When a company prepares for Black Friday, Hot Sale, Buen Fin, a major product launch, or a high-impact marketing campaign, the first thing they usually think about is capacity: more instances, more bandwidth, more auto-scaling, more CDN. All of that matters—but it’s not enough. In practice, many high-traffic incidents don’t happen because of a lack of infrastructure in absolute terms, but because there was a weak point no one detected in time. This is where incident prediction—increasingly powered by artificial intelligence—starts to make a real difference.
That’s the core mistake in approach. In high-traffic scenarios, it’s not enough to handle load. You need to anticipate failures before they happen. A few minutes of degradation in checkout, a payment API starting to respond with higher latency, or a database slowly approaching saturation can translate into direct revenue loss, support tickets, user abandonment, and reputational damage.
In these situations, the difference between a reactive team and a truly prepared one isn’t who responds faster when everything breaks. It’s who detects the early signals of failure. That’s the domain of incident prediction.
The modern conversation around high-traffic systems is no longer just about “how much traffic can my platform handle,” but about a more strategic question:
Can I detect saturation, degradation, and bottlenecks before the end user feels the impact?
This is where traditional practices like capacity planning, load testing, and infrastructure tuning connect with more advanced approaches like end-to-end monitoring, anomaly detection, and AI-driven incident prediction.
High-traffic events are moments of maximum exposure for any digital platform. Not only because there are more concurrent users, but because nearly all critical components are operating near their limits at the same time: frontend, load balancers, APIs, databases, caches, queues, external services, and payment gateways.
What makes this particularly critical is that any degradation during these periods has a multiplied cost. An additional 2–3 seconds of latency might be tolerable during normal hours, but during a commercial event, that same latency can significantly reduce conversion rates in critical flows like checkout and increase cart abandonment. On mobile, the impact can be even more severe: small increases in load time can double bounce rates.
On top of that, operational pressure increases:
- More support tickets
- Higher customer support friction
- A degraded experience at the moment of highest purchase intent
Minutes of downtime during peak traffic windows don’t distribute evenly throughout the day—they hit exactly when revenue and trust are most at stake. The impact is not linear, it’s exponential.
That’s why preparing for high-traffic events is not just about “having more capacity.” It’s about understanding that these moments are also real tests of operational resilience. A system that looks robust on paper can fail if teams lack real visibility into what’s happening across each layer.
One of the most common misconceptions is believing that a well-provisioned system is automatically protected. In reality, many high-traffic incidents occur in platforms that had sufficient infrastructure capacity but failed for other reasons.
An architecture may scale horizontally at the frontend and API gateway level, but still depend on a database, cache, queue, or external dependency that doesn’t scale at the same rate. The system appears robust overall, but its weakest point defines its true limit.
Modern platforms often rely on third parties for payments, authentication, scoring, logistics, fraud detection, or messaging. You can have a perfectly prepared infrastructure and still suffer a partial outage because an external dependency starts responding slowly, returns intermittent errors, or exhausts its own resources.
Before a visible outage occurs, there is usually a prior phase where:
- Latency increases
- Timeouts rise
- Retries multiply
- Response times become inconsistent
The problem is that if you only track binary availability, this phase goes unnoticed.
In microservices architectures, a critical flow like login or checkout crosses multiple components. Each one can be “up” while the overall flow fails. Traditional service-level monitoring is not enough to capture this reality.
Reactive monitoring assumes the system will clearly signal when something goes wrong. In practice, alerts often arrive only after the impact is already visible.
Consider a realistic scenario:
- Checkout responds at 800 ms p95
- Increases to 1.2 s
- Then to 1.8 s
- Finally to 2.7 s
There’s no full outage. No massive errors. But conversion has already started to drop.
This gradual increase is already a violation of your latency SLO (e.g., p95 < 1s), long before any HTTP 5xx errors appear.
The problem with reactive monitoring is clear: it arrives too late for the business.
Incident prediction is not about “guessing the future,” but about using historical and real-time signals to identify patterns that typically precede failures.
Artificial intelligence enables detection of correlations such as:
- Login p95 increased by 18%
- Increased jitter in authentication services
- Slight rise in retry rates
- Slower E2E flow in a specific region
Each signal alone may not trigger an alert. Together, they form a clear pattern.
That’s the real operational advantage: acting before impact.
Historical data helps answer key questions:
- When do traffic peaks occur?
- Which flows degrade first?
- Which dependencies fail early?
- Where is the real risk concentrated?
This enables a shift from generic preparation to targeted, strategic readiness.
It’s not enough to validate endpoints—you need to validate real user experience.
Key flows:
- Login
- Search
- Checkout
- Payment
- Order confirmation
End-to-end monitoring ensures the entire journey works, not just isolated components.
- p95/p99 latency
- Timeouts
- Retries
- Concurrency limits
- Slow queries
- Locks
- Connection exhaustion
- Missing indexes
- Real scalability under load
- Cache usage
- Circuit breakers
- Fallback strategies
The goal: reinforce the weakest link in the critical path.
CDNs and caching reduce backend load.
