En la mayoría de las organizaciones digitales, el downtime no ocurre de forma repentina ni completamente inesperada.
Antes de una caída crítica, casi siempre existen señales previas: cambios sutiles en el rendimiento, comportamientos atípicos en ciertos flujos, errores intermitentes o variaciones que, de forma aislada, parecen normales.
El problema es que los sistemas tradicionales de monitoreo no están diseñados para detectar lo “anormal”, sino solo lo que cruza un umbral explícito. Cuando el sistema finalmente “alerta”, el impacto ya está ocurriendo.
Aquí es donde la detección de anomalías con inteligencia artificial cambia radicalmente el enfoque: en lugar de esperar a que algo sea claramente crítico, permite identificar desviaciones tempranas del comportamiento normal y actuar antes de que el usuario final sienta el impacto.
¡Conoce más en las próximas líneas!
El monitoreo clásico responde a una lógica binaria:
“todo está bien” o “algo está roto”.
La realidad operativa es mucho más compleja. Los sistemas modernos rara vez pasan de un estado saludable a una caída total de forma instantánea. La mayoría de los incidentes siguen un patrón progresivo:
- Aumentos graduales de latencia
- Errores intermitentes de baja frecuencia
- Cambios de comportamiento en ciertos endpoints
- Saturación lenta de recursos
- Dependencias externas que empiezan a responder peor
Estas señales no suelen disparar alertas tradicionales, pero son exactamente las señales que permiten prevenir incidentes si se detectan a tiempo.
La detección de anomalías se enfoca en ese espacio intermedio: el momento en el que algo aún funciona, pero ya no se comporta como debería.
Uno de los errores más comunes es usar “anomalía” e “incidente” como sinónimos. No lo son.
Una anomalía es cualquier comportamiento que se desvía del patrón normal esperado de un sistema, incluso si todavía no genera errores visibles ni afecta directamente al usuario.
- Aumento de
connection_reset del 0.001% al 0.05% en un balanceador de carga específico, sin que el error rate general haya cruzado el umbral de alerta
- Latencia p95 que aumenta un 25% respecto a su comportamiento histórico
- Un endpoint que empieza a mostrar mayor variabilidad en tiempos de respuesta
- Un flujo E2E que tarda más en completarse en ciertos horarios
- Un servicio que responde correctamente, pero con mayor jitter
Un incidente ocurre cuando el impacto ya es evidente:
- Caídas
- Errores masivos
- Flujos rotos
- Incumplimiento de SLAs
La detección de anomalías permite intervenir antes de que la anomalía escale a incidente, reduciendo downtime, MTTR y daño operativo.
Los umbrales fijos funcionan bajo supuestos que ya no se sostienen en sistemas modernos:
- El comportamiento del sistema es estable
- Los límites son claros y predecibles
- Un valor “malo” es siempre el mismo
En la práctica:
- Los sistemas cambian constantemente
- El tráfico varía por horario, región y evento
- Un valor aceptable hoy puede ser anómalo mañana
Esto genera dos problemas graves:
- Falsos positivos cuando los umbrales son muy estrictos
- Falsos negativos cuando los umbrales son demasiado laxos
La detección de anomalías con IA no se basa en reglas estáticas. Se basa en aprender cómo se comporta el sistema realmente, considerando:
- Tendencias históricas
- Estacionalidad
- Patrones por servicio, flujo y horario
- Variabilidad normal vs. anómala
En lugar de preguntar “¿superó el límite?”, la IA pregunta:
“¿Este comportamiento es normal para este sistema, en este contexto y en este momento?”
Ese cambio de pregunta lo cambia todo.
Incluso los equipos más experimentados tienen límites cognitivos. Un SRE no puede correlacionar cientos de métricas, logs y flujos en tiempo real.
La IA sí puede.
Los modelos analizan métricas como:
- Latencia
- Errores
- Throughput
- Tiempos de ejecución
Identificando desviaciones estadísticas y cambios de tendencia que no son evidentes a simple vista.
Una anomalía rara vez se explica por una sola métrica. La IA correlaciona:
- Métricas técnicas
- Resultados de flujos E2E
- Señales de APIs
- Dependencias externas
Esto permite detectar patrones compuestos que, mediante Machine Learning, se proyectan a un riesgo de incidente del 75% en los próximos 30 minutos.
La IA entiende el contexto operativo:
- Hora del día
- Día de la semana
- Eventos conocidos
- Comportamiento histórico
Reduciendo drásticamente el ruido.
