APIs have become the backbone of modern applications. From e-commerce platforms and fintech systems to SaaS solutions and microservices-based architectures, virtually every digital experience depends on multiple APIs working correctly, quickly, and consistently. However, many organizations still measure their “uptime” solely based on server availability or the frontend layer, without real visibility into what is happening within the APIs that sustain critical business flows.
The problem is clear: an application can be “online” and still fail for end users if an API responds slowly, returns intermittent errors, or degrades under load. In these cases, downtime is not always absolute; it often appears as silent degradation, failed transactions, partial errors, or inconsistent experiences that directly impact revenue, trust, and reputation.
This is where API monitoring plays a critical role. It’s not just about knowing whether an endpoint responds, but about understanding how it behaves, how fast it responds, the quality of the data it returns, and how its performance evolves over time. API monitoring enables a shift from a reactive view of uptime to a proactive and predictive management of digital reliability.
API monitoring is the process of continuously observing, measuring, and validating the behavior of the application programming interfaces that connect services, systems, and applications. Unlike traditional infrastructure monitoring, which focuses on servers, CPU, or memory, API monitoring is centered on the logical layer where business transactions actually occur.
In practical terms, an API monitor executes scheduled requests to specific endpoints and analyzes the responses. These requests can simulate real calls from clients, mobile applications, external systems, or internal microservices. The monitor validates not only that the API responds, but that it responds correctly according to defined parameters: response time, status codes, payload structure, expected values, and behavior under different scenarios.
In this sense, infrastructure monitoring is like seeing that the engine is running, while API monitoring is seeing whether the car is actually moving forward and taking the correct route.
Typical operation includes the periodic execution of requests from different geographic locations, the measurement of key metrics, comparison against thresholds, and the generation of alerts when anomalies are detected. Over time, this information becomes historical time series that make it possible to identify trends, progressive degradations, and patterns that anticipate incidents.
A key point is that API monitoring does not replace development testing or internal observability; it complements them from an external, real-uptime-focused perspective. While tests validate functionality before deployment, monitoring ensures that this functionality remains stable in production.
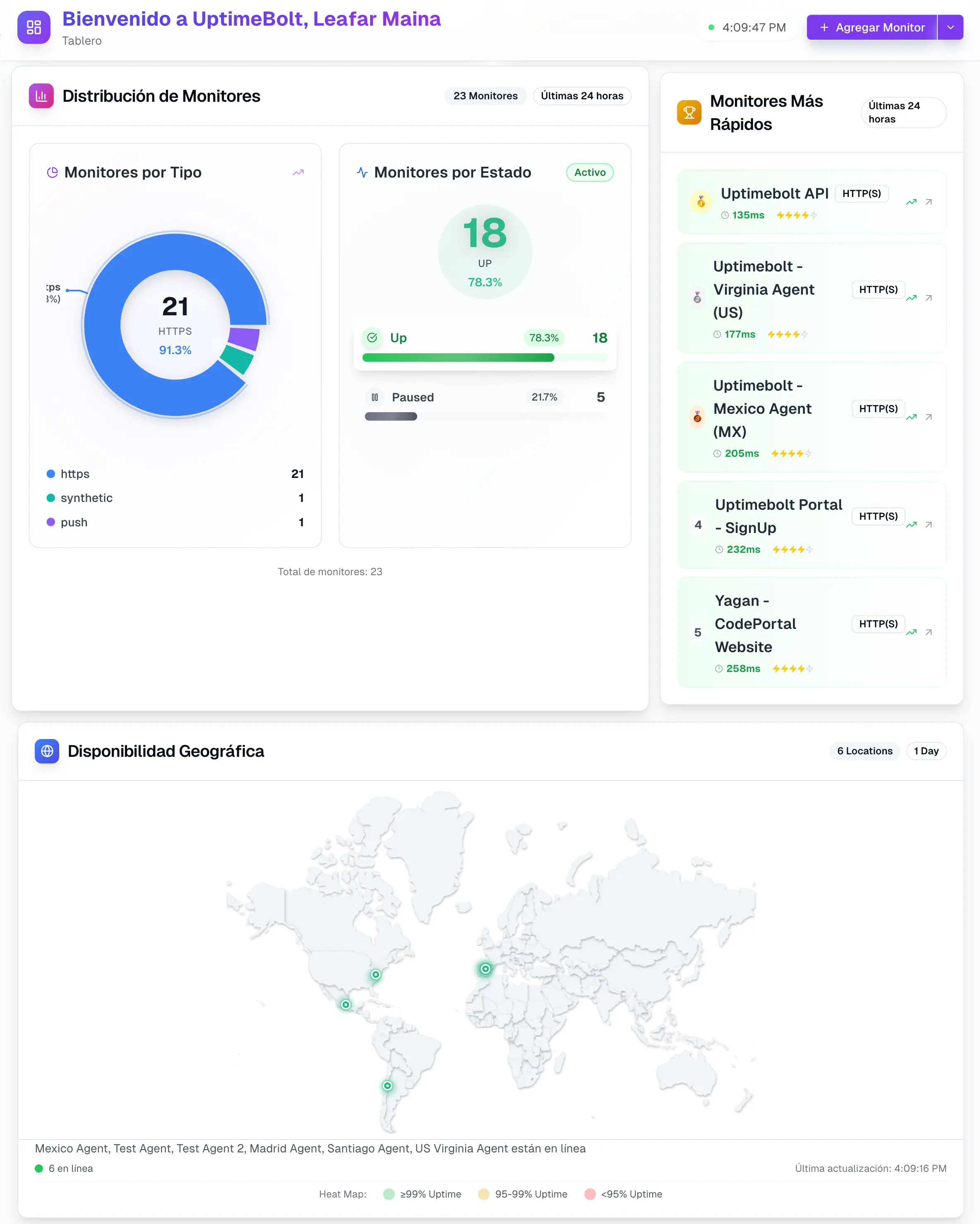
For API monitoring to be truly effective, it is not enough to check basic availability. There are critical metrics that must be analyzed together to obtain a complete view of an API’s health.
