In the digital economy of 2025, your website's availability isn't just a technical metric—it's the foundation of your business. Every second of downtime translates directly into lost revenue, damaged reputation, and frustrated customers who won't wait for you to come back online.
Uptime refers to the amount of time a system, service, or website remains operational and accessible to users. It's typically expressed as a percentage over a given period, usually calculated monthly or annually.
When we say a website has 99.9% uptime, we're saying it was available and functioning correctly for 99.9% of the measured time period. That remaining 0.1% represents downtime—periods when users couldn't access the service.
The concept seems simple, but the implications are profound. In an always-connected world, users expect services to be available 24/7/365. Any deviation from this expectation creates friction, frustration, and ultimately, customer loss.
 The industry uses "nines" to describe uptime levels. Each additional nine represents a dramatic reduction in allowed downtime.
The industry uses "nines" to describe uptime levels. Each additional nine represents a dramatic reduction in allowed downtime.
Two Nines (99%)
Allows approximately 87.6 hours of downtime per year, or about 7.3 hours per month. This level is generally considered unacceptable for any business-critical service.
Three Nines (99.9%)
Permits roughly 8.76 hours of downtime annually, or about 43.8 minutes monthly. This is the minimum acceptable level for most commercial services.
Four Nines (99.99%)
Reduces allowed downtime to just 52.56 minutes per year, or about 4.38 minutes per month. This level requires sophisticated infrastructure and monitoring.
Five Nines (99.999%)
The gold standard, allowing only 5.26 minutes of downtime per year. Achieving this requires redundancy at every level and is typically seen only in critical infrastructure.
To put this in perspective: the difference between 99% and 99.9% uptime is the difference between being down for three and a half days versus eight hours annually.

According to recent studies, the average cost of IT downtime has risen to over $5,600 per minute for enterprise organizations. For e-commerce sites during peak shopping periods, this figure can be significantly higher.
But it's not just about direct revenue loss. Downtime creates cascading effects that amplify the damage far beyond the immediate financial impact.
Modern users have zero tolerance for unavailability. Studies show that 88% of online consumers are less likely to return to a site after a bad experience, and 79% of dissatisfied customers will share their negative experience with others.
In 2025, your competitors are just one click away. When your site is down, users don't wait—they leave. And they often don't come back.
Google and other search engines factor site reliability into their ranking algorithms. Frequent or prolonged downtime signals poor user experience, which can negatively impact your search visibility.
This creates a compound effect: downtime not only loses you current visitors but also reduces your ability to attract new ones through organic search.
The shift to remote and hybrid work has made SaaS applications and cloud services essential infrastructure. When these services go down, entire organizations stop functioning.
A collaboration tool outage doesn't just inconvenience users—it halts projects, delays deadlines, and disrupts workflows across multiple teams and time zones.
Many industries now have regulations requiring specific uptime levels for customer-facing services. Financial services, healthcare, and government contractors often face strict availability requirements with significant penalties for non-compliance.
Beyond regulations, most B2B contracts include Service Level Agreements (SLAs) with uptime guarantees. Missing these targets can trigger refunds, penalties, or contract termination.
The most obvious cost, but often underestimated. An e-commerce site generating $100,000 daily loses over $4,100 for every hour of downtime. During peak periods like Black Friday, this figure can multiply several times.
When internal systems go down, employees can't work. If 100 employees earning an average of $50/hour lose access to critical systems, that's $5,000 per hour in lost productivity—before counting the impact on deadlines and deliverables.
Getting systems back online isn't free. Emergency IT support, overtime pay, expedited vendor support, and potential hardware replacement all add to the bill. The longer the outage, the higher these costs climb.
Perhaps the most significant long-term cost. Customers remember downtime, especially if it affected them during a critical moment. Rebuilding trust takes time and resources, and some customers never return.
Social media amplifies this effect. A single significant outage can generate negative coverage that persists in search results for months or years.
While your site is down, competitors capture your would-be customers. Some of those customers will discover they prefer the alternative and never return, even after you're back online.
