Durante años, muchas organizaciones han medido la salud de sus servicios digitales con una métrica simple: uptime. Si el sistema está “arriba”, todo está bien. Si está caído, hay un problema.
Ese modelo ya no es suficiente.
A medida que las organizaciones evolucionan hacia arquitecturas distribuidas —microservicios, APIs, integraciones externas y sistemas event-driven— también cambia la forma en que debe definirse y medirse la “salud” de un servicio. En este contexto, los Service Level Objectives (SLO) basados únicamente en uptime resultan insuficientes para reflejar la complejidad real del sistema.
Hoy, un servicio puede cumplir formalmente con un SLO de disponibilidad (respondiendo 200 OK) y, aun así, estar completamente degradado desde la perspectiva del usuario final. La disponibilidad técnica ya no garantiza una experiencia funcional ni un impacto positivo en el negocio.
Un checkout que tarda 8 segundos, una API que responde con datos incompletos o un login que falla intermitentemente no siempre disparan alertas tradicionales, pero sí destruyen conversiones, ingresos y confianza.
La salud de servicios digitales no se trata solo de disponibilidad, sino de una combinación de:
- Rendimiento real
- Experiencia del usuario
- Estabilidad operativa
- Consistencia funcional
- Impacto en negocio
En este artículo vamos a construir una forma más completa —y accionable— de medir esa salud.
Para entender la salud de un servicio, es útil pensar en tres pilares fundamentales:
Es la capacidad del sistema para responder correctamente a las solicitudes.
Pero aquí hay una trampa común:
disponible no significa útil.
Un endpoint puede responder con 200 OK y aun así devolver datos vacíos o incorrectos. Allí es donde entra en juego el Functional Availability o Business Transaction Availability.
No basta con responder, hay que responder rápido.
Desde la experiencia del usuario:
- 1 segundo: empieza la fricción
- 3 segundos: aumenta el abandono
- 5 segundos: impacto directo en conversión
En sistemas críticos, los percentiles altos (p95/p99) son más importantes que el promedio.
Se refiere a la consistencia del comportamiento en el tiempo.
Un sistema inestable no siempre falla completamente, pero:
- Tiene errores intermitentes
- Presenta latencias variables
- Se degrada bajo carga
Esto es especialmente peligroso porque es difícil de detectar con monitoreo tradicional.
La clave está en medir el jitter o la desviación estándar de la latencia, lo cual requiere monitoreo predictivo.
El problema no es la falta de métricas, sino medir lo incorrecto o interpretarlo mal.
Indicadores relevantes:
- % de requests exitosas (SLI real)
- Éxito de flujos críticos (login, checkout, pago)
- Errores funcionales (no solo HTTP errors)
Ejemplo:
- 99.9% uptime → parece saludable
- Pero 2% de fallos en checkout → impacto directo en revenue
Indicadores clave:
- Latencia p95 y p99
- Tiempo total de flujo (E2E)
- Tiempo en pasos críticos
Ejemplo:
- Promedio: 300 ms
- p95: 2.5 s
El sistema parece rápido, pero el 5% de usuarios tiene una experiencia mala.
Indicadores importantes:
- Variabilidad de latencia
- Frecuencia de errores intermitentes
- Comportamiento bajo carga
Ejemplo:
- API estable en testing
- En producción, picos de latencia cada 10 minutos
Esto es degradación, no falla.
Aquí es donde la mayoría de los equipos pierde visibilidad.
No todos los errores son evidentes. De hecho, los más peligrosos no lo son.
- Una API responde 200 OK pero el body está vacío
- El login funciona, pero tarda 8 segundos
- El pago se procesa, pero no se confirma visualmente
- Un microservicio devuelve datos inconsistentes
- Una integración externa responde lento, pero no falla
Desde el punto de vista técnico, el sistema está “funcionando”.
Desde el punto de vista del usuario, está roto.
Antes de una caída, casi siempre hay señales:
- Latencia sube de 200 ms → 400 ms → 900 ms
- Errores pasan de 0.1% → 0.5% → 1%
- Requests empiezan a fallar solo en ciertos casos
- El tiempo de respuesta p95 excede nuestro SLO de 1.5s, pero el servicio sigue "arriba" (SLA)
Estas degradaciones:
- No cruzan umbrales estáticos
- No disparan alertas inmediatas
- Pero afectan negocio directamente
Un 1% de fallo puede parecer pequeño, pero:
- 100,000 requests → 1,000 fallidas
- Si son pagos → impacto directo en revenue
- Si son logins → pérdida de usuarios activos
Este tipo de problemas consume error budget sin que el equipo lo note.