Latency is one of the most important metrics. It measures how long an API takes to respond from the moment it receives a request until it delivers a complete response. Gradual increases in latency are often the first sign of saturation, database issues, slow dependencies, or internal bottlenecks. Even when an API does not “go down,” high latency can break the end-user experience.
Error codes provide direct insight into the logical state of an API.
4xx errors may indicate validation issues, incompatible changes, or misconfigured clients, while 5xx errors usually reveal internal service failures. Monitoring should identify not only the presence of errors, but also their frequency, distribution, and evolution over time.
Timeouts are especially dangerous because they are often not recorded as explicit errors. An API that fails to respond within an acceptable time can block entire workflows, trigger cascading retries, and amplify the impact on other services. Detecting timeouts early is key to avoiding systemic failures.
Also known as response content, the payload is another critical dimension. An API can return a 200 status code but still deliver incomplete, malformed, or inconsistent data. Advanced monitoring validates schemas, required fields, expected values, and basic business rules, ensuring that the response not only exists, but is correct and useful.
Not all APIs are the same, and each type presents specific monitoring challenges. Understanding these differences is essential to designing an effective strategy.
REST APIs are the most common and generally operate over HTTP with standard methods such as GET, POST, PUT, and DELETE. Their monitoring typically focuses on individual endpoints, authentication, status codes, and JSON payloads. Although they appear simple, their dependence on multiple internal services can hide complex failures.
GraphQL APIs introduce a different approach, where a single query can resolve multiple resources. This makes latency and payload even more critical, since a poorly optimized query can generate slow or excessively large responses. Monitoring must consider representative queries and validate both structure and performance.
SOAP APIs, still present in enterprise and financial environments, require validation of XML messages, strict schemas, and well-defined contracts. Small changes or incompatibilities can generate errors that are difficult to diagnose without specialized monitoring.
Webhooks represent a special case, as communication is reversed: the external API sends events to your system. Here, monitoring must validate reception, processing times, and failure handling, ensuring that events are neither lost nor processed with delays.
Each of these types requires specific configurations, metrics, and validations. A generic “ping” approach is insufficient to guarantee real uptime in modern architectures.
API monitoring makes it possible to detect a wide range of issues that often go unnoticed with traditional approaches.
One of the most frequent is progressive performance degradation. Before a total outage, many APIs begin responding more and more slowly, gradually impacting users.
Another common issue is intermittent errors. An API may fail only under certain conditions, traffic volumes, or external dependencies. These failures are difficult to reproduce manually, but continuous monitoring exposes them quickly.
Undocumented changes or faulty deployments are also reflected in monitoring. Payload modifications, removed fields, or changes in business logic can break integrations without causing an obvious outage. Automatic content validation allows these issues to be detected immediately.
External dependencies are another frequent source of incidents. Many APIs rely on third parties for payments, authentication, logistics, or data. When one of these services degrades, the impact propagates. Monitoring helps identify whether the problem is internal or external and enables a more precise response.
From an operational perspective, API monitoring significantly reduces downtime and incident resolution time. By detecting issues before they escalate, teams can act proactively rather than reactively.
Continuous visibility provides greater control over complex systems. DevOps and SRE teams stop relying exclusively on late alerts or user complaints and instead manage reliability using objective, real-time data.
