En los últimos años, los conceptos de observabilidad y monitoreo se han vuelto omnipresentes en conversaciones de DevOps, SRE y arquitectura de sistemas. Sin embargo, a pesar de su popularidad, siguen siendo dos de los términos más confundidos dentro de la operación de plataformas digitales modernas.
En el contexto de Latinoamérica, donde la adopción y los desafíos de escalabilidad son únicos, esta confusión es aún más pronunciada. En muchas organizaciones se habla de “implementar observabilidad” cuando en realidad se están desplegando dashboards de métricas o alertas básicas. En otros casos, se asume que una plataforma de monitoreo tradicional puede reemplazar completamente a una solución de observabilidad.
Ambas interpretaciones son incompletas y, en algunos escenarios, peligrosas.
Este artículo busca aclarar de forma técnica y práctica las diferencias reales entre observabilidad y monitoreo, qué preguntas responde cada enfoque, por qué no son excluyentes y cómo la inteligencia artificial está dando lugar a una nueva evolución: la observabilidad proactiva.
El debate entre observabilidad y monitoreo suele partir de una pregunta aparentemente simple: ¿no son básicamente lo mismo?
La respuesta corta es no.
La respuesta correcta es más incómoda: son conceptos relacionados, pero diseñados para resolver problemas distintos, en momentos distintos del ciclo de vida de un sistema.
El monitoreo nació primero, en una época donde los sistemas eran monolíticos, estables y relativamente predecibles. La observabilidad surge más tarde, como respuesta a la complejidad introducida por microservicios, arquitecturas event-driven, cloud-native y despliegues continuos.
Piensa en el monitoreo como la alarma de un coche (detecta un estado binario: activo o robado).
La observabilidad es el GPS, el historial de viaje, el diagnóstico de motor y la correlación de datos del vehículo.
Confundirlos suele llevar a dos errores comunes:
- Esperar que el monitoreo explique causas profundas.
- Esperar que la observabilidad reemplace la detección temprana de fallos.
Ambos enfoques son necesarios, pero cumplen roles distintos.

El monitoreo es el proceso de medir, visualizar y alertar sobre el estado de un sistema a partir de métricas y condiciones predefinidas. Su objetivo principal es responder a la pregunta:
“¿Está funcionando el sistema como debería en este momento?”
El monitoreo se basa en señales conocidas y esperadas. Define umbrales, condiciones y estados aceptables. Cuando algo se sale de esos límites, se genera una alerta.
Algunos ejemplos típicos de monitoreo incluyen:
- CPU por encima del 80% durante más de 5 minutos
- Tasa de errores HTTP 5xx mayor al 2%
- Latencia promedio superior a 500 ms
- Un endpoint que deja de responder
- Un job que no ejecuta dentro del intervalo esperado
El monitoreo es excelente para:
- Detectar fallos conocidos
- Confirmar disponibilidad
- Cumplir SLAs
- Automatizar respuestas simples
- Dar visibilidad operativa inmediata
Ejemplo: una alerta de PagerDuty o Slack se dispara en 30 segundos si el health check de Kubernetes falla.
Sin monitoreo, los equipos operan a ciegas. Pero el monitoreo tiene límites claros.
El mayor límite es que solo puede alertar sobre aquello que fue definido previamente. No explica por qué ocurre un problema, ni detecta fácilmente comportamientos nuevos o degradaciones lentas que no cruzan umbrales fijos.
La observabilidad es un concepto tomado de la teoría de control y aplicado a sistemas de software. Un sistema es observable cuando, a partir de sus señales internas, es posible entender qué está pasando dentro de él, incluso ante comportamientos no esperados.
La observabilidad responde a una pregunta distinta:
“¿Por qué el sistema se está comportando de esta manera?”
A diferencia del monitoreo, la observabilidad no se basa únicamente en umbrales ni en escenarios predefinidos. Se enfoca en explorar, correlacionar y entender estados internos complejos, especialmente cuando algo sale mal y no está claro qué cambió.