Para aterrizar esto, aquí tienes un modelo tipo semáforo que los equipos pueden implementar, basado en un framework para SLO/Health Scorecard que permite la gestión de Error Budget basado en experiencia de usuario.
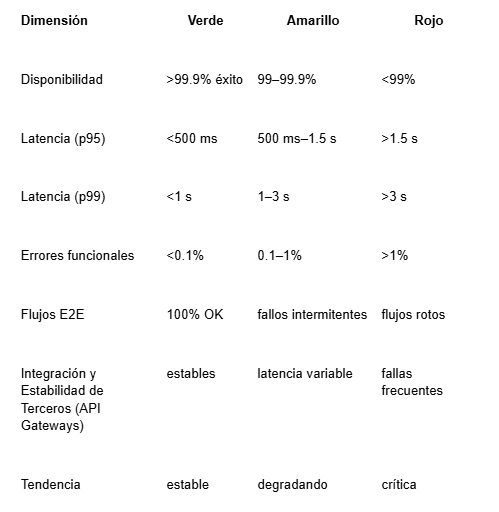
- Evaluar cada dimensión diariamente
- No depender de una sola métrica
- Priorizar lo que impacta negocio
- Visualizar salud como conjunto, no como KPI aislado
Este tipo de scorecard permite conversaciones reales entre:
- Ingeniería
- Producto
- Negocio
El monitoreo tradicional observa partes del sistema.
El problema es que el usuario no experimenta partes.
Experimenta flujos completos.
- Login completo
- Navegación
- Checkout
- Pago
- Confirmación
- Integraciones rotas
- Errores de frontend
- Problemas de sesión
- Fallos en pasos intermedios
Ejemplo:
- API responde OK
- Base de datos OK
- Pero el flujo completo falla
Solo el E2E lo detecta.
Porque mide lo único que importa:
¿El usuario logró su objetivo?
Las métricas muestran el presente.
La IA permite anticipar el futuro.
- Detecta anomalías antes de umbrales
- Identifica patrones invisibles
- Correlaciona señales automáticamente
- Prioriza lo relevante
Sin IA:
- Alertas cuando latencia > 1s
Con IA:
- Detecta cambio de patrón en 300 ms → 500 ms
- Predice saturación en 2 horas
- Reduce MTTD
- Reduce MTTR
- Evita incidentes antes de ocurrir
Esto transforma la salud de reactiva a preventiva.
UptimeBolt no busca reemplazar toda la observabilidad, sino hacerla más accionable.
Se posiciona como una capa que conecta:
- Monitoreo
- Experiencia real (E2E)
- Predicción con IA
- Monitorear flujos críticos completos
- Detectar anomalías en tiempo real
- Analizar comportamiento histórico
- Anticipar incidentes
- Reducir ruido de alertas
El sistema no ha fallado, pero:
- Latencia en “Procesar Pago” sube 15%
- Solo en ciertas regiones
- Solo en ciertas horas
Un monitoreo tradicional no alerta. UptimeBolt sí, porque detecta desviación.
- Problema identificado antes de impacto
- Acción temprana
- Menor pérdida de ingresos
- Mejores SLOs
La salud de servicios digitales no se mide con uptime.
Se mide con la capacidad del sistema de:
- Responder correctamente
- Mantener rendimiento consistente
- Adaptarse sin degradarse
- Anticipar fallos
Un sistema saludable:
- Es estable
- Es rápido
- Es predecible
Las organizaciones que entienden esto dejan de reaccionar a incidentes y empiezan a operar con control.
Y en un entorno donde cada segundo de degradación impacta directamente en ingresos, esa diferencia no es técnica.
Es estratégica.
Si quieres medir y mejorar la salud real de tus servicios —más allá del uptime— te invitamos a comenzar con UptimeBolt a través de una prueba gratuita.
Durante años, muchas organizaciones han medido la salud de sus servicios digitales con una métrica simple: uptime. Si el sistema está “arriba”, todo está bien. Si está caído, hay un problema.
Ese modelo ya no es suficiente.
A medida que las organizaciones evolucionan hacia arquitecturas distribuidas —microservicios, APIs, integraciones externas y sistemas event-driven— también cambia la forma en que debe definirse y medirse la “salud” de un servicio. En este contexto, los Service Level Objectives (SLO) basados únicamente en uptime resultan insuficientes para reflejar la complejidad real del sistema.
Hoy, un servicio puede cumplir formalmente con un SLO de disponibilidad (respondiendo 200 OK) y, aun así, estar completamente degradado desde la perspectiva del usuario final. La disponibilidad técnica ya no garantiza una experiencia funcional ni un impacto positivo en el negocio.