For end users, this translates into more consistent and reliable experiences: fewer payment errors, fewer login failures, fewer incomplete operations. In competitive environments, this stability becomes a clear advantage over less reliable alternatives.
In e-commerce, every degraded or failed API can mean abandoned carts and direct revenue loss. API monitoring helps ensure critical flows such as search, checkout, payments, and confirmations, even during traffic peaks.
In fintech, where reliability and accuracy are essential, monitoring reduces operational and regulatory risks. Detecting errors in transactions, validations, or banking integrations before they affect customers is crucial to maintaining trust.
In SaaS models, perceived availability is a core part of the value proposition. Customers expect services to be always available and fast. API monitoring enables SLA compliance, supports uptime metrics, and differentiates products through operational quality.
UptimeBolt approaches API monitoring from a deep and predictive perspective. It does not simply check whether an endpoint responds; it performs full validations of behavior, performance, and content, simulating real usage scenarios.
The platform allows teams to define advanced monitors for different types of APIs, configure dynamic thresholds, and analyze historical trends. Through continuous analysis of latency, errors, and response patterns, UptimeBolt identifies early signals of degradation before they become visible incidents.
In addition, distributed monitoring from multiple locations helps detect regional issues, external dependencies, and network failures. Intelligent alerts reduce noise and prioritize events with real business impact, enabling faster and more effective responses.
In modern architectures, real uptime is not defined by servers being up or dashboards being green, but by APIs functioning correctly for users. Without API monitoring, organizations operate blindly, reacting too late and taking unnecessary risks.
API monitoring is an essential practice to ensure reliability, performance, and business continuity. It enables the detection of silent degradations, prevents incidents, and delivers consistent digital experiences. In an environment where every interaction depends on multiple connected services, an API without monitoring simply cannot guarantee real uptime.
APIs have become the backbone of modern applications. From e-commerce platforms and fintech systems to SaaS solutions and microservices-based architectures, virtually every digital experience depends on multiple APIs working correctly, quickly, and consistently. However, many organizations still measure their “uptime” solely based on server availability or the frontend layer, without real visibility into what is happening within the APIs that sustain critical business flows.
The problem is clear: an application can be “online” and still fail for end users if an API responds slowly, returns intermittent errors, or degrades under load. In these cases, downtime is not always absolute; it often appears as silent degradation, failed transactions, partial errors, or inconsistent experiences that directly impact revenue, trust, and reputation.
This is where API monitoring plays a critical role. It’s not just about knowing whether an endpoint responds, but about understanding how it behaves, how fast it responds, the quality of the data it returns, and how its performance evolves over time. API monitoring enables a shift from a reactive view of uptime to a proactive and predictive management of digital reliability.
What API monitoring is and how it works
API monitoring is the process of continuously observing, measuring, and validating the behavior of the application programming interfaces that connect services, systems, and applications. Unlike traditional infrastructure monitoring, which focuses on servers, CPU, or memory, API monitoring is centered on the logical layer where business transactions actually occur.
In practical terms, an API monitor executes scheduled requests to specific endpoints and analyzes the responses. These requests can simulate real calls from clients, mobile applications, external systems, or internal microservices. The monitor validates not only that the API responds, but that it responds correctly according to defined parameters: response time, status codes, payload structure, expected values, and behavior under different scenarios.
In this sense, infrastructure monitoring is like seeing that the engine is running, while API monitoring is seeing whether the car is actually moving forward and taking the correct route.
Typical operation includes the periodic execution of requests from different geographic locations, the measurement of key metrics, comparison against thresholds, and the generation of alerts when anomalies are detected. Over time, this information becomes historical time series that make it possible to identify trends, progressive degradations, and patterns that anticipate incidents.
A key point is that API monitoring does not replace development testing or internal observability; it complements them from an external, real-uptime-focused perspective. While tests validate functionality before deployment, monitoring ensures that this functionality remains stable in production.
Key metrics to monitor: latency, error codes, timeouts, payload
For API monitoring to be truly effective, it is not enough to check basic availability. There are critical metrics that must be analyzed together to obtain a complete view of an API’s health.
Latency
Latency is one of the most important metrics. It measures how long an API takes to respond from the moment it receives a request until it delivers a complete response. Gradual increases in latency are often the first sign of saturation, database issues, slow dependencies, or internal bottlenecks. Even when an API does not “go down,” high latency can break the end-user experience.
Error codes
Error codes provide direct insight into the logical state of an API.
4xx errors may indicate validation issues, incompatible changes, or misconfigured clients, while 5xx errors usually reveal internal service failures. Monitoring should identify not only the presence of errors, but also their frequency, distribution, and evolution over time.