La observabilidad es especialmente crítica cuando:
- Existen cientos de microservicios
- Hay múltiples dependencias externas
- Los despliegues son frecuentes
- Los fallos no son determinísticos
- Los síntomas aparecen lejos de la causa real
Aquí no basta con saber que “la latencia subió”. Es necesario entender:
- En qué servicio ocurrió
- En qué versión
- En qué región
- En qué tipo de request
- Qué dependencia se degradó primero
Eso es observabilidad.
La observabilidad se construye sobre tres tipos principales de señales, conocidas como los tres pilares:
Datos numéricos agregados a lo largo del tiempo. Ejemplos:
- Latencia
- Throughput
- Tasa de errores
- Uso de CPU/memoria
- Éxito de flujos críticos
Permiten detectar tendencias, comparar periodos y activar alertas.
Registros detallados de eventos discretos. Incluyen:
- Mensajes de error
- Advertencias
- Cambios de estado
- Información contextual
Son fundamentales para entender qué ocurrió exactamente dentro de un componente.
Permiten seguir una solicitud completa a través de múltiples servicios.
Un trace muestra cómo una request atraviesa gateways, APIs, colas, bases de datos y servicios externos, incluyendo tiempos y errores en cada paso.
Un pico de latencia cobra sentido cuando se conecta con:
- Un trace específico
- Logs que muestran una dependencia degradada
- Métricas que revelan saturación en un componente
Ejemplo concreto:
La traza del microservicio A revela una llamada lenta al servicio de pagos B, y el log del servicio B muestra un timeout al cluster de base de datos C.
La observabilidad no consiste solo en recolectar estos datos, sino en correlacionarlos eficientemente.
Observabilidad y monitoreo no compiten. Se complementan.
- El monitoreo responde rápido.
- La observabilidad explica en profundidad.
Ejemplo típico:
- El monitoreo detecta que el checkout está fallando.
- La observabilidad permite entender que el problema ocurre solo en una región, en una versión específica del servicio de pagos, bajo cierto tipo de transacción.
Sin monitoreo, el problema se detecta tarde.
Sin observabilidad, el problema se investiga a ciegas.
Las organizaciones maduras utilizan:
- Monitoreo para detección temprana, alertas y cumplimiento de SLOs.
- Observabilidad para análisis profundo, debugging y mejora continua.
Pensar que uno reemplaza al otro suele terminar en más ruido, más incidentes y mayor MTTR.
La complejidad actual supera la capacidad humana para analizar manualmente métricas, logs y traces en tiempo real. Aquí entra la inteligencia artificial.
- Umbrales dinámicos basados en comportamiento real
- Detección de anomalías tempranas
- Reducción de falsos positivos
- Priorización de alertas según impacto
- Correlación automática de señales
- Identificación de patrones invisibles
- Sugerencias de causa raíz
- Análisis histórico predictivo
Cuando ambas se combinan, surge un nuevo enfoque:
Este modelo no espera a que el sistema falle ni a que un humano investigue. Detecta desviaciones, entiende contexto y alerta cuando aún hay margen de acción.
Es importante ser claros: UptimeBolt no pretende reemplazar plataformas de observabilidad profundas como Datadog o New Relic. Tampoco compite en recolección masiva de logs o trazas de bajo nivel.
UptimeBolt se posiciona como el puente inteligente entre monitoreo y observabilidad, enfocado en prevención, predicción y acción temprana gracias a la IA.
Aporta valor en:
- Monitoreo avanzado de flujos críticos (synthetic y E2E)
- Detección de anomalías basada en IA
- Análisis de comportamiento histórico
- Predicción de incidentes antes de que impacten SLOs
- Correlación de señales clave sin sobrecargar al equipo
En entornos donde ya existen herramientas de observabilidad, UptimeBolt actúa como capa de inteligencia que:
- Reduce el ruido de alertas agrupando múltiples señales en un incidente priorizado
- Prioriza riesgos reales
- Anticipa degradaciones
- Mejora MTTR (Mean Time To Resolution) y MTTD (Mean Time To Detect)
No reemplaza la observabilidad profunda.
