Durante años, el monitoreo ha sido presentado como la principal línea de defensa para garantizar la estabilidad de sistemas críticos. Dashboards bien configurados, métricas clave bajo control, alertas activas las 24 horas. Todo parece indicar que, con suficiente visibilidad, los incidentes graves deberían ser evitables.
La realidad es otra.
Cada año, plataformas críticas de e-commerce, fintech, salud y cloud sufren caídas importantes a pesar de contar con monitoreo “correctamente configurado”. Según Gartner, el costo promedio del downtime para grandes empresas puede superar los $300,000 por hora, lo que amplifica una paradoja incómoda para CTOs y líderes SRE: ¿cómo es posible que sistemas con buena observabilidad sigan fallando de forma tan costosa?
La respuesta no es que el monitoreo sea inútil, sino que el monitoreo tradicional tiene límites estructurales frente a la complejidad moderna. Entender esas limitaciones —y cómo superarlas— es clave para construir verdadera resiliencia digital.
A continuación abordamos la falsa sensación de seguridad que genera el “buen monitoreo”, analizamos por qué los sistemas críticos siguen fallando y explicamos cómo la inteligencia artificial cubre las brechas que los enfoques tradicionales no pueden resolver.
En muchas organizaciones, el monitoreo se evalúa por su cobertura técnica:
- ¿Tenemos métricas de CPU, memoria y red?
- ¿Monitoreamos APIs?
- ¿Tenemos alertas configuradas para errores?
- ¿Cobertura de distributed tracing?
Si la respuesta es “sí”, se asume que el sistema está protegido.
El problema es que la mayoría de los incidentes críticos no comienzan con una señal clara, ni cumplen exactamente las condiciones que disparan una alerta. Empiezan como anomalías sutiles, degradaciones lentas o combinaciones de factores que, de forma aislada, parecen inofensivos.
Esto genera una peligrosa ilusión: el sistema “se ve bien” en los dashboards… hasta que deja de estarlo de forma abrupta.
El monitoreo tradicional se basa en reglas explícitas:
“Si X supera Y, alertar”.
Pero muchos incidentes reales:
- No superan umbrales fijos
- Lo hacen demasiado tarde
- O lo hacen en dimensiones que no se están midiendo
- Latencia que aumenta lentamente, pero nunca cruza el límite
- Errores intermitentes del 0.5–1% que consumen todo el presupuesto de error (SLO) en minutos, pero no disparan alertas tradicionales por volumen total
- Saturación progresiva que se acelera de forma no lineal
- Servicios “up” que dejan de procesar eventos
En retrospectiva, los datos estaban ahí. El problema es que nadie estaba mirando la señal correcta, en el momento correcto.
Los sistemas críticos modernos no fallan solo por problemas internos. Fallan por interacciones complejas entre múltiples componentes, muchos de los cuales están fuera del control directo del equipo.
Pagos, autenticación, proveedores de datos, servicios de terceros. Una pequeña degradación en cualquiera de estos puede:
- Aumentar latencia
- Generar timeouts
- Provocar errores en cascada
El monitoreo tradicional suele tratar estas dependencias como “black boxes”.
En un monolito, el fallo suele ser evidente. En microservicios:
- Un servicio puede fallar parcialmente
- Otro puede compensar temporalmente
- El impacto se acumula de forma no obvia
El resultado es un sistema que “funciona”, pero cada vez peor, hasta que colapsa.
Workers, cron jobs, consumers y procesos internos pueden dejar de ejecutarse sin generar errores visibles. Desde fuera, todo parece normal.
Estos son algunos de los fallos más costosos, porque no generan alertas tradicionales.
Este es uno de los mayores dolores operativos y, paradójicamente, uno de los menos abordados.
Diversos estudios del sector (incluyendo reportes de Google SRE y Atlassian) indican que entre el 30% y el 40% de las alertas en equipos SRE son falsos positivos o de bajo valor. En algunos entornos, esta cifra puede superar el 50%.