Un checkout que tarda 8 segundos, una API que responde con datos incompletos o un login que falla intermitentemente no siempre disparan alertas tradicionales, pero sí destruyen conversiones, ingresos y confianza.
La salud de servicios digitales no se trata solo de disponibilidad, sino de una combinación de:
En este artículo vamos a construir una forma más completa —y accionable— de medir esa salud.
Los pilares de la salud digital: disponibilidad, rendimiento y estabilidad
Para entender la salud de un servicio, es útil pensar en tres pilares fundamentales:
1. Disponibilidad (Availability)
Es la capacidad del sistema para responder correctamente a las solicitudes.
Pero aquí hay una trampa común:
disponible no significa útil.
Un endpoint puede responder con 200 OK y aun así devolver datos vacíos o incorrectos. Allí es donde entra en juego el Functional Availability o Business Transaction Availability.
2. Rendimiento (Performance)
No basta con responder, hay que responder rápido.
Desde la experiencia del usuario:
En sistemas críticos, los percentiles altos (p95/p99) son más importantes que el promedio.
3. Estabilidad (Stability)
Se refiere a la consistencia del comportamiento en el tiempo.
Un sistema inestable no siempre falla completamente, pero:
Esto es especialmente peligroso porque es difícil de detectar con monitoreo tradicional.
La clave está en medir el jitter o la desviación estándar de la latencia, lo cual requiere monitoreo predictivo.
Cómo medir cada uno y qué indicadores importan realmente
El problema no es la falta de métricas, sino medir lo incorrecto o interpretarlo mal.
Disponibilidad real (no teórica)
Indicadores relevantes:
Ejemplo:
Rendimiento centrado en el usuario
Indicadores clave:
Ejemplo:
El sistema parece rápido, pero el 5% de usuarios tiene una experiencia mala.
Estabilidad operativa
Indicadores importantes:
Ejemplo:
Esto es degradación, no falla.
Errores silenciosos y degradación: el riesgo de los falsos positivos técnicos
Aquí es donde la mayoría de los equipos pierde visibilidad.
No todos los errores son evidentes. De hecho, los más peligrosos no lo son.
Ejemplos reales de errores silenciosos
Desde el punto de vista técnico, el sistema está “funcionando”.
Desde el punto de vista del usuario, está roto.
Degradaciones progresivas
Antes de una caída, casi siempre hay señales:
Estas degradaciones:
Impacto real
Un 1% de fallo puede parecer pequeño, pero:
Este tipo de problemas consume error budget sin que el equipo lo note.
Framework práctico: scorecard de salud de servicios digitales
Para aterrizar esto, aquí tienes un modelo tipo semáforo que los equipos pueden implementar, basado en un framework para SLO/Health Scorecard que permite la gestión de Error Budget basado en experiencia de usuario.
Dimensiones de salud
Cómo usarlo
Este tipo de scorecard permite conversaciones reales entre:
La importancia del monitoreo E2E para validar la experiencia real
El monitoreo tradicional observa partes del sistema.
El problema es que el usuario no experimenta partes.
Experimenta flujos completos.
Qué valida el monitoreo E2E
Qué detecta que otros enfoques no ven
Ejemplo:
Solo el E2E lo detecta.
Por qué es clave para la salud real
Porque mide lo único que importa:
¿El usuario logró su objetivo?
Cómo la IA complementa las métricas tradicionales con predicción
Las métricas muestran el presente.
La IA permite anticipar el futuro.
Qué hace la IA en este contexto
Ejemplo práctico
Sin IA:
Con IA:
Impacto en salud del servicio
Esto transforma la salud de reactiva a preventiva.
Cómo UptimeBolt consolida salud, estabilidad y predicción en un solo panel
UptimeBolt no busca reemplazar toda la observabilidad, sino hacerla más accionable.
Se posiciona como una capa que conecta:
Qué permite hacer
Ejemplo concreto
El sistema no ha fallado, pero:
Un monitoreo tradicional no alerta. UptimeBolt sí, porque detecta desviación.
Resultado
Conclusión: un servicio saludable es estable, rápido y predecible
La salud de servicios digitales no se mide con uptime.
Se mide con la capacidad del sistema de:
Un sistema saludable:
Las organizaciones que entienden esto dejan de reaccionar a incidentes y empiezan a operar con control.
Y en un entorno donde cada segundo de degradación impacta directamente en ingresos, esa diferencia no es técnica.
Es estratégica.
Si quieres medir y mejorar la salud real de tus servicios —más allá del uptime— te invitamos a comenzar con UptimeBolt a través de una prueba gratuita.