La hace más accionable.
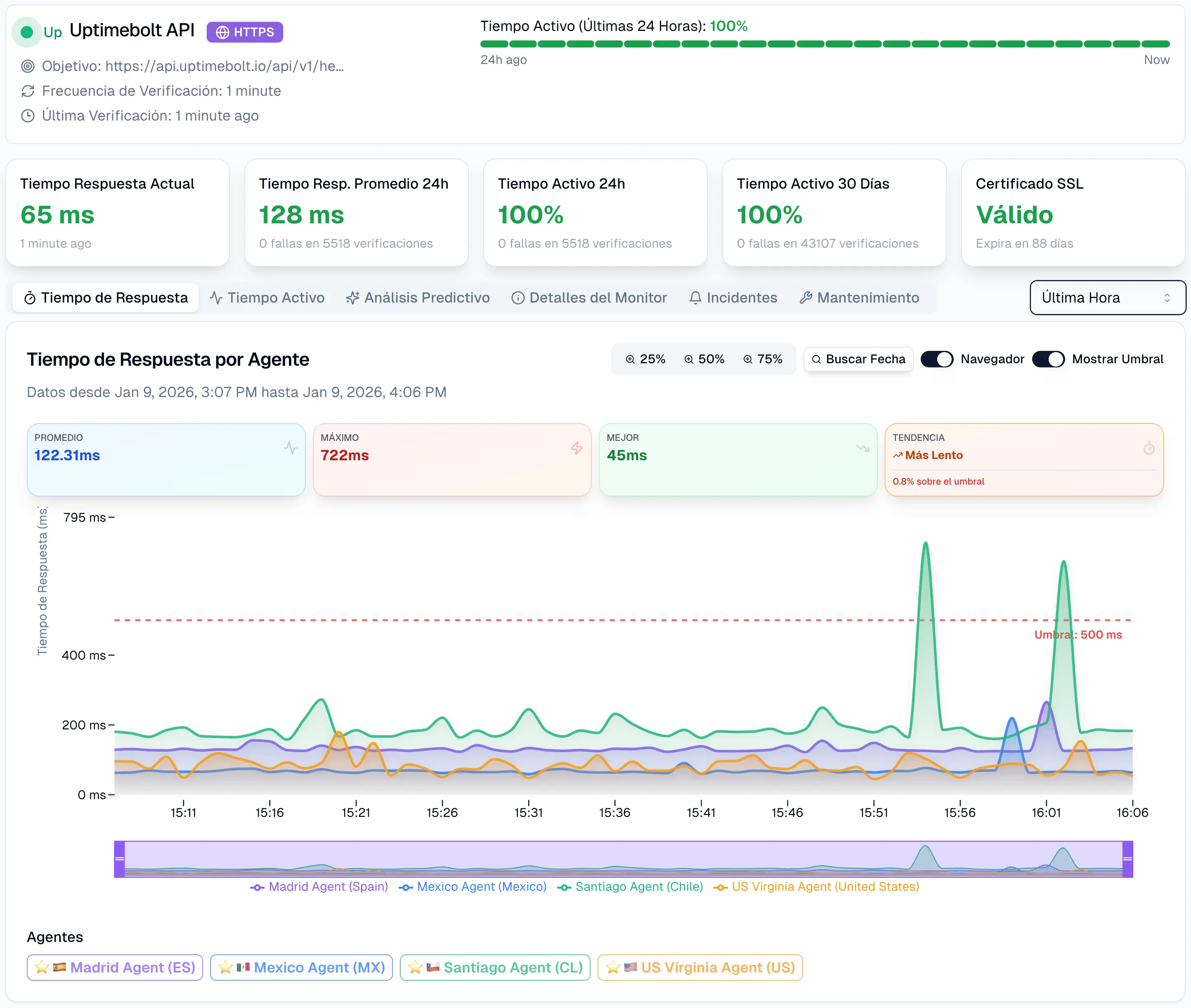
En sistemas digitales modernos, la fiabilidad ya no depende solo de saber si algo está arriba o abajo. Depende de entender por qué se comporta como lo hace y de anticiparse antes de que falle.