Timeouts
Timeouts are especially dangerous because they are often not recorded as explicit errors. An API that fails to respond within an acceptable time can block entire workflows, trigger cascading retries, and amplify the impact on other services. Detecting timeouts early is key to avoiding systemic failures.
Payload
Also known as response content, the payload is another critical dimension. An API can return a 200 status code but still deliver incomplete, malformed, or inconsistent data. Advanced monitoring validates schemas, required fields, expected values, and basic business rules, ensuring that the response not only exists, but is correct and useful.
Types of APIs and why their monitoring is different
Not all APIs are the same, and each type presents specific monitoring challenges. Understanding these differences is essential to designing an effective strategy.
REST APIs are the most common and generally operate over HTTP with standard methods such as GET, POST, PUT, and DELETE. Their monitoring typically focuses on individual endpoints, authentication, status codes, and JSON payloads. Although they appear simple, their dependence on multiple internal services can hide complex failures.
GraphQL APIs introduce a different approach, where a single query can resolve multiple resources. This makes latency and payload even more critical, since a poorly optimized query can generate slow or excessively large responses. Monitoring must consider representative queries and validate both structure and performance.
SOAP APIs, still present in enterprise and financial environments, require validation of XML messages, strict schemas, and well-defined contracts. Small changes or incompatibilities can generate errors that are difficult to diagnose without specialized monitoring.
Webhooks represent a special case, as communication is reversed: the external API sends events to your system. Here, monitoring must validate reception, processing times, and failure handling, ensuring that events are neither lost nor processed with delays.
Each of these types requires specific configurations, metrics, and validations. A generic “ping” approach is insufficient to guarantee real uptime in modern architectures.
Common issues detected by API monitors
API monitoring makes it possible to detect a wide range of issues that often go unnoticed with traditional approaches.
One of the most frequent is progressive performance degradation. Before a total outage, many APIs begin responding more and more slowly, gradually impacting users.
Another common issue is intermittent errors. An API may fail only under certain conditions, traffic volumes, or external dependencies. These failures are difficult to reproduce manually, but continuous monitoring exposes them quickly.
Undocumented changes or faulty deployments are also reflected in monitoring. Payload modifications, removed fields, or changes in business logic can break integrations without causing an obvious outage. Automatic content validation allows these issues to be detected immediately.
External dependencies are another frequent source of incidents. Many APIs rely on third parties for payments, authentication, logistics, or data. When one of these services degrades, the impact propagates. Monitoring helps identify whether the problem is internal or external and enables a more precise response.
Operational benefits: less downtime, more control, better user experience
From an operational perspective, API monitoring significantly reduces downtime and incident resolution time. By detecting issues before they escalate, teams can act proactively rather than reactively.
Continuous visibility provides greater control over complex systems. DevOps and SRE teams stop relying exclusively on late alerts or user complaints and instead manage reliability using objective, real-time data.
For end users, this translates into more consistent and reliable experiences: fewer payment errors, fewer login failures, fewer incomplete operations. In competitive environments, this stability becomes a clear advantage over less reliable alternatives.
Strategic benefits for e-commerce, fintech, and SaaS
In e-commerce, every degraded or failed API can mean abandoned carts and direct revenue loss. API monitoring helps ensure critical flows such as search, checkout, payments, and confirmations, even during traffic peaks.
In fintech, where reliability and accuracy are essential, monitoring reduces operational and regulatory risks. Detecting errors in transactions, validations, or banking integrations before they affect customers is crucial to maintaining trust.
In SaaS models, perceived availability is a core part of the value proposition. Customers expect services to be always available and fast. API monitoring enables SLA compliance, supports uptime metrics, and differentiates products through operational quality.
How UptimeBolt performs predictive API monitoring
UptimeBolt approaches API monitoring from a deep and predictive perspective. It does not simply check whether an endpoint responds; it performs full validations of behavior, performance, and content, simulating real usage scenarios.
The platform allows teams to define advanced monitors for different types of APIs, configure dynamic thresholds, and analyze historical trends. Through continuous analysis of latency, errors, and response patterns, UptimeBolt identifies early signals of degradation before they become visible incidents.
In addition, distributed monitoring from multiple locations helps detect regional issues, external dependencies, and network failures. Intelligent alerts reduce noise and prioritize events with real business impact, enabling faster and more effective responses.
Conclusion: an API without monitoring cannot guarantee real uptime
In modern architectures, real uptime is not defined by servers being up or dashboards being green, but by APIs functioning correctly for users. Without API monitoring, organizations operate blindly, reacting too late and taking unnecessary risks.
API monitoring is an essential practice to ensure reliability, performance, and business continuity. It enables the detection of silent degradations, prevents incidents, and delivers consistent digital experiences. In an environment where every interaction depends on multiple connected services, an API without monitoring simply cannot guarantee real uptime.