Common mistakes:
- Misconfigured caching
- Low TTLs
- Critical assets not cached
Best practices:
Cache-Control: max-agestale-while-revalidate
A strong caching strategy can mean the difference between stability and collapse.
UptimeBolt combines:
- Advanced monitoring
- Anomaly detection
- AI-driven prediction
It enables teams to:
- Detect anomalies in real time
- Identify pre-failure patterns
- Visualize critical E2E flows
- Reduce MTTD and MTTR
Result: act before impact occurs.
Reactive teams respond faster.
Predictive teams prevent the problem before it happens.
Reliability doesn’t scale by simply adding infrastructure. It must be designed, tested, and anticipated.
Today, preparing for high-traffic events means combining:
- Capacity planning
- End-to-end monitoring
- Synthetic testing
- Backend optimization
- Caching strategy
- AI-driven incident prediction
In the B2B ecosystem, this is no longer optional.
It’s the only real way to protect revenue during critical traffic events.
What if you could predict failures 30 minutes before latency impacts your checkout?
When a company prepares for Black Friday, Hot Sale, Buen Fin, a major product launch, or a high-impact marketing campaign, the first thing they usually think about is capacity: more instances, more bandwidth, more auto-scaling, more CDN. All of that matters—but it’s not enough. In practice, many high-traffic incidents don’t happen because of a lack of infrastructure in absolute terms, but because there was a weak point no one detected in time. This is where incident prediction—increasingly powered by artificial intelligence—starts to make a real difference.
That’s the core mistake in approach. In high-traffic scenarios, it’s not enough to handle load. You need to anticipate failures before they happen. A few minutes of degradation in checkout, a payment API starting to respond with higher latency, or a database slowly approaching saturation can translate into direct revenue loss, support tickets, user abandonment, and reputational damage.
In these situations, the difference between a reactive team and a truly prepared one isn’t who responds faster when everything breaks. It’s who detects the early signals of failure. That’s the domain of incident prediction.
The modern conversation around high-traffic systems is no longer just about “how much traffic can my platform handle,” but about a more strategic question:
Can I detect saturation, degradation, and bottlenecks before the end user feels the impact?
This is where traditional practices like capacity planning, load testing, and infrastructure tuning connect with more advanced approaches like end-to-end monitoring, anomaly detection, and AI-driven incident prediction.
Context: traffic spikes as moments of maximum operational risk
High-traffic events are moments of maximum exposure for any digital platform. Not only because there are more concurrent users, but because nearly all critical components are operating near their limits at the same time: frontend, load balancers, APIs, databases, caches, queues, external services, and payment gateways.
What makes this particularly critical is that any degradation during these periods has a multiplied cost. An additional 2–3 seconds of latency might be tolerable during normal hours, but during a commercial event, that same latency can significantly reduce conversion rates in critical flows like checkout and increase cart abandonment. On mobile, the impact can be even more severe: small increases in load time can double bounce rates.
On top of that, operational pressure increases:
Minutes of downtime during peak traffic windows don’t distribute evenly throughout the day—they hit exactly when revenue and trust are most at stake. The impact is not linear, it’s exponential.
That’s why preparing for high-traffic events is not just about “having more capacity.” It’s about understanding that these moments are also real tests of operational resilience. A system that looks robust on paper can fail if teams lack real visibility into what’s happening across each layer.
Why failures happen even with robust infrastructure
One of the most common misconceptions is believing that a well-provisioned system is automatically protected. In reality, many high-traffic incidents occur in platforms that had sufficient infrastructure capacity but failed for other reasons.
Bottlenecks
An architecture may scale horizontally at the frontend and API gateway level, but still depend on a database, cache, queue, or external dependency that doesn’t scale at the same rate. The system appears robust overall, but its weakest point defines its true limit.
External dependencies
Modern platforms often rely on third parties for payments, authentication, scoring, logistics, fraud detection, or messaging. You can have a perfectly prepared infrastructure and still suffer a partial outage because an external dependency starts responding slowly, returns intermittent errors, or exhausts its own resources.
Progressive degradation
Before a visible outage occurs, there is usually a prior phase where:
The problem is that if you only track binary availability, this phase goes unnoticed.
Lack of visibility in distributed systems
In microservices architectures, a critical flow like login or checkout crosses multiple components. Each one can be “up” while the overall flow fails. Traditional service-level monitoring is not enough to capture this reality.
High traffic: why reactive approaches no longer work
Reactive monitoring assumes the system will clearly signal when something goes wrong. In practice, alerts often arrive only after the impact is already visible.
Consider a realistic scenario:
There’s no full outage. No massive errors. But conversion has already started to drop.
This gradual increase is already a violation of your latency SLO (e.g., p95 < 1s), long before any HTTP 5xx errors appear.
The problem with reactive monitoring is clear: it arrives too late for the business.
How incident prediction enables proactive response
Incident prediction is not about “guessing the future,” but about using historical and real-time signals to identify patterns that typically precede failures.
Artificial intelligence enables detection of correlations such as:
Each signal alone may not trigger an alert. Together, they form a clear pattern.
That’s the real operational advantage: acting before impact.