- El monitoreo detecta.
- La observabilidad explica.
- La inteligencia artificial permite predecir.
Las organizaciones que integran estos tres elementos no solo reducen downtime, sino que operan con mayor confianza, menor estrés y mejor alineación entre tecnología y negocio.
En plataformas LATAM que escalan rápidamente, la verdadera ventaja competitiva no es reaccionar más rápido, sino prevenir de forma inteligente.
Ahí es donde la observabilidad proactiva deja de ser una aspiración teórica y se convierte en una práctica real.
Si quieres optimizar el monitoreo en tu operación, ¡te invitamos a comenzar con UptimeBolt a través de una prueba gratuita!
En los últimos años, los conceptos de observabilidad y monitoreo se han vuelto omnipresentes en conversaciones de DevOps, SRE y arquitectura de sistemas. Sin embargo, a pesar de su popularidad, siguen siendo dos de los términos más confundidos dentro de la operación de plataformas digitales modernas.
En el contexto de Latinoamérica, donde la adopción y los desafíos de escalabilidad son únicos, esta confusión es aún más pronunciada. En muchas organizaciones se habla de “implementar observabilidad” cuando en realidad se están desplegando dashboards de métricas o alertas básicas. En otros casos, se asume que una plataforma de monitoreo tradicional puede reemplazar completamente a una solución de observabilidad.
Ambas interpretaciones son incompletas y, en algunos escenarios, peligrosas.
Este artículo busca aclarar de forma técnica y práctica las diferencias reales entre observabilidad y monitoreo, qué preguntas responde cada enfoque, por qué no son excluyentes y cómo la inteligencia artificial está dando lugar a una nueva evolución: la observabilidad proactiva.
El debate eterno entre observabilidad y monitoreo
El debate entre observabilidad y monitoreo suele partir de una pregunta aparentemente simple: ¿no son básicamente lo mismo?
La respuesta corta es no.
La respuesta correcta es más incómoda: son conceptos relacionados, pero diseñados para resolver problemas distintos, en momentos distintos del ciclo de vida de un sistema.
El monitoreo nació primero, en una época donde los sistemas eran monolíticos, estables y relativamente predecibles. La observabilidad surge más tarde, como respuesta a la complejidad introducida por microservicios, arquitecturas event-driven, cloud-native y despliegues continuos.
Piensa en el monitoreo como la alarma de un coche (detecta un estado binario: activo o robado).
La observabilidad es el GPS, el historial de viaje, el diagnóstico de motor y la correlación de datos del vehículo.
Confundirlos suele llevar a dos errores comunes:
Ambos enfoques son necesarios, pero cumplen roles distintos.
¿Qué es el monitoreo y qué preguntas responde?
El monitoreo es el proceso de medir, visualizar y alertar sobre el estado de un sistema a partir de métricas y condiciones predefinidas. Su objetivo principal es responder a la pregunta:
“¿Está funcionando el sistema como debería en este momento?”
El monitoreo se basa en señales conocidas y esperadas. Define umbrales, condiciones y estados aceptables. Cuando algo se sale de esos límites, se genera una alerta.
Algunos ejemplos típicos de monitoreo incluyen:
El monitoreo es excelente para:
Ejemplo: una alerta de PagerDuty o Slack se dispara en 30 segundos si el health check de Kubernetes falla.
Sin monitoreo, los equipos operan a ciegas. Pero el monitoreo tiene límites claros.
El mayor límite es que solo puede alertar sobre aquello que fue definido previamente. No explica por qué ocurre un problema, ni detecta fácilmente comportamientos nuevos o degradaciones lentas que no cruzan umbrales fijos.
¿Qué es observabilidad y qué respuestas ofrece?