- Los equipos se acostumbran a ignorar alertas
- Se pierde sensibilidad ante señales reales
- El tiempo de respuesta aumenta
- El estrés y la rotación del equipo crecen
En este contexto, el monitoreo deja de ser una ayuda y se convierte en ruido.
Un sistema puede “tener monitoreo” y aun así fallar porque las señales importantes se pierden en un mar de alertas irrelevantes.
Para entender la magnitud del problema, basta revisar algunos incidentes ampliamente documentados.
En múltiples caídas de AWS, los postmortems revelaron:
- Métricas disponibles
- Alertas funcionando
- Pero interacciones no anticipadas entre servicios
El monitoreo detectó el fallo cuando ya estaba ocurriendo, pero no anticipó el impacto en cascada.
En incidentes de Cloudflare, el problema no fue falta de datos, sino:
- Cambios de configuración
- Comportamientos no previstos
- Señales tempranas que parecían normales
El sistema estaba monitoreado, pero los patrones de riesgo no eran evidentes sin análisis avanzado.
La caída global de Facebook se debió a cambios en BGP y DNS. El monitoreo interno funcionaba, pero:
- Las dependencias críticas quedaron fuera de alcance
- El impacto fue rápido y masivo
Estos fallos no fueron por falta de datos, sino por falta de contexto y correlación a escala. Esta es la brecha crítica que la IA está diseñada para cerrar.
Aquí es donde la inteligencia artificial cambia el paradigma.
La IA no reemplaza el monitoreo, sino que extrae valor de los datos que ya existen, identificando patrones que los humanos y los sistemas basados en reglas no pueden detectar a tiempo.
La IA no se pregunta solo “¿esto está mal?”, sino:
“¿Esto es normal para este sistema, en este contexto y en este momento?”
Esto permite detectar:
- Cambios sutiles de comportamiento
- Degradaciones lentas
- Variabilidad anómala
En lugar de analizar métricas aisladas, la IA correlaciona:
- Rendimiento
- Errores
- Flujos E2E
- Dependencias externas
Esto reduce falsos positivos y aumenta la precisión.
Al reconocer patrones previos a incidentes históricos, la IA puede alertar horas antes de que el problema se materialice.
No se trata de adivinar, sino de reconocer señales de riesgo.
Una plataforma de e-commerce tenía alertas bien configuradas para latencia y errores. Sin embargo:
- La latencia p95 aumentó gradualmente
- No superó el umbral hasta el pico de tráfico
Resultado: caída durante el momento más crítico del día.
Un error del 0.7% en una API parecía irrelevante. En realidad, rompía el checkout de ciertos usuarios. El monitoreo no alertó; el negocio sí sufrió el impacto.
Un proceso interno dejó de ejecutarse tras un deploy. El sistema estaba “up”. El backlog creció durante horas hasta afectar a clientes.
En todos estos casos, el monitoreo estaba presente, pero no era suficiente.
Superar estas limitaciones requiere un enfoque más maduro.
La experiencia real del usuario debe ser el punto de referencia.
- Eliminar alertas de bajo valor
- Priorizar impacto real
- Usar inteligencia para filtrar ruido
Los umbrales estáticos no se adaptan a sistemas dinámicos.
La resiliencia moderna se construye actuando antes, no apagando incendios.
UptimeBolt ha sido diseñado para cubrir precisamente los puntos donde el monitoreo tradicional falla:
- Detecta anomalías invisibles
- Reduce ruido operativo
- Correlaciona señales técnicas y funcionales
- Anticipa incidentes antes de que impacten
No promete eliminar todos los fallos, pero sí reducir drásticamente su impacto y frecuencia, transformando la operación de reactiva a preventiva.