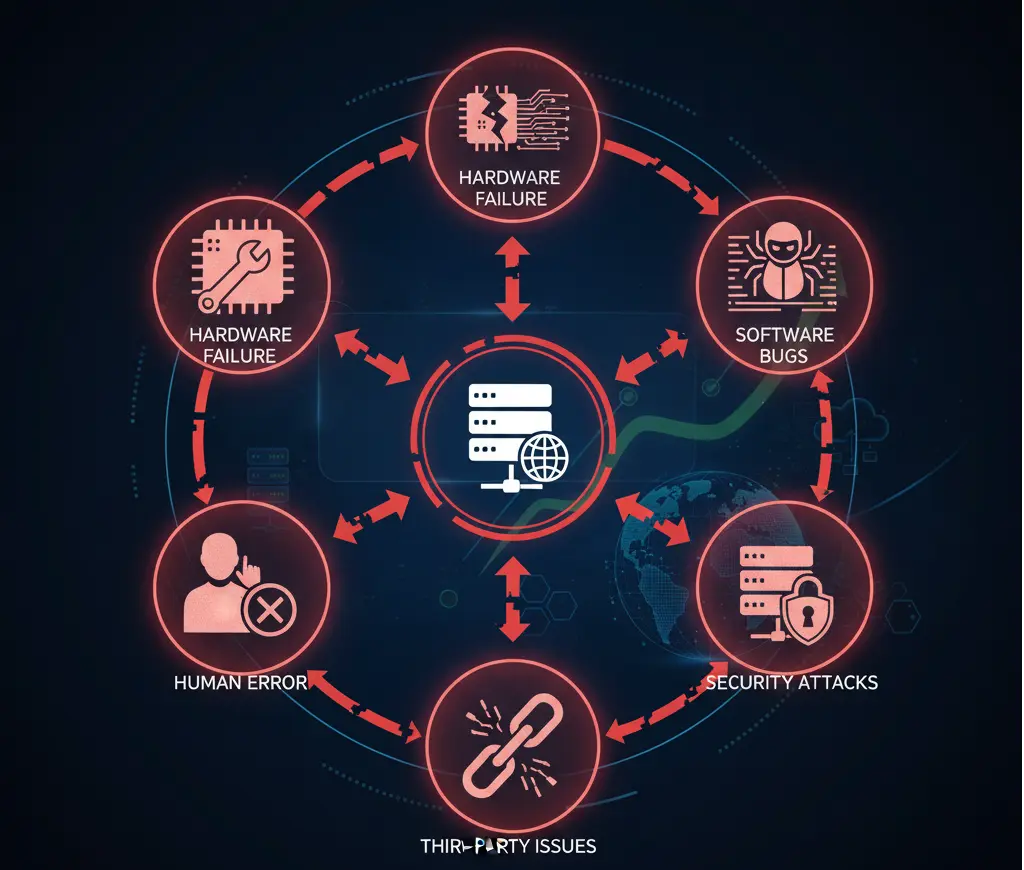 Understanding the causes helps prevent them. Most downtime falls into several categories.
Understanding the causes helps prevent them. Most downtime falls into several categories.
Physical components fail. Servers, storage devices, network equipment, and power systems all have finite lifespans. Without redundancy, a single hardware failure can take down entire services.
Code issues, memory leaks, and unhandled exceptions can crash applications or make them unresponsive. These problems often emerge only under specific conditions or load levels.
Misconfigurations, accidental deletions, and deployment mistakes remain leading causes of outages. Even experienced teams make errors, especially under pressure.
DDoS attacks, ransomware, and other security breaches can render services unavailable. These incidents are often deliberately timed to maximize damage.
Modern applications depend on numerous external services: payment processors, APIs, CDNs, DNS providers, and cloud platforms. When any of these fail, your service may fail with them.
Traffic spikes can overwhelm systems that aren't designed to scale. Viral content, marketing campaigns, or seasonal peaks can generate load that exceeds capacity.
Measuring uptime seems straightforward but requires careful consideration of methodology.
How often do you check? Checking every 5 minutes means you might not detect an outage for up to 5 minutes. Checking every minute provides faster detection but generates more data.
A site might be available in one region but unreachable in another due to network issues, CDN problems, or regional infrastructure failures. Accurate measurement requires checking from multiple locations.
Is the site "up" if it returns a 200 status code but takes 30 seconds to load? What if it returns an error page? Defining uptime requires specifying what constitutes acceptable performance.
Planned maintenance typically doesn't count against uptime metrics, but this requires clear communication and accurate tracking of maintenance periods.
You can't improve what you don't measure. Deploy monitoring that checks your critical systems frequently from multiple geographic locations.
Modern monitoring should include not just availability checks but also performance metrics, SSL certificate expiration tracking, and DNS verification.
Eliminate single points of failure. Use multiple servers, multiple data centers, multiple DNS providers, and multiple network paths. Design systems so that any single component can fail without taking down the service.
