Durante mucho tiempo, los incidentes de TI se trataron como eventos impredecibles: “cosas que pasan”, “fallas inevitables” o simples consecuencias de la complejidad. Sin embargo, la experiencia acumulada en miles de incidentes reales demuestra lo contrario: la mayoría de los incidentes no son aleatorios. De hecho, casi siempre existen señales previas que, si se detectan a tiempo, permiten actuar antes de que el impacto llegue al usuario.
Estudios del Ponemon Institute estiman que el costo promedio de una interrupción crítica de TI supera los USD 9.000 por minuto en industrias como e-commerce y fintech, mientras que Gartner ha señalado que más del 70% de los incidentes graves presentan síntomas detectables antes de la caída total del servicio. El problema no es la falta de datos, sino la incapacidad humana para detectar patrones sutiles a tiempo.
Aquí es donde la inteligencia artificial cambia el juego. No reemplaza a los equipos, pero sí permite identificar degradaciones, anomalías y comportamientos atípicos cuando aún hay margen de acción.
En este artículo analizamos las 7 causas más comunes de incidentes de TI que la IA puede anticipar, con ejemplos reales, señales concretas y cómo prevenirlos antes de que se conviertan en caídas visibles. El enfoque está en sistemas modernos de e-commerce, SaaS y fintech, donde el downtime no solo es técnico, sino un problema directo de negocio.
Cuando ocurre un incidente grave, el análisis postmortem suele revelar una historia conocida: pequeñas degradaciones ignoradas, alertas que no parecían críticas, métricas “dentro de lo normal” que en realidad ya mostraban un patrón preocupante.
Los incidentes suelen ser el resultado de:
- Acumulación de pequeños cambios
- Dependencias que se degradan lentamente
- Crecimiento de tráfico no anticipado
- Saturación progresiva de recursos
- Errores silenciosos que pasan desapercibidos
La diferencia entre un incidente crítico y una simple degradación controlada suele ser el momento de detección. La IA no evita que los sistemas fallen, pero permite ver lo que el monitoreo tradicional no detecta a tiempo.
Una reducción continua e incremental de un Service Level Indicator (SLI), donde el valor se mantiene dentro de los límites de alerta tradicionales, pero el rate of change indica una falla inminente.
Una API de pagos comenzó a mostrar un aumento gradual en su latencia promedio:
- Día 1: 420 ms
- Día 2: 680 ms
- Día 3: 1.1 s
- Día 4: 2.3 s
No hubo errores ni caídas, pero la conversión cayó un 11%. Cuatro horas después, el servicio colapsó por timeouts en cascada.
Un modelo de detección de anomalías identificó la desviación del patrón histórico 4 horas antes del fallo total, cuando la latencia aún estaba “dentro de parámetros aceptables”.
- Análisis de tendencias, no solo valores absolutos
- Comparación contra comportamiento histórico
- Detección de cambios de pendiente (rate of change)
- Monitorear percentiles (p95, p99), no solo promedios
- Detectar degradaciones lentas
- Actuar antes de que el usuario perciba el impacto
La saturación de recursos sigue siendo una causa central de incidentes, pero rara vez ocurre de forma instantánea. Normalmente hay señales previas: aumento de latencia, colas más largas, tiempos de lock crecientes.
Una base de datos relacional comenzó a mostrar:
- Uso de CPU estable (65–70%)
- Aumento progresivo en tiempo de queries
- Crecimiento del pool de conexiones activas
El sistema funcionó “normalmente” durante horas hasta que alcanzó el límite de conexiones y comenzó a rechazar requests. El impacto fue total.
La IA detectó el patrón de saturación 90 minutos antes, al identificar que la variabilidad de los tiempos de respuesta estaba creciendo de forma anómala.
- Variabilidad en tiempos de query
- Correlación entre carga y latencia
- Patrones repetitivos de contención
- Alertar por tendencia, no solo por umbral
- Escalar antes del colapso
- Priorizar queries críticos
Los errores intermitentes son especialmente peligrosos porque no siempre generan alertas claras. Un pequeño porcentaje de timeouts puede no parecer crítico, pero basta para romper flujos completos.
Una API externa comenzó a mostrar:
- 1.2% de timeouts
- Latencia errática entre 300 ms y 4 s
El error rate no superaba los umbrales configurados. Sin embargo, el checkout fallaba de forma aleatoria.
La IA detectó un patrón de intermitencia anómala 2 horas antes, permitiendo redirigir tráfico y evitar la caída.
- Utiliza modelos de clustering para identificar patrones de fallos no determinísticos (o “anomalías de baja tasa”) que un monitor de umbral ignora
- Analiza correlación entre errores y contexto
- Detecta comportamientos “raros” aunque el volumen sea bajo
Los picos de tráfico no siempre son DDoS. Muchas veces son campañas exitosas, eventos de marketing o integraciones mal controladas.