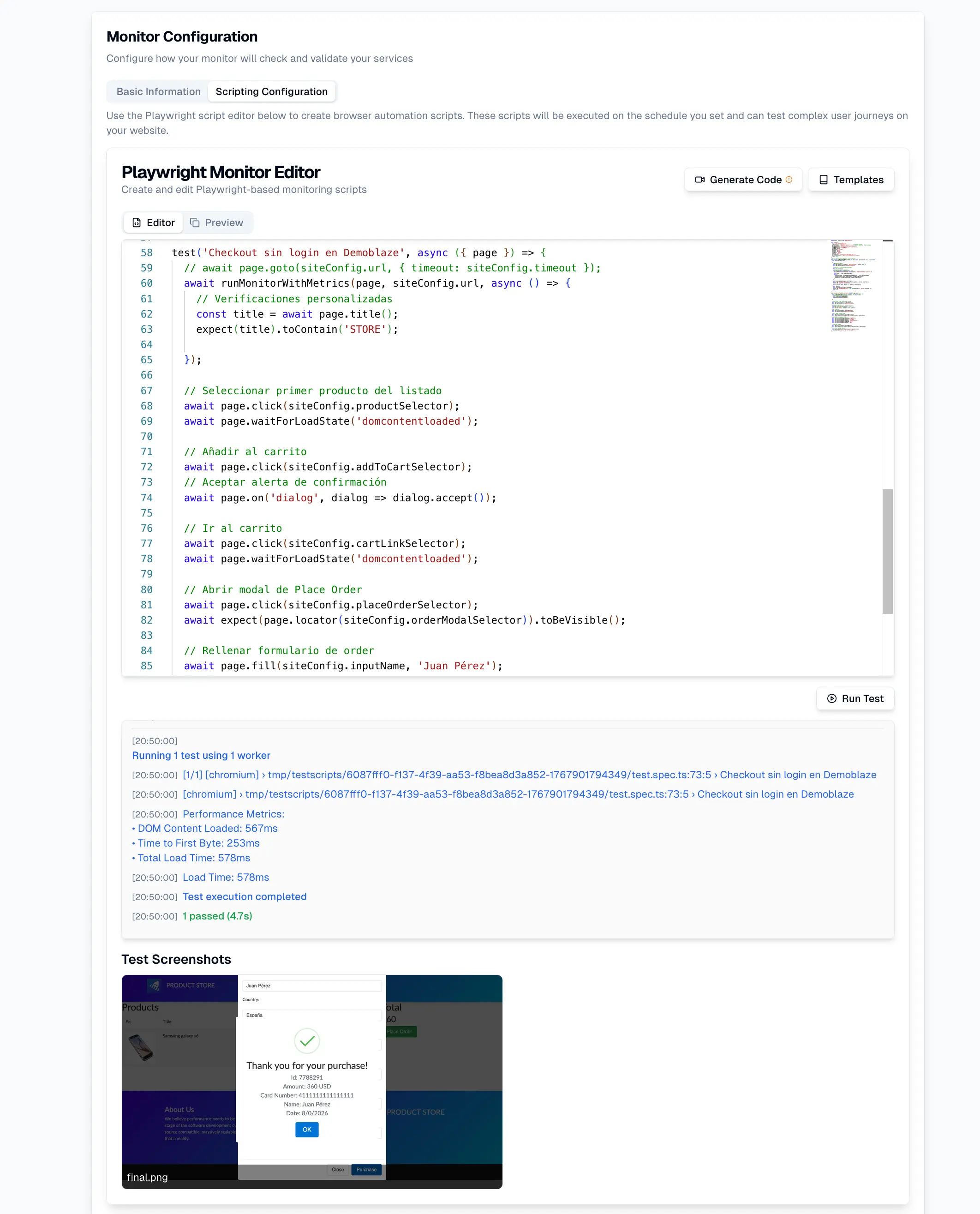
El mayor error hoy no es no tener monitoreo. Es creer que tener monitoreo tradicional es suficiente.
Los sistemas críticos fallan porque la complejidad supera la capacidad humana de interpretación en tiempo real. La solución no es más dashboards ni más alertas, sino más inteligencia aplicada a los datos existentes.
La fiabilidad moderna no se construye reaccionando más rápido, sino anticipando mejor.