Don't wait for humans to respond to alerts at 3 AM. Implement automatic failover, auto-scaling, and self-healing systems that can respond to issues faster than any human.
Regular disaster recovery testing ensures your failover systems actually work when needed. Many organizations discover their backup systems don't function correctly only when they need them most.
Document incident response procedures. When downtime occurs, every second counts. Clear processes reduce confusion and speed recovery.
Understanding uptime is the first step. The second step is measuring it.
If you're not currently monitoring your website's availability, you're flying blind. Issues can persist for hours before anyone notices—usually when a customer complains.
UptimeBolt makes getting started simple. Create your first monitor in 30 seconds and start receiving alerts when issues occur. With AI-powered predictions, you'll often know about problems before they affect your users.
Uptime isn't just a technical metric—it's a business imperative. In 2025, where digital presence equals business presence, availability directly impacts revenue, reputation, and growth.
The organizations that thrive will be those that treat uptime as a strategic priority, not an afterthought. They'll invest in monitoring, redundancy, and rapid response capabilities.
Don't wait for downtime to teach you its importance. Start monitoring today, establish your baseline, and begin the journey toward higher availability.
Your customers expect you to be there when they need you. Make sure you are.
In the digital economy of 2025, your website's availability isn't just a technical metric—it's the foundation of your business. Every second of downtime translates directly into lost revenue, damaged reputation, and frustrated customers who won't wait for you to come back online.
What Exactly is Uptime?
Uptime refers to the amount of time a system, service, or website remains operational and accessible to users. It's typically expressed as a percentage over a given period, usually calculated monthly or annually.
When we say a website has 99.9% uptime, we're saying it was available and functioning correctly for 99.9% of the measured time period. That remaining 0.1% represents downtime—periods when users couldn't access the service.
The concept seems simple, but the implications are profound. In an always-connected world, users expect services to be available 24/7/365. Any deviation from this expectation creates friction, frustration, and ultimately, customer loss.
Understanding the Nines: Uptime Percentages Explained
Two Nines (99%) Allows approximately 87.6 hours of downtime per year, or about 7.3 hours per month. This level is generally considered unacceptable for any business-critical service.
Three Nines (99.9%) Permits roughly 8.76 hours of downtime annually, or about 43.8 minutes monthly. This is the minimum acceptable level for most commercial services.
Four Nines (99.99%) Reduces allowed downtime to just 52.56 minutes per year, or about 4.38 minutes per month. This level requires sophisticated infrastructure and monitoring.
Five Nines (99.999%) The gold standard, allowing only 5.26 minutes of downtime per year. Achieving this requires redundancy at every level and is typically seen only in critical infrastructure.
To put this in perspective: the difference between 99% and 99.9% uptime is the difference between being down for three and a half days versus eight hours annually.
Why Uptime Matters More in 2025
The Cost of Downtime Has Skyrocketed
According to recent studies, the average cost of IT downtime has risen to over $5,600 per minute for enterprise organizations. For e-commerce sites during peak shopping periods, this figure can be significantly higher.
But it's not just about direct revenue loss. Downtime creates cascading effects that amplify the damage far beyond the immediate financial impact.
User Expectations Have Never Been Higher
Modern users have zero tolerance for unavailability. Studies show that 88% of online consumers are less likely to return to a site after a bad experience, and 79% of dissatisfied customers will share their negative experience with others.
In 2025, your competitors are just one click away. When your site is down, users don't wait—they leave. And they often don't come back.
Search Engines Penalize Downtime
Google and other search engines factor site reliability into their ranking algorithms. Frequent or prolonged downtime signals poor user experience, which can negatively impact your search visibility.
This creates a compound effect: downtime not only loses you current visitors but also reduces your ability to attract new ones through organic search.
Remote Work Depends on Always-On Services
The shift to remote and hybrid work has made SaaS applications and cloud services essential infrastructure. When these services go down, entire organizations stop functioning.
A collaboration tool outage doesn't just inconvenience users—it halts projects, delays deadlines, and disrupts workflows across multiple teams and time zones.
Regulatory and Contractual Obligations
Many industries now have regulations requiring specific uptime levels for customer-facing services. Financial services, healthcare, and government contractors often face strict availability requirements with significant penalties for non-compliance.
Beyond regulations, most B2B contracts include Service Level Agreements (SLAs) with uptime guarantees. Missing these targets can trigger refunds, penalties, or contract termination.