Una base de datos comienza a mostrar un aumento gradual de latencia en consultas específicas. Ningún umbral se supera. Cuatro horas después, el pool de conexiones se satura y el sistema cae.
La anomalía estaba ahí desde el inicio.
Una API de pagos responde correctamente, pero con mayor variabilidad. El error rate sigue bajo. Minutos después, comienzan los timeouts masivos.
La anomalía precedió al incidente.
El login funciona, pero tarda más. Los usuarios empiezan a abandonar antes de que el sistema “falle”.
La anomalía ya estaba impactando el negocio.
La detección temprana de anomalías tiene efectos directos y medibles:
- Reducción del MTTD al detectar problemas antes de que sean visibles
- Menor MTTR porque el diagnóstico comienza antes
- Menos downtime acumulado
- Menor impacto en SLAs y experiencia de usuario
Equipos que incorporan detección de anomalías suelen pasar de:
“reaccionar a incidentes”
a
“prevenirlos o mitigarlos antes”
Desde una perspectiva ejecutiva, entrenar un modelo de detección de anomalías implica tres pasos clave:
- Recolectar datos históricos suficientes
- Aprender el comportamiento normal del sistema
- Ajustar sensibilidad para maximizar señal y minimizar ruido
No se trata de “enseñar qué está mal”, sino de enseñar qué es normal.
Esto permite que el modelo detecte desviaciones incluso cuando no existen ejemplos previos de fallo.
Para equipos SRE y DevOps más técnicos, el proceso incluye:
- Modelos de series de tiempo para métricas
- Detección estadística y machine learning
- Ventanas dinámicas de análisis
- Umbrales adaptativos basados en contexto
Un punto crítico es la validación de anomalías. Sin validación, la mayoría de las herramientas generan demasiados falsos positivos.
Aquí es donde muchas soluciones fallan.
La detección de anomalías tiene mala fama por una razón: mal implementada, genera ruido.
UptimeBolt aborda este problema combinando:
- Validación cruzada de señales
- Contexto histórico
- Impacto en flujos reales
- Correlación automática
Solo cuando una anomalía muestra potencial impacto real, se convierte en alerta.
Esto permite alcanzar niveles de precisión significativamente mayores que los enfoques tradicionales basados en umbrales o modelos aislados.
Alcanzamos una precisión del 99.8%, reduciendo el ruido operativo en un 80% respecto a la media de la industria.
UptimeBolt utiliza detección de anomalías como parte de una estrategia más amplia de monitoreo inteligente:
- Identifica desviaciones tempranas
- Correlaciona métricas, flujos y dependencias
- Prioriza riesgos reales
- Reduce ruido operativo
- Anticipa incidentes antes de que escalen
El resultado es una operación más estable, predecible y con menor costo operativo.