Una plataforma SaaS recibió un aumento de tráfico del 180% en 20 minutos tras una integración externa. No hubo errores inmediatos, pero la latencia se duplicó.
La IA detectó el patrón como tráfico anómalo 35 minutos antes de que se saturaran los servicios internos.
- Cambios bruscos en patrones de acceso
- Distribución inusual por región o endpoint
- Incremento de concurrencia no esperado
- Implementar rate limiting adaptativo
- Desacoplar flujos críticos (por ejemplo, autenticación vs. logs)
- Proteger flujos esenciales
- Priorizar tráfico legítimo
En arquitecturas distribuidas, un microservicio puede seguir activo pero dejar de cumplir su función: colas que no se procesan, workers bloqueados, eventos no consumidos.
Un consumer de mensajes quedó activo pero dejó de procesar eventos tras un deploy. No hubo errores ni alertas.
La IA detectó la ausencia de comportamiento esperado (heartbeats funcionales) y alertó 3 horas antes de que el impacto fuera visible en usuarios finales.
- Comparación contra comportamiento esperado
- Identificación de “silencio anómalo”
- Análisis de flujos end-to-end (E2E)
La expiración de certificados sigue causando incidentes graves, a pesar de ser totalmente predecible.
Un certificado TLS estaba a 5 días de expirar. Nadie lo notó. Al expirar, el 100% del tráfico HTTPS falló.
La IA detectó el riesgo 72 horas antes, correlacionando fecha de expiración con dependencia crítica del servicio.
- Monitorear expiraciones con contexto
- Alertar según impacto real
- Automatizar renovaciones
Cambios DNS mal coordinados pueden generar latencia, errores regionales o caídas parciales difíciles de diagnosticar.
Un cambio DNS redujo el TTL y redirigió tráfico a una región no preparada. El impacto fue progresivo.
La IA detectó anomalías regionales y aumento de latencia 1 hora antes del colapso total.
- Cambios en patrones geográficos
- Latencia desigual entre regiones
- Errores correlacionados con resolución DNS
La IA no “adivina”. Observa, compara y aprende.
Los modelos se basan en:
- Series de tiempo
- Comportamiento histórico
- Correlación entre señales
- Contexto operacional
Esto permite pasar de alertas reactivas a detección anticipada, reduciendo MTTD, MTTR y consumo de error budgets.
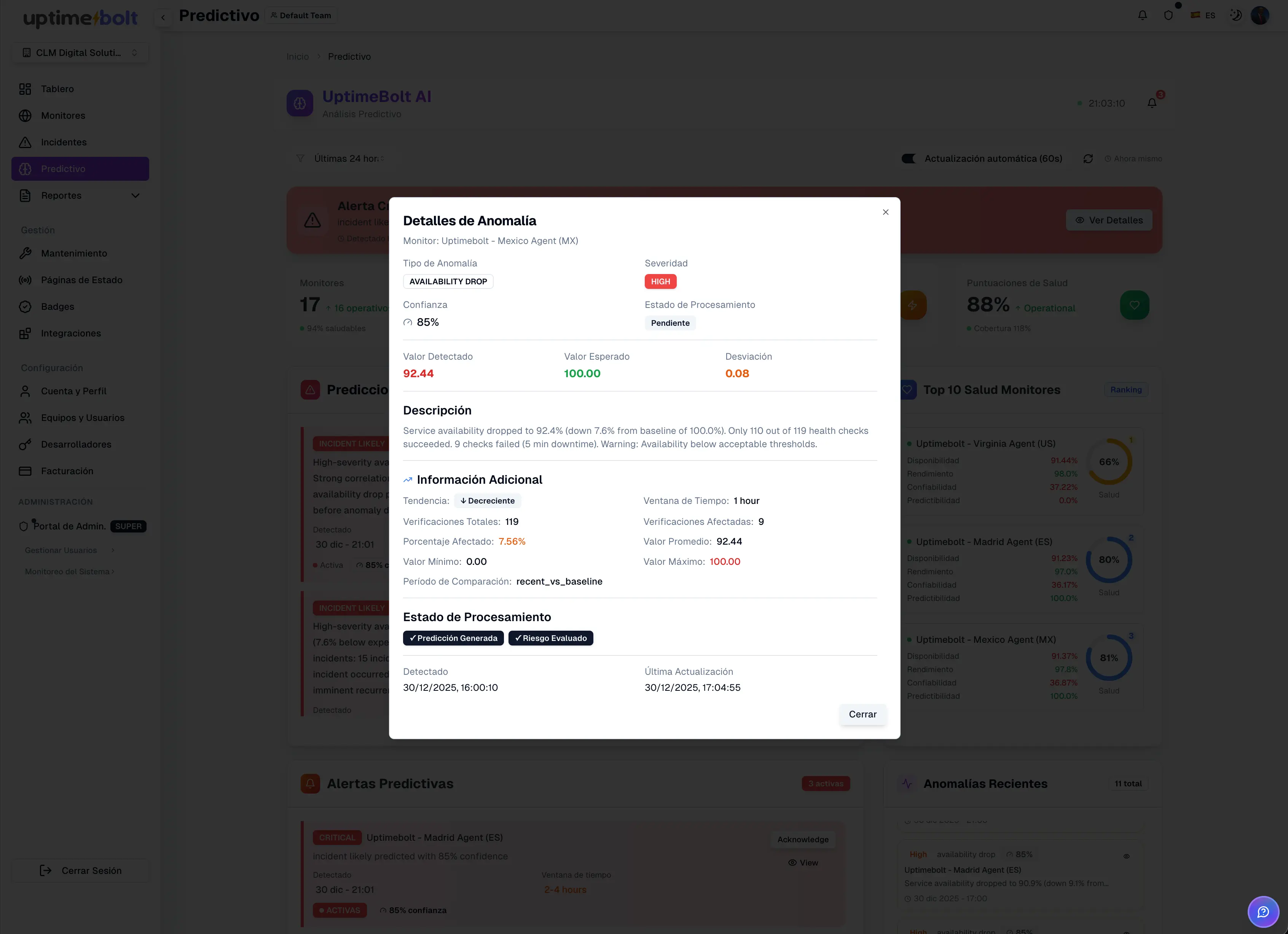
Los incidentes de TI no suelen aparecer de la nada. En la mayoría de los casos, el sistema avisa antes de fallar. El problema es que esas señales suelen ser invisibles para el monitoreo tradicional.
La inteligencia artificial permite identificar degradaciones, anomalías y riesgos cuando todavía es posible actuar. No elimina los fallos, pero reduce drásticamente su impacto.
Adoptar una estrategia predictiva es el nuevo estándar operacional para alcanzar una verdadera resiliencia. La IA es la única forma de escalar la visibilidad al ritmo de la complejidad de la infraestructura moderna.