The Hidden Costs of Downtime
Revenue Loss
The most obvious cost, but often underestimated. An e-commerce site generating $100,000 daily loses over $4,100 for every hour of downtime. During peak periods like Black Friday, this figure can multiply several times.
Productivity Loss
When internal systems go down, employees can't work. If 100 employees earning an average of $50/hour lose access to critical systems, that's $5,000 per hour in lost productivity—before counting the impact on deadlines and deliverables.
Recovery Costs
Getting systems back online isn't free. Emergency IT support, overtime pay, expedited vendor support, and potential hardware replacement all add to the bill. The longer the outage, the higher these costs climb.
Reputation Damage
Perhaps the most significant long-term cost. Customers remember downtime, especially if it affected them during a critical moment. Rebuilding trust takes time and resources, and some customers never return.
Social media amplifies this effect. A single significant outage can generate negative coverage that persists in search results for months or years.
Opportunity Cost
While your site is down, competitors capture your would-be customers. Some of those customers will discover they prefer the alternative and never return, even after you're back online.
What Causes Downtime?
Hardware Failures
Physical components fail. Servers, storage devices, network equipment, and power systems all have finite lifespans. Without redundancy, a single hardware failure can take down entire services.
Software Bugs
Code issues, memory leaks, and unhandled exceptions can crash applications or make them unresponsive. These problems often emerge only under specific conditions or load levels.
Human Error
Misconfigurations, accidental deletions, and deployment mistakes remain leading causes of outages. Even experienced teams make errors, especially under pressure.
Security Incidents
DDoS attacks, ransomware, and other security breaches can render services unavailable. These incidents are often deliberately timed to maximize damage.
Third-Party Dependencies
Modern applications depend on numerous external services: payment processors, APIs, CDNs, DNS providers, and cloud platforms. When any of these fail, your service may fail with them.
Capacity Issues
Traffic spikes can overwhelm systems that aren't designed to scale. Viral content, marketing campaigns, or seasonal peaks can generate load that exceeds capacity.
How Uptime is Measured
Measuring uptime seems straightforward but requires careful consideration of methodology.
Monitoring Frequency
How often do you check? Checking every 5 minutes means you might not detect an outage for up to 5 minutes. Checking every minute provides faster detection but generates more data.
Geographic Distribution
A site might be available in one region but unreachable in another due to network issues, CDN problems, or regional infrastructure failures. Accurate measurement requires checking from multiple locations.
Definition of "Up"
Is the site "up" if it returns a 200 status code but takes 30 seconds to load? What if it returns an error page? Defining uptime requires specifying what constitutes acceptable performance.
Maintenance Windows
Planned maintenance typically doesn't count against uptime metrics, but this requires clear communication and accurate tracking of maintenance periods.
Best Practices for Maximizing Uptime
Implement Comprehensive Monitoring
You can't improve what you don't measure. Deploy monitoring that checks your critical systems frequently from multiple geographic locations.
Modern monitoring should include not just availability checks but also performance metrics, SSL certificate expiration tracking, and DNS verification.
Build Redundancy
Eliminate single points of failure. Use multiple servers, multiple data centers, multiple DNS providers, and multiple network paths. Design systems so that any single component can fail without taking down the service.
Automate Responses
Don't wait for humans to respond to alerts at 3 AM. Implement automatic failover, auto-scaling, and self-healing systems that can respond to issues faster than any human.
Test Your Recovery
Regular disaster recovery testing ensures your failover systems actually work when needed. Many organizations discover their backup systems don't function correctly only when they need them most.
Establish Clear Processes
Document incident response procedures. When downtime occurs, every second counts. Clear processes reduce confusion and speed recovery.
Taking Action: Your First Step
Understanding uptime is the first step. The second step is measuring it.
If you're not currently monitoring your website's availability, you're flying blind. Issues can persist for hours before anyone notices—usually when a customer complains.
UptimeBolt makes getting started simple. Create your first monitor in 30 seconds and start receiving alerts when issues occur. With AI-powered predictions, you'll often know about problems before they affect your users.
Conclusion
Uptime isn't just a technical metric—it's a business imperative. In 2025, where digital presence equals business presence, availability directly impacts revenue, reputation, and growth.
The organizations that thrive will be those that treat uptime as a strategic priority, not an afterthought. They'll invest in monitoring, redundancy, and rapid response capabilities.
Don't wait for downtime to teach you its importance. Start monitoring today, establish your baseline, and begin the journey toward higher availability.
Your customers expect you to be there when they need you. Make sure you are.