Using historical patterns to identify risk windows
Historical data helps answer key questions:
This enables a shift from generic preparation to targeted, strategic readiness.
Synthetic testing and critical flow simulation
It’s not enough to validate endpoints—you need to validate real user experience.
Key flows:
End-to-end monitoring ensures the entire journey works, not just isolated components.
Strengthening APIs, databases, and microservices
APIs
Databases
Microservices
The goal: reinforce the weakest link in the critical path.
The critical role of CDNs and caching
CDNs and caching reduce backend load.
Common mistakes:
Best practices:
Cache-Control: max-agestale-while-revalidateA strong caching strategy can mean the difference between stability and collapse.
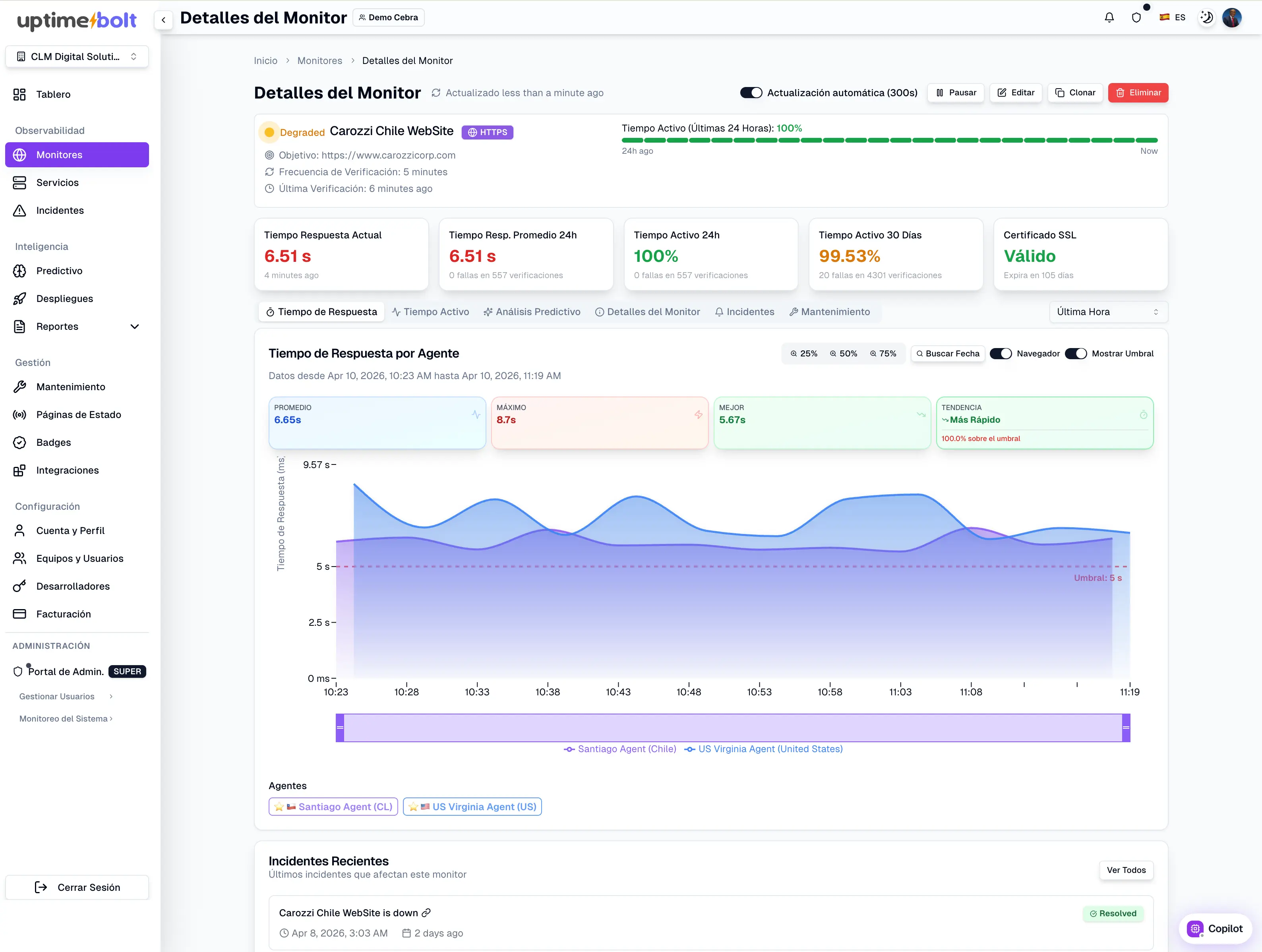
How UptimeBolt predicts incidents 30 minutes to 48 hours in advance
UptimeBolt combines:
It enables teams to:
Result: act before impact occurs.
Conclusion
Reactive teams respond faster.
Predictive teams prevent the problem before it happens.
Reliability doesn’t scale by simply adding infrastructure. It must be designed, tested, and anticipated.
Today, preparing for high-traffic events means combining:
In the B2B ecosystem, this is no longer optional.
It’s the only real way to protect revenue during critical traffic events.