Si quieres empezar a anticipar incidentes comunes —como degradaciones, saturaciones, timeouts, tráfico anómalo o fallos silenciosos— y reducir el costo operativo del downtime, te invitamos a comenzar con UptimeBolt a través de una prueba gratuita y dar el primer paso hacia una operación más preventiva, estable y resiliente.
Durante mucho tiempo, los incidentes de TI se trataron como eventos impredecibles: “cosas que pasan”, “fallas inevitables” o simples consecuencias de la complejidad. Sin embargo, la experiencia acumulada en miles de incidentes reales demuestra lo contrario: la mayoría de los incidentes no son aleatorios. De hecho, casi siempre existen señales previas que, si se detectan a tiempo, permiten actuar antes de que el impacto llegue al usuario.
Estudios del Ponemon Institute estiman que el costo promedio de una interrupción crítica de TI supera los USD 9.000 por minuto en industrias como e-commerce y fintech, mientras que Gartner ha señalado que más del 70% de los incidentes graves presentan síntomas detectables antes de la caída total del servicio. El problema no es la falta de datos, sino la incapacidad humana para detectar patrones sutiles a tiempo.
Aquí es donde la inteligencia artificial cambia el juego. No reemplaza a los equipos, pero sí permite identificar degradaciones, anomalías y comportamientos atípicos cuando aún hay margen de acción.
En este artículo analizamos las 7 causas más comunes de incidentes de TI que la IA puede anticipar, con ejemplos reales, señales concretas y cómo prevenirlos antes de que se conviertan en caídas visibles. El enfoque está en sistemas modernos de e-commerce, SaaS y fintech, donde el downtime no solo es técnico, sino un problema directo de negocio.
La mayoría de los incidentes NO son aleatorios
Cuando ocurre un incidente grave, el análisis postmortem suele revelar una historia conocida: pequeñas degradaciones ignoradas, alertas que no parecían críticas, métricas “dentro de lo normal” que en realidad ya mostraban un patrón preocupante.
Los incidentes suelen ser el resultado de:
La diferencia entre un incidente crítico y una simple degradación controlada suele ser el momento de detección. La IA no evita que los sistemas fallen, pero permite ver lo que el monitoreo tradicional no detecta a tiempo.
Causa 1: Degradación progresiva del rendimiento
Una reducción continua e incremental de un Service Level Indicator (SLI), donde el valor se mantiene dentro de los límites de alerta tradicionales, pero el rate of change indica una falla inminente.
Mini caso real
Una API de pagos comenzó a mostrar un aumento gradual en su latencia promedio:
No hubo errores ni caídas, pero la conversión cayó un 11%. Cuatro horas después, el servicio colapsó por timeouts en cascada.