Si quieres fortalecer la resiliencia de tus sistemas críticos y evitar fallas que el monitoreo tradicional no puede ver, te invitamos a comenzar con UptimeBolt a través de una prueba gratuita y dar el siguiente paso hacia una operación verdaderamente preventiva.
Durante años, el monitoreo ha sido presentado como la principal línea de defensa para garantizar la estabilidad de sistemas críticos. Dashboards bien configurados, métricas clave bajo control, alertas activas las 24 horas. Todo parece indicar que, con suficiente visibilidad, los incidentes graves deberían ser evitables.
La realidad es otra.
Cada año, plataformas críticas de e-commerce, fintech, salud y cloud sufren caídas importantes a pesar de contar con monitoreo “correctamente configurado”. Según Gartner, el costo promedio del downtime para grandes empresas puede superar los $300,000 por hora, lo que amplifica una paradoja incómoda para CTOs y líderes SRE: ¿cómo es posible que sistemas con buena observabilidad sigan fallando de forma tan costosa?
La respuesta no es que el monitoreo sea inútil, sino que el monitoreo tradicional tiene límites estructurales frente a la complejidad moderna. Entender esas limitaciones —y cómo superarlas— es clave para construir verdadera resiliencia digital.
A continuación abordamos la falsa sensación de seguridad que genera el “buen monitoreo”, analizamos por qué los sistemas críticos siguen fallando y explicamos cómo la inteligencia artificial cubre las brechas que los enfoques tradicionales no pueden resolver.
Cuando el monitoreo “parece” sólido pero falla igual
En muchas organizaciones, el monitoreo se evalúa por su cobertura técnica:
Si la respuesta es “sí”, se asume que el sistema está protegido.
El problema es que la mayoría de los incidentes críticos no comienzan con una señal clara, ni cumplen exactamente las condiciones que disparan una alerta. Empiezan como anomalías sutiles, degradaciones lentas o combinaciones de factores que, de forma aislada, parecen inofensivos.
Esto genera una peligrosa ilusión: el sistema “se ve bien” en los dashboards… hasta que deja de estarlo de forma abrupta.
La realidad incómoda: muchos incidentes no cumplen condiciones de alerta
El monitoreo tradicional se basa en reglas explícitas:
Pero muchos incidentes reales:
Ejemplos comunes
En retrospectiva, los datos estaban ahí. El problema es que nadie estaba mirando la señal correcta, en el momento correcto.
Dependencias, microservicios y puntos invisibles de fallo
Los sistemas críticos modernos no fallan solo por problemas internos. Fallan por interacciones complejas entre múltiples componentes, muchos de los cuales están fuera del control directo del equipo.
Dependencias externas
Pagos, autenticación, proveedores de datos, servicios de terceros. Una pequeña degradación en cualquiera de estos puede:
El monitoreo tradicional suele tratar estas dependencias como “black boxes”.
Microservicios y arquitecturas distribuidas
En un monolito, el fallo suele ser evidente. En microservicios:
El resultado es un sistema que “funciona”, pero cada vez peor, hasta que colapsa.
Fallos silenciosos
Workers, cron jobs, consumers y procesos internos pueden dejar de ejecutarse sin generar errores visibles. Desde fuera, todo parece normal.
Estos son algunos de los fallos más costosos, porque no generan alertas tradicionales.
Alert fatigue: cuando demasiadas alertas esconden los problemas reales
Este es uno de los mayores dolores operativos y, paradójicamente, uno de los menos abordados.
Diversos estudios del sector (incluyendo reportes de Google SRE y Atlassian) indican que entre el 30% y el 40% de las alertas en equipos SRE son falsos positivos o de bajo valor. En algunos entornos, esta cifra puede superar el 50%.
Consecuencias
En este contexto, el monitoreo deja de ser una ayuda y se convierte en ruido.
Un sistema puede “tener monitoreo” y aun así fallar porque las señales importantes se pierden en un mar de alertas irrelevantes.