**
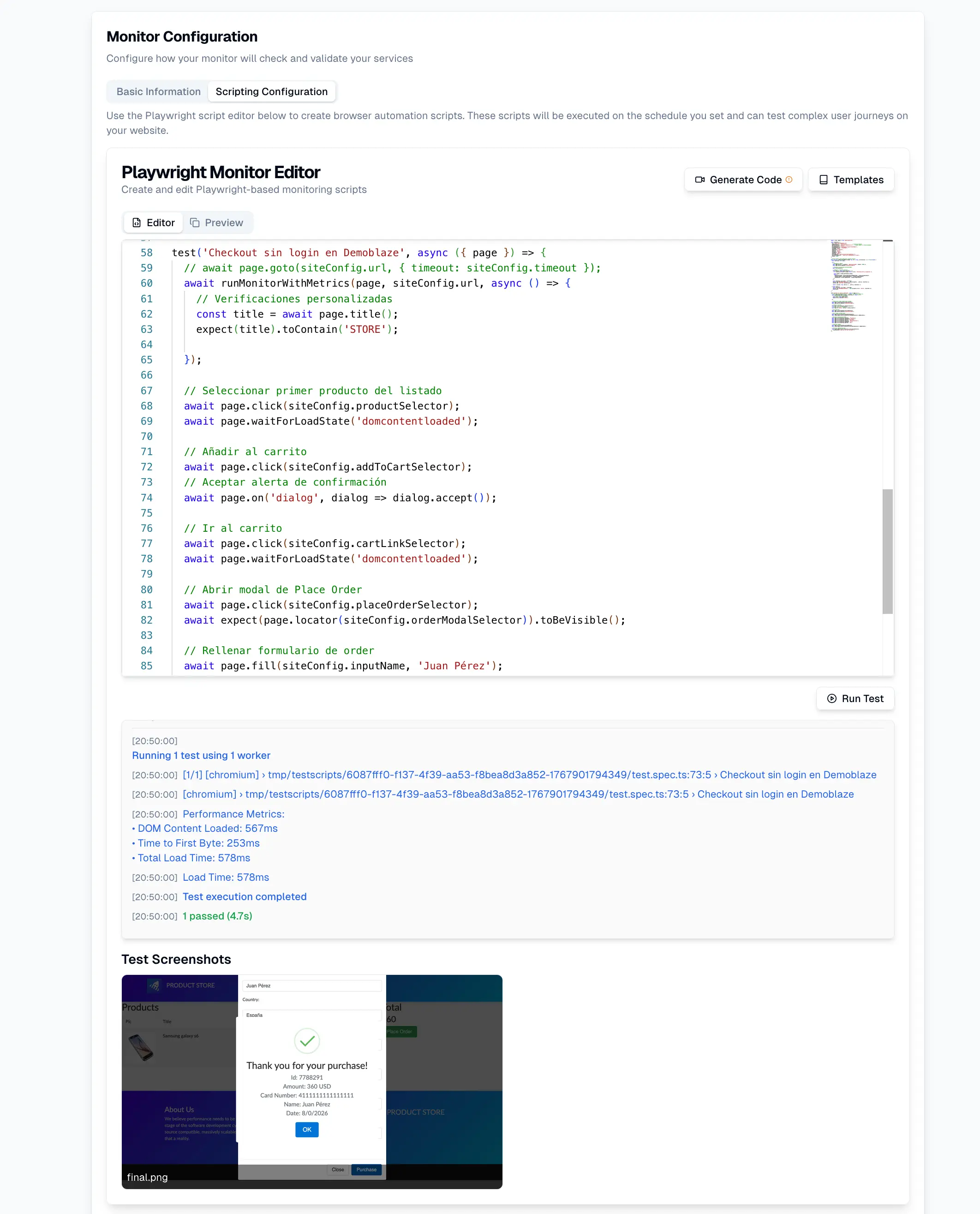
El futuro de la fiabilidad no está en más alertas ni más dashboards. Está en entender cuándo un sistema empieza a comportarse de forma anormal, incluso si todavía “funciona”.
La detección de anomalías con IA permite cerrar la brecha entre lo que el sistema hace y lo que debería hacer, transformando el monitoreo de reactivo a preventivo.
Detectar lo anormal a tiempo no es solo una mejora técnica. Es una ventaja operativa y competitiva.
¡Comienza una prueba para conocer más!
En la mayoría de las organizaciones digitales, el downtime no ocurre de forma repentina ni completamente inesperada.
Antes de una caída crítica, casi siempre existen señales previas: cambios sutiles en el rendimiento, comportamientos atípicos en ciertos flujos, errores intermitentes o variaciones que, de forma aislada, parecen normales.
El problema es que los sistemas tradicionales de monitoreo no están diseñados para detectar lo “anormal”, sino solo lo que cruza un umbral explícito. Cuando el sistema finalmente “alerta”, el impacto ya está ocurriendo.
Aquí es donde la detección de anomalías con inteligencia artificial cambia radicalmente el enfoque: en lugar de esperar a que algo sea claramente crítico, permite identificar desviaciones tempranas del comportamiento normal y actuar antes de que el usuario final sienta el impacto.
¡Conoce más en las próximas líneas!
La importancia de detectar lo “anormal” antes que lo “crítico” a través de la observabilidad
El monitoreo clásico responde a una lógica binaria:
La realidad operativa es mucho más compleja. Los sistemas modernos rara vez pasan de un estado saludable a una caída total de forma instantánea. La mayoría de los incidentes siguen un patrón progresivo:
Estas señales no suelen disparar alertas tradicionales, pero son exactamente las señales que permiten prevenir incidentes si se detectan a tiempo.
La detección de anomalías se enfoca en ese espacio intermedio: el momento en el que algo aún funciona, pero ya no se comporta como debería.
Qué es una anomalía y cómo se diferencia de un incidente
Uno de los errores más comunes es usar “anomalía” e “incidente” como sinónimos. No lo son.
Qué es una anomalía
Una anomalía es cualquier comportamiento que se desvía del patrón normal esperado de un sistema, incluso si todavía no genera errores visibles ni afecta directamente al usuario.
Ejemplos
connection_resetdel 0.001% al 0.05% en un balanceador de carga específico, sin que el error rate general haya cruzado el umbral de alertaQué es un incidente
Un incidente ocurre cuando el impacto ya es evidente:
La detección de anomalías permite intervenir antes de que la anomalía escale a incidente, reduciendo downtime, MTTR y daño operativo.
