Durante años, la mayoría de los equipos técnicos ha operado bajo una premisa implícita: los incidentes son inevitables, lo importante es reaccionar rápido. Esta mentalidad dio forma a herramientas, procesos y culturas enteras basadas en alertas, on-calls y war rooms que se activan cuando algo ya se rompió.
El problema es que, en plataformas digitales modernas, reaccionar ya no es suficiente. Cuando un usuario percibe lentitud, errores o caídas, el daño ya ocurrió: se perdió una venta, una transacción, confianza o reputación. El monitoreo reactivo detecta el fallo; el monitoreo proactivo busca evitar que ese fallo llegue a manifestarse.
Este artículo explora en profundidad la diferencia entre monitoreo reactivo y monitoreo proactivo, no desde una perspectiva de herramientas avanzadas o modelos predictivos complejos, sino desde el cambio cultural y operativo que implica pasar de apagar incendios a prevenirlos. También analizaremos costos reales del downtime, escenarios concretos, métricas involucradas y cómo migrar progresivamente hacia un modelo proactivo sin romper la operación existente.
La mayoría de los equipos cree que monitorea bien porque recibe alertas. Sin embargo, muchas de esas alertas llegan cuando el usuario ya está experimentando el problema o incluso cuando el impacto ya es significativo.
Algunos síntomas clásicos de este enfoque son:
- Alertas que se disparan después de picos de errores visibles
- Incidentes detectados por clientes antes que por el equipo
- Dashboards que “se ponen rojos” cuando el daño ya está hecho
- On-calls reactivos, estresantes y frecuentes
- Postmortems que siempre concluyen “deberíamos haberlo visto antes”
Este modelo no falla por falta de esfuerzo, sino por diseño. El monitoreo reactivo está construido para confirmar que algo se rompió, no para anticipar que algo se está degradando.
El monitoreo reactivo se basa en reglas y umbrales definidos previamente. El sistema observa métricas conocidas y genera alertas cuando estas cruzan un límite considerado “inaceptable”.
Ejemplos típicos incluyen:
- CPU > 85% durante 5 minutos
- Error rate HTTP 5xx > 2%
- Servicio no responde
- Job no se ejecuta en el intervalo esperado
Este enfoque responde a la pregunta:
¿Algo ya se rompió o está claramente fuera de lo normal?
Sería un error decir que el monitoreo reactivo no sirve. De hecho, sigue siendo indispensable para:
- Confirmar disponibilidad
- Cumplir SLAs básicos
- Detectar fallos binarios (up/down)
- Automatizar respuestas simples
- Tener visibilidad mínima operativa
El problema no es su existencia, sino depender exclusivamente de él.
El monitoreo reactivo tiene límites claros:
- No detecta degradaciones progresivas
- No entiende contexto
- Genera mucho ruido en sistemas complejos
- Reacciona cuando el impacto ya es visible
- Obliga a definir de antemano todos los escenarios
En arquitecturas modernas, donde el comportamiento normal cambia constantemente, estos límites se vuelven críticos.
El monitoreo proactivo no espera a que una métrica cruce un umbral fijo. Busca identificar señales tempranas de que algo se está desviando de su comportamiento normal, incluso si todavía no hay errores visibles.
La pregunta cambia de:
“¿Está roto?”
a
“¿Este comportamiento es normal para este sistema en este momento?”
Ser proactivo no significa predecir el futuro con exactitud matemática. Significa detectar degradaciones antes de que se conviertan en incidentes.
Un modelo de monitoreo proactivo presta atención a:
- Tendencias, no solo valores absolutos
- Cambios sutiles en latencia o rendimiento
- Variabilidad anómala (jitter)
- Patrones históricos y estacionales
- Comportamientos atípicos en flujos críticos
Muchas veces, antes de una caída, el sistema “avisa” con pequeñas señales que el monitoreo reactivo ignora.
Para una audiencia técnica, “proactivo” y “predictivo” pueden sonar similares, pero no son lo mismo.
- Proactivo: detectar y actuar antes de que el usuario sienta el impacto.
- Predictivo: estimar con modelos que un incidente ocurrirá en el futuro.
El monitoreo proactivo puede apoyarse en técnicas predictivas, pero no depende exclusivamente de ellas. De hecho, la predicción avanzada merece un tratamiento propio.
Este artículo establece el monitoreo proactivo como la base sobre la cual luego se puede evolucionar hacia modelos predictivos más sofisticados.
En organizaciones con monitoreo reactivo:
- MTTD típico: 15–45 minutos
- El usuario suele notar el problema antes
En organizaciones con monitoreo proactivo:
- MTTD: 3–10 minutos
- En muchos casos, detección antes del impacto visible
La diferencia no es técnica, es operacional.
Aquí es donde el debate deja de ser filosófico.
