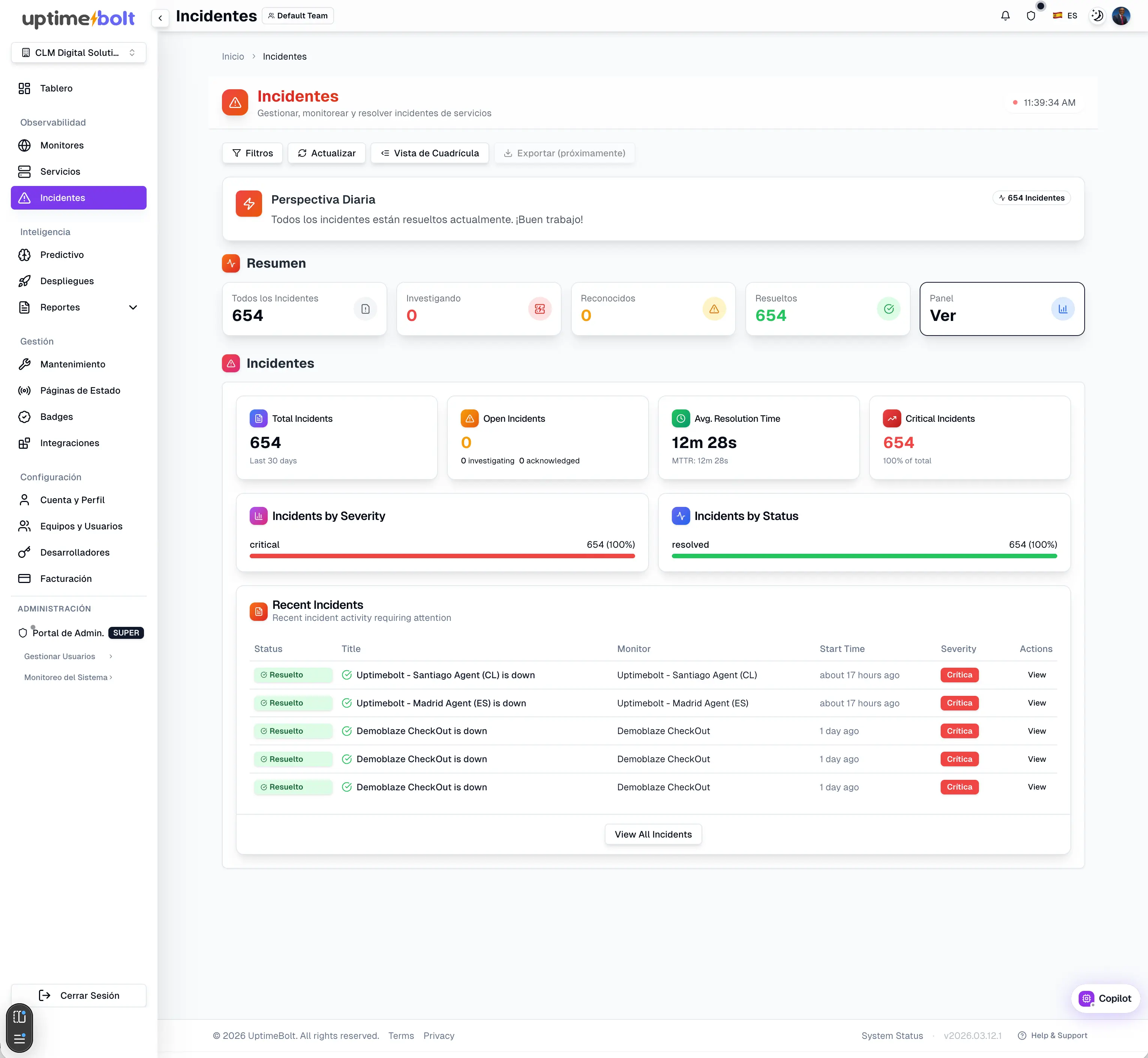
La fiabilidad digital no es un estado, es un proceso continuo.
No se logra con más dashboards, sino con:
- Las métricas correctas
- Interpretación adecuada
- Acción constante
Las organizaciones más maduras no monitorean más—entienden mejor.
Si quieres mejorar tu fiabilidad con monitoreo predictivo, prueba UptimeBolt gratis.