IA vs. umbrales fijos: la diferencia clave en la detección de problemas
Limitaciones de los umbrales fijos
Los umbrales fijos funcionan bajo supuestos que ya no se sostienen en sistemas modernos:
En la práctica:
Esto genera dos problemas graves:
Cómo la IA supera estos límites
La detección de anomalías con IA no se basa en reglas estáticas. Se basa en aprender cómo se comporta el sistema realmente, considerando:
En lugar de preguntar “¿superó el límite?”, la IA pregunta:
Ese cambio de pregunta lo cambia todo.
Cómo la IA detecta anomalías que un humano jamás vería
Incluso los equipos más experimentados tienen límites cognitivos. Un SRE no puede correlacionar cientos de métricas, logs y flujos en tiempo real.
La IA sí puede.
Análisis de series de tiempo
Los modelos analizan métricas como:
Identificando desviaciones estadísticas y cambios de tendencia que no son evidentes a simple vista.
Correlación de múltiples señales
Una anomalía rara vez se explica por una sola métrica. La IA correlaciona:
Esto permite detectar patrones compuestos que, mediante Machine Learning, se proyectan a un riesgo de incidente del 75% en los próximos 30 minutos.
Contexto automático
La IA entiende el contexto operativo:
Reduciendo drásticamente el ruido.
Ejemplos reales de anomalías que anticipan fallas
Degradación progresiva de base de datos
Una base de datos comienza a mostrar un aumento gradual de latencia en consultas específicas. Ningún umbral se supera. Cuatro horas después, el pool de conexiones se satura y el sistema cae.
La anomalía estaba ahí desde el inicio.
API externa con comportamiento errático
Una API de pagos responde correctamente, pero con mayor variabilidad. El error rate sigue bajo. Minutos después, comienzan los timeouts masivos.
La anomalía precedió al incidente.
Flujos E2E más lentos sin errores
El login funciona, pero tarda más. Los usuarios empiezan a abandonar antes de que el sistema “falle”.
La anomalía ya estaba impactando el negocio.
Impacto directo en la reducción del downtime y el MTTR
La detección temprana de anomalías tiene efectos directos y medibles:
Equipos que incorporan detección de anomalías suelen pasar de:
Cómo se entrena un modelo de detección de anomalías (visión ejecutiva)
Desde una perspectiva ejecutiva, entrenar un modelo de detección de anomalías implica tres pasos clave:
No se trata de “enseñar qué está mal”, sino de enseñar qué es normal.
Esto permite que el modelo detecte desviaciones incluso cuando no existen ejemplos previos de fallo.
Deep dive técnico: entrenamiento y validación de modelos
Para equipos SRE y DevOps más técnicos, el proceso incluye:
Un punto crítico es la validación de anomalías. Sin validación, la mayoría de las herramientas generan demasiados falsos positivos.
Aquí es donde muchas soluciones fallan.
El problema de los falsos positivos (y cómo UptimeBolt lo resuelve)
La detección de anomalías tiene mala fama por una razón: mal implementada, genera ruido.
UptimeBolt aborda este problema combinando:
Solo cuando una anomalía muestra potencial impacto real, se convierte en alerta.
Esto permite alcanzar niveles de precisión significativamente mayores que los enfoques tradicionales basados en umbrales o modelos aislados.
Alcanzamos una precisión del 99.8%, reduciendo el ruido operativo en un 80% respecto a la media de la industria.
Cómo UptimeBolt reduce downtime con anomalías predictivas
UptimeBolt utiliza detección de anomalías como parte de una estrategia más amplia de monitoreo inteligente:
El resultado es una operación más estable, predecible y con menor costo operativo.
**Si quieres optimizar el monitoreo en tu operación y reducir downtime mediante detección inteligente de anomalías, te invitamos a comenzar con UptimeBolt a través de una prueba gratuita.
**
Conclusión: la detección temprana es la clave de la estabilidad operativa
El futuro de la fiabilidad no está en más alertas ni más dashboards. Está en entender cuándo un sistema empieza a comportarse de forma anormal, incluso si todavía “funciona”.
La detección de anomalías con IA permite cerrar la brecha entre lo que el sistema hace y lo que debería hacer, transformando el monitoreo de reactivo a preventivo.
Detectar lo anormal a tiempo no es solo una mejora técnica. Es una ventaja operativa y competitiva.
¡Comienza una prueba para conocer más!