Algunos datos ampliamente citados:
- Gartner estima que el costo promedio del downtime de TI ronda los USD 5.600 por minuto, dependiendo de la industria.
- El Ponemon Institute reporta que en e-commerce y fintech el costo puede superar los USD 9.000 por minuto durante eventos críticos.
- Amazon estimó históricamente pérdidas de más de USD 100.000 por minuto en caídas de alto tráfico.
Si un monitoreo reactivo detecta un incidente 30 minutos tarde, el impacto económico puede ser enorme, incluso si la recuperación es rápida.
El monitoreo proactivo no elimina todos los incidentes, pero reduce drásticamente el tiempo de exposición, que es lo que realmente cuesta dinero.
El monitoreo reactivo suele generar:
- Demasiadas alertas
- Alert fatigue
- On-calls constantes
- Burnout en equipos SRE y DevOps
El enfoque proactivo reduce ruido porque prioriza señales relevantes, no cada fluctuación irrelevante.
Un e-commerce experimenta un aumento gradual en la latencia del checkout durante varias horas. No se superan umbrales fijos, por lo que no hay alertas. La conversión cae un 8%.
Un enfoque proactivo habría detectado el patrón anómalo de latencia antes de que el impacto fuera significativo.
Un servicio comienza a mostrar mayor variabilidad en tiempos de respuesta debido a saturación de conexiones. El servicio nunca cae, pero se vuelve inestable.
El monitoreo reactivo no alerta. El proactivo detecta el jitter creciente y permite actuar antes del colapso.
Una API externa responde más lento de lo normal, sin errores. El impacto se propaga a flujos internos.
El monitoreo reactivo ve “todo arriba”. El proactivo detecta la desviación de comportamiento.
Migrar no significa tirar lo que ya existe. El cambio debe ser incremental.
El primer cambio es conceptual. La disponibilidad binaria no refleja la experiencia real del usuario.
No todo debe monitorearse igual. Identifica:
- Login
- Checkout
- Pagos
- APIs core
Estos flujos deben ser el foco del monitoreo proactivo.
Empieza a observar:
- Tendencias
- Variabilidad
- Degradaciones lentas
No solo valores absolutos.
Menos alertas, mejor contexto.
Playbooks, mitigaciones y automatización.
La inteligencia artificial no reemplaza al monitoreo proactivo, lo potencia.
La IA permite:
- Detectar anomalías que no cruzan umbrales
- Identificar patrones invisibles
- Priorizar riesgos reales
- Reducir falsos positivos
- Acelerar la toma de decisiones
Aquí es donde el monitoreo proactivo se convierte en una ventaja competitiva real y sostenida.
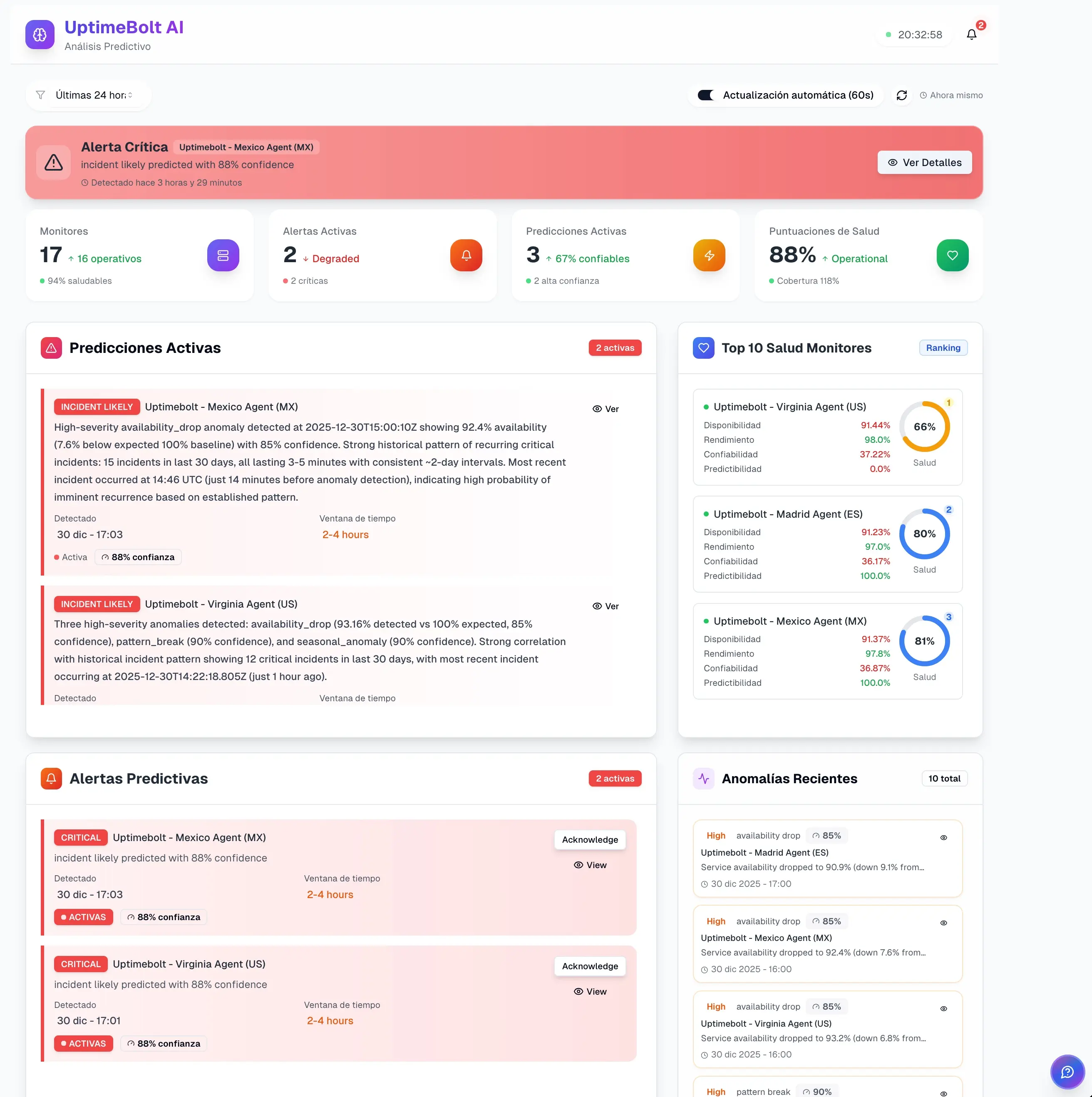
El monitoreo reactivo seguirá existiendo, pero ya no puede ser el centro de la operación. En plataformas modernas, reaccionar rápido no es suficiente cuando el daño ocurre en segundos.
El monitoreo proactivo representa un cambio cultural: pasar de confirmar fallos a prevenir impactos, de apagar incendios a reducir su probabilidad.