La observabilidad es un concepto tomado de la teoría de control y aplicado a sistemas de software. Un sistema es observable cuando, a partir de sus señales internas, es posible entender qué está pasando dentro de él, incluso ante comportamientos no esperados.
La observabilidad responde a una pregunta distinta:
“¿Por qué el sistema se está comportando de esta manera?”
A diferencia del monitoreo, la observabilidad no se basa únicamente en umbrales ni en escenarios predefinidos. Se enfoca en explorar, correlacionar y entender estados internos complejos, especialmente cuando algo sale mal y no está claro qué cambió.
La observabilidad es especialmente crítica cuando:
Aquí no basta con saber que “la latencia subió”. Es necesario entender:
Eso es observabilidad.
Métricas, logs y traces: los pilares de la observabilidad
La observabilidad se construye sobre tres tipos principales de señales, conocidas como los tres pilares:
Métricas
Datos numéricos agregados a lo largo del tiempo. Ejemplos:
Permiten detectar tendencias, comparar periodos y activar alertas.
Logs
Registros detallados de eventos discretos. Incluyen:
Son fundamentales para entender qué ocurrió exactamente dentro de un componente.
Traces (trazas distribuidas)
Permiten seguir una solicitud completa a través de múltiples servicios.
Un trace muestra cómo una request atraviesa gateways, APIs, colas, bases de datos y servicios externos, incluyendo tiempos y errores en cada paso.
Un pico de latencia cobra sentido cuando se conecta con:
Ejemplo concreto:
La traza del microservicio A revela una llamada lenta al servicio de pagos B, y el log del servicio B muestra un timeout al cluster de base de datos C.
La observabilidad no consiste solo en recolectar estos datos, sino en correlacionarlos eficientemente.
Por qué las empresas necesitan ambos enfoques
Observabilidad y monitoreo no compiten. Se complementan.
Ejemplo típico:
Sin monitoreo, el problema se detecta tarde.
Sin observabilidad, el problema se investiga a ciegas.
Las organizaciones maduras utilizan:
Pensar que uno reemplaza al otro suele terminar en más ruido, más incidentes y mayor MTTR.
El rol de la inteligencia artificial para conectar observabilidad y monitoreo predictivo
La complejidad actual supera la capacidad humana para analizar manualmente métricas, logs y traces en tiempo real. Aquí entra la inteligencia artificial.
IA aplicada al monitoreo
IA aplicada a la observabilidad
Cuando ambas se combinan, surge un nuevo enfoque:
Observabilidad proactiva
Este modelo no espera a que el sistema falle ni a que un humano investigue. Detecta desviaciones, entiende contexto y alerta cuando aún hay margen de acción.
Cómo UptimeBolt complementa observabilidad con prevención
Es importante ser claros: UptimeBolt no pretende reemplazar plataformas de observabilidad profundas como Datadog o New Relic. Tampoco compite en recolección masiva de logs o trazas de bajo nivel.
UptimeBolt se posiciona como el puente inteligente entre monitoreo y observabilidad, enfocado en prevención, predicción y acción temprana gracias a la IA.
Aporta valor en:
En entornos donde ya existen herramientas de observabilidad, UptimeBolt actúa como capa de inteligencia que:
No reemplaza la observabilidad profunda.
La hace más accionable.
Conclusión: observar, entender y predecir son la nueva tríada de fiabilidad
En sistemas digitales modernos, la fiabilidad ya no depende solo de saber si algo está arriba o abajo. Depende de entender por qué se comporta como lo hace y de anticiparse antes de que falle.
Las organizaciones que integran estos tres elementos no solo reducen downtime, sino que operan con mayor confianza, menor estrés y mejor alineación entre tecnología y negocio.
En plataformas LATAM que escalan rápidamente, la verdadera ventaja competitiva no es reaccionar más rápido, sino prevenir de forma inteligente.
Ahí es donde la observabilidad proactiva deja de ser una aspiración teórica y se convierte en una práctica real.
Si quieres optimizar el monitoreo en tu operación, ¡te invitamos a comenzar con UptimeBolt a través de una prueba gratuita!