Postmortems famosos: cuando el monitoreo existía, pero no fue suficiente
Para entender la magnitud del problema, basta revisar algunos incidentes ampliamente documentados.
AWS (us-east-1, 2017 y 2021)
En múltiples caídas de AWS, los postmortems revelaron:
El monitoreo detectó el fallo cuando ya estaba ocurriendo, pero no anticipó el impacto en cascada.
Cloudflare (2020, 2022)
En incidentes de Cloudflare, el problema no fue falta de datos, sino:
El sistema estaba monitoreado, pero los patrones de riesgo no eran evidentes sin análisis avanzado.
Facebook / Meta (2021)
La caída global de Facebook se debió a cambios en BGP y DNS. El monitoreo interno funcionaba, pero:
Estos fallos no fueron por falta de datos, sino por falta de contexto y correlación a escala. Esta es la brecha crítica que la IA está diseñada para cerrar.
Cómo la IA detecta degradaciones invisibles para sistemas tradicionales
Aquí es donde la inteligencia artificial cambia el paradigma.
La IA no reemplaza el monitoreo, sino que extrae valor de los datos que ya existen, identificando patrones que los humanos y los sistemas basados en reglas no pueden detectar a tiempo.
Detección de anomalías contextuales
La IA no se pregunta solo “¿esto está mal?”, sino:
Esto permite detectar:
Correlación de múltiples señales
En lugar de analizar métricas aisladas, la IA correlaciona:
Esto reduce falsos positivos y aumenta la precisión.
Anticipación en lugar de reacción
Al reconocer patrones previos a incidentes históricos, la IA puede alertar horas antes de que el problema se materialice.
No se trata de adivinar, sino de reconocer señales de riesgo.
Ejemplos de incidentes que ocurrieron pese a un monitoreo correcto
Degradación progresiva no detectada
Una plataforma de e-commerce tenía alertas bien configuradas para latencia y errores. Sin embargo:
Resultado: caída durante el momento más crítico del día.
Error intermitente ignorado
Un error del 0.7% en una API parecía irrelevante. En realidad, rompía el checkout de ciertos usuarios. El monitoreo no alertó; el negocio sí sufrió el impacto.
Worker detenido sin alertas
Un proceso interno dejó de ejecutarse tras un deploy. El sistema estaba “up”. El backlog creció durante horas hasta afectar a clientes.
En todos estos casos, el monitoreo estaba presente, pero no era suficiente.
Mejores prácticas para garantizar resiliencia real en sistemas críticos
Superar estas limitaciones requiere un enfoque más maduro.
Monitorear flujos, no solo componentes
La experiencia real del usuario debe ser el punto de referencia.
Reducir alert fatigue de forma activa
Incorporar detección de anomalías
Los umbrales estáticos no se adaptan a sistemas dinámicos.
Anticipar, no solo reaccionar
La resiliencia moderna se construye actuando antes, no apagando incendios.
Cómo UptimeBolt ayuda a cerrar estas brechas
UptimeBolt ha sido diseñado para cubrir precisamente los puntos donde el monitoreo tradicional falla:
No promete eliminar todos los fallos, pero sí reducir drásticamente su impacto y frecuencia, transformando la operación de reactiva a preventiva.
Conclusión: la fiabilidad moderna se basa en anticipación, no reacción
El mayor error hoy no es no tener monitoreo. Es creer que tener monitoreo tradicional es suficiente.
Los sistemas críticos fallan porque la complejidad supera la capacidad humana de interpretación en tiempo real. La solución no es más dashboards ni más alertas, sino más inteligencia aplicada a los datos existentes.
La fiabilidad moderna no se construye reaccionando más rápido, sino anticipando mejor.
Si quieres fortalecer la resiliencia de tus sistemas críticos y evitar fallas que el monitoreo tradicional no puede ver, te invitamos a comenzar con UptimeBolt a través de una prueba gratuita y dar el siguiente paso hacia una operación verdaderamente preventiva.