Las organizaciones que adoptan este enfoque no solo reducen downtime, sino que mejoran la experiencia del usuario, reducen costos operativos y protegen a sus equipos.
Si quieres empezar a evolucionar desde un monitoreo reactivo hacia un modelo más proactivo y preventivo, te invitamos a comenzar con UptimeBolt a través de una prueba gratuita y dar el primer paso hacia una operación más estable, predecible y resiliente.
Durante años, la mayoría de los equipos técnicos ha operado bajo una premisa implícita: los incidentes son inevitables, lo importante es reaccionar rápido. Esta mentalidad dio forma a herramientas, procesos y culturas enteras basadas en alertas, on-calls y war rooms que se activan cuando algo ya se rompió.
El problema es que, en plataformas digitales modernas, reaccionar ya no es suficiente. Cuando un usuario percibe lentitud, errores o caídas, el daño ya ocurrió: se perdió una venta, una transacción, confianza o reputación. El monitoreo reactivo detecta el fallo; el monitoreo proactivo busca evitar que ese fallo llegue a manifestarse.
Este artículo explora en profundidad la diferencia entre monitoreo reactivo y monitoreo proactivo, no desde una perspectiva de herramientas avanzadas o modelos predictivos complejos, sino desde el cambio cultural y operativo que implica pasar de apagar incendios a prevenirlos. También analizaremos costos reales del downtime, escenarios concretos, métricas involucradas y cómo migrar progresivamente hacia un modelo proactivo sin romper la operación existente.
El problema de depender de alertas cuando ya es tarde
La mayoría de los equipos cree que monitorea bien porque recibe alertas. Sin embargo, muchas de esas alertas llegan cuando el usuario ya está experimentando el problema o incluso cuando el impacto ya es significativo.
Algunos síntomas clásicos de este enfoque son:
Este modelo no falla por falta de esfuerzo, sino por diseño. El monitoreo reactivo está construido para confirmar que algo se rompió, no para anticipar que algo se está degradando.
Monitoreo reactivo: cómo funciona y por qué limita la fiabilidad
Qué es el monitoreo reactivo
El monitoreo reactivo se basa en reglas y umbrales definidos previamente. El sistema observa métricas conocidas y genera alertas cuando estas cruzan un límite considerado “inaceptable”.
Ejemplos típicos incluyen:
Este enfoque responde a la pregunta:
Ventajas del monitoreo reactivo
Sería un error decir que el monitoreo reactivo no sirve. De hecho, sigue siendo indispensable para:
El problema no es su existencia, sino depender exclusivamente de él.
Limitaciones estructurales
El monitoreo reactivo tiene límites claros:
En arquitecturas modernas, donde el comportamiento normal cambia constantemente, estos límites se vuelven críticos.