Para equipos DevOps y SRE, la simple métrica de uptime es hoy una reliquia insuficiente. En la era de los microservicios y la observabilidad, un 99.9% de disponibilidad ya no es garantía de fiabilidad.
En arquitecturas modernas —distribuidas, basadas en APIs, microservicios y múltiples dependencias— un sistema puede estar técnicamente disponible y, aun así, ofrecer una mala experiencia. Latencias altas, errores intermitentes o flujos incompletos pueden afectar directamente el negocio sin generar una caída evidente.
La fiabilidad digital ya no se mide solo con uptime, sino con la capacidad del sistema de operar correctamente bajo los principios que guían la ingeniería de confiabilidad (SRE):
En este artículo te presentamos las 7 métricas esenciales que realmente importan, con una estructura clara para cada una:
Métrica 1: Disponibilidad real (SLI)
Definición
La disponibilidad real mide el porcentaje de solicitudes exitosas desde la perspectiva del usuario, no solo si el sistema responde.
Fórmula
Disponibilidad (%) = (Solicitudes exitosas / Solicitudes totales) × 100
Benchmark de la industria
Problema común
Un sistema puede devolver 200 OK pero con datos incorrectos o incompletos.
Por ejemplo, un liveness probe en Kubernetes puede devolver 200, pero un retry loop en un servicio downstream o una conexión lenta a un datastore pueden estar causando fallos en el 1% de las transacciones sin generar una alerta crítica.
Cómo mejorarla
Métrica 2: Latencia y tiempos de respuesta
Definición
Mide cuánto tarda el sistema en responder a una solicitud.
Fórmula
Latencia SLI = Percentil (pXX) del tiempo de respuesta (ej: p95 o p99 en los últimos 5 minutos).
Usar el promedio es peligroso para la fiabilidad.
Benchmark de la industria
En particular:
Problema común
El promedio oculta problemas. Lo crítico está en los percentiles altos.
Cómo mejorarla
Métrica 3: Tasa de errores
Definición
Porcentaje de solicitudes que fallan.
Fórmula
Error rate (%) = (Errores / Total de solicitudes) × 100
Benchmark de la industria
Problema común
No todos los errores son visibles (errores silenciosos).
Ejemplo:
Cómo mejorarla
Usar modelos de Machine Learning para detectar cambios sutiles en el patrón de errores (ej: aumento del 0.05% en errores 5xx), incluso si no cruzan umbrales. Esto es monitoreo predictivo.
Métrica 4: MTTR (Mean Time To Recovery)
Definición
Tiempo promedio que tarda el sistema en recuperarse después de un incidente.
Fórmula
MTTR = Tiempo total de recuperación / Número de incidentes
Benchmark de la industria
Problema común
El MTTR alto suele ser consecuencia de diagnóstico lento.
Cómo mejorarla
Implementar AIOps para agrupar alertas y reducir el Time To Triage, impactando directamente el MTTR.
Métrica 5: MTTD (Mean Time To Detect)
Definición
Tiempo promedio que tarda el equipo en detectar un problema.
Fórmula
MTTD = Tiempo total hasta detección / Número de incidentes
Benchmark de la industria
Problema común
Muchas fallas se detectan por usuarios, no por monitoreo.
Cómo mejorarla
La detección con IA es clave para bajar el MTTD por debajo de 5 minutos.
Métrica 6: Éxito de flujos críticos (E2E)
Definición
Mide el porcentaje de veces que un flujo completo se ejecuta correctamente.
Fórmula
Flow success rate (%) = (Flujos exitosos / Flujos totales) × 100
Benchmark de la industria
Problema clave
Es la métrica más cercana a la experiencia real.
Ejemplo:
Solo el monitoreo E2E lo detecta.
Cómo mejorarla
Métrica 7: Error Budget
Definición
Cantidad de fallos permitidos según el SLO.
Fórmula
Error budget = 100% - SLO
Ejemplo
Cómo mejorarla
Métrica bonus: Tasa de predicciones correctas
Definición
Precisión de las predicciones de incidentes con IA.
Fórmula
Prediction accuracy (%) = (Predicciones correctas / Total de predicciones) × 100
Benchmark
Conclusión
La fiabilidad digital no es un estado, es un proceso continuo.
No se logra con más dashboards, sino con:
Las organizaciones más maduras no monitorean más—entienden mejor.
Si quieres mejorar tu fiabilidad con monitoreo predictivo, prueba UptimeBolt gratis.