Un modelo de detección de anomalías identificó la desviación del patrón histórico 4 horas antes del fallo total, cuando la latencia aún estaba “dentro de parámetros aceptables”.
Cómo la IA detecta esta causa
Cómo prevenirla
Causa 2: Saturación en bases de datos o servidores
Contención de Recursos Críticos y sus Señales Precursoras
La saturación de recursos sigue siendo una causa central de incidentes, pero rara vez ocurre de forma instantánea. Normalmente hay señales previas: aumento de latencia, colas más largas, tiempos de lock crecientes.
Mini caso real
Una base de datos relacional comenzó a mostrar:
El sistema funcionó “normalmente” durante horas hasta que alcanzó el límite de conexiones y comenzó a rechazar requests. El impacto fue total.
La IA detectó el patrón de saturación 90 minutos antes, al identificar que la variabilidad de los tiempos de respuesta estaba creciendo de forma anómala.
Señales que la IA utiliza
Prevención
Causa 3: Timeouts y errores intermitentes en APIs
El enemigo invisible
Los errores intermitentes son especialmente peligrosos porque no siempre generan alertas claras. Un pequeño porcentaje de timeouts puede no parecer crítico, pero basta para romper flujos completos.
Mini caso real
Una API externa comenzó a mostrar:
El error rate no superaba los umbrales configurados. Sin embargo, el checkout fallaba de forma aleatoria.
La IA detectó un patrón de intermitencia anómala 2 horas antes, permitiendo redirigir tráfico y evitar la caída.
Cómo la IA ayuda
Causa 4: Tráfico anómalo o picos inesperados
No todo pico es un ataque
Los picos de tráfico no siempre son DDoS. Muchas veces son campañas exitosas, eventos de marketing o integraciones mal controladas.
Mini caso real
Una plataforma SaaS recibió un aumento de tráfico del 180% en 20 minutos tras una integración externa. No hubo errores inmediatos, pero la latencia se duplicó.
La IA detectó el patrón como tráfico anómalo 35 minutos antes de que se saturaran los servicios internos.
Señales clave
Prevención
Causa 5: Fallos silenciosos en microservicios
Cuando “todo está arriba” pero nada funciona bien
En arquitecturas distribuidas, un microservicio puede seguir activo pero dejar de cumplir su función: colas que no se procesan, workers bloqueados, eventos no consumidos.
Mini caso real
Un consumer de mensajes quedó activo pero dejó de procesar eventos tras un deploy. No hubo errores ni alertas.
La IA detectó la ausencia de comportamiento esperado (heartbeats funcionales) y alertó 3 horas antes de que el impacto fuera visible en usuarios finales.
Detección
Causa 6: Certificados SSL/TLS expirados
El incidente más evitable (y más común)
La expiración de certificados sigue causando incidentes graves, a pesar de ser totalmente predecible.
Mini caso real
Un certificado TLS estaba a 5 días de expirar. Nadie lo notó. Al expirar, el 100% del tráfico HTTPS falló.
La IA detectó el riesgo 72 horas antes, correlacionando fecha de expiración con dependencia crítica del servicio.
Prevención
Causa 7: Cambios DNS no planificados
El efecto dominó del DNS
Cambios DNS mal coordinados pueden generar latencia, errores regionales o caídas parciales difíciles de diagnosticar.
Mini caso real
Un cambio DNS redujo el TTL y redirigió tráfico a una región no preparada. El impacto fue progresivo.
La IA detectó anomalías regionales y aumento de latencia 1 hora antes del colapso total.
Señales utilizadas
Cómo la IA detecta estas señales antes de que escalen
La IA no “adivina”. Observa, compara y aprende.
Los modelos se basan en:
Esto permite pasar de alertas reactivas a detección anticipada, reduciendo MTTD, MTTR y consumo de error budgets.
Conclusión: reducir incidentes comienza con anticiparlos
Los incidentes de TI no suelen aparecer de la nada. En la mayoría de los casos, el sistema avisa antes de fallar. El problema es que esas señales suelen ser invisibles para el monitoreo tradicional.
La inteligencia artificial permite identificar degradaciones, anomalías y riesgos cuando todavía es posible actuar. No elimina los fallos, pero reduce drásticamente su impacto.
Adoptar una estrategia predictiva es el nuevo estándar operacional para alcanzar una verdadera resiliencia. La IA es la única forma de escalar la visibilidad al ritmo de la complejidad de la infraestructura moderna.
Si quieres empezar a anticipar incidentes comunes —como degradaciones, saturaciones, timeouts, tráfico anómalo o fallos silenciosos— y reducir el costo operativo del downtime, te invitamos a comenzar con UptimeBolt a través de una prueba gratuita y dar el primer paso hacia una operación más preventiva, estable y resiliente.