Monitoreo proactivo: anticipación, patrones y prevención
Qué significa realmente ser proactivo
El monitoreo proactivo no espera a que una métrica cruce un umbral fijo. Busca identificar señales tempranas de que algo se está desviando de su comportamiento normal, incluso si todavía no hay errores visibles.
La pregunta cambia de:
a
Ser proactivo no significa predecir el futuro con exactitud matemática. Significa detectar degradaciones antes de que se conviertan en incidentes.
Qué observa un enfoque proactivo
Un modelo de monitoreo proactivo presta atención a:
Muchas veces, antes de una caída, el sistema “avisa” con pequeñas señales que el monitoreo reactivo ignora.
Proactivo vs. predictivo (aclaración clave)
Para una audiencia técnica, “proactivo” y “predictivo” pueden sonar similares, pero no son lo mismo.
El monitoreo proactivo puede apoyarse en técnicas predictivas, pero no depende exclusivamente de ellas. De hecho, la predicción avanzada merece un tratamiento propio.
Este artículo establece el monitoreo proactivo como la base sobre la cual luego se puede evolucionar hacia modelos predictivos más sofisticados.
Comparativa directa: tiempo, costos, impacto y ruido
Tiempo de detección y reacción
En organizaciones con monitoreo reactivo:
En organizaciones con monitoreo proactivo:
La diferencia no es técnica, es operacional.
Costos reales del downtime: datos duros
Aquí es donde el debate deja de ser filosófico.
Algunos datos ampliamente citados:
Si un monitoreo reactivo detecta un incidente 30 minutos tarde, el impacto económico puede ser enorme, incluso si la recuperación es rápida.
El monitoreo proactivo no elimina todos los incidentes, pero reduce drásticamente el tiempo de exposición, que es lo que realmente cuesta dinero.
Ruido operativo y desgaste humano
El monitoreo reactivo suele generar:
El enfoque proactivo reduce ruido porque prioriza señales relevantes, no cada fluctuación irrelevante.
Ejemplos reales donde un enfoque proactivo habría evitado incidentes
Caso 1: degradación lenta en checkout
Un e-commerce experimenta un aumento gradual en la latencia del checkout durante varias horas. No se superan umbrales fijos, por lo que no hay alertas. La conversión cae un 8%.
Un enfoque proactivo habría detectado el patrón anómalo de latencia antes de que el impacto fuera significativo.
Caso 2: agotamiento progresivo de connection pools
Un servicio comienza a mostrar mayor variabilidad en tiempos de respuesta debido a saturación de conexiones. El servicio nunca cae, pero se vuelve inestable.
El monitoreo reactivo no alerta. El proactivo detecta el jitter creciente y permite actuar antes del colapso.
Caso 3: dependencia externa degradada
Una API externa responde más lento de lo normal, sin errores. El impacto se propaga a flujos internos.
El monitoreo reactivo ve “todo arriba”. El proactivo detecta la desviación de comportamiento.
Cómo migrar progresivamente hacia un modelo de monitoreo proactivo
Migrar no significa tirar lo que ya existe. El cambio debe ser incremental.
Paso 1: aceptar que “estar arriba” no es suficiente
El primer cambio es conceptual. La disponibilidad binaria no refleja la experiencia real del usuario.
Paso 2: identificar flujos críticos de negocio
No todo debe monitorearse igual. Identifica:
Estos flujos deben ser el foco del monitoreo proactivo.
Paso 3: incorporar monitoreo de comportamiento
Empieza a observar:
No solo valores absolutos.
Paso 4: reducir ruido antes de agregar más señales
Menos alertas, mejor contexto.
Paso 5: preparar respuestas antes del incidente
Playbooks, mitigaciones y automatización.
El rol de la IA en la anticipación de fallas
La inteligencia artificial no reemplaza al monitoreo proactivo, lo potencia.
La IA permite:
Aquí es donde el monitoreo proactivo se convierte en una ventaja competitiva real y sostenida.
Conclusión: la nueva norma es actuar antes de que el usuario sienta el impacto
El monitoreo reactivo seguirá existiendo, pero ya no puede ser el centro de la operación. En plataformas modernas, reaccionar rápido no es suficiente cuando el daño ocurre en segundos.
El monitoreo proactivo representa un cambio cultural: pasar de confirmar fallos a prevenir impactos, de apagar incendios a reducir su probabilidad.
Las organizaciones que adoptan este enfoque no solo reducen downtime, sino que mejoran la experiencia del usuario, reducen costos operativos y protegen a sus equipos.
Si quieres empezar a evolucionar desde un monitoreo reactivo hacia un modelo más proactivo y preventivo, te invitamos a comenzar con UptimeBolt a través de una prueba gratuita y dar el primer paso hacia una operación más estable, predecible y resiliente.