In modern environments, SLAs are no longer the best starting point for understanding the true reliability of a system. While SLAs define the external promise to the customer, SLOs (Service Level Objectives) represent the internal capability to meet that promise. The problem is that, in many organizations, there is a structural gap between the two: what is promised is not aligned with what the system can realistically sustain in operation.
This disconnect is rarely due to a lack of concern for reliability, but rather to limitations in observability, metric definition, and operational maturity. Without clear visibility into latency, errors, or degradations, teams operate “blind,” unable to measure whether their SLOs are at risk until the impact is already visible to the end user.
According to recent industry reports (such as DORA reports or analyses from firms like Gartner), more than 60% of organizations consistently fail to meet their service level objectives, especially in distributed architectures. Most concerning is not just the failure itself, but the fact that in many cases it is not detected in time.
The problem is not the SLA as a concept, but how reliability is operationalized. The causes of failure are usually operational, technical, and organizational. And in most cases, they are avoidable.
The first major issue is relying on monitoring that only detects problems after they have already impacted the user.
Most traditional tools operate under a simple model:
- Define thresholds
- Wait for them to be crossed
- Trigger an alert
The problem is that by the time an alert fires, the SLA is already compromised.
Typical example:
- Latency gradually increases from 300 ms → 800 ms → 1.5 s
- The threshold is set at 1 s
- The alert arrives when the impact is already visible
This type of monitoring is useful for detecting outages, but not degradations.
Real impact:
- Teams with reactive monitoring have up to 4x higher MTTD (Mean Time to Detection)
- Detection time can increase from minutes to hours
- The SLA is broken before the team takes action
How to avoid it:
- Implement anomaly detection using Machine Learning or AI models
- Analyze trends, not just thresholds
- Detect deviations before impact
Related to the above, many organizations depend almost entirely on alerts to operate.
The problem is that not all failures generate clear alerts.
Worse, many alerts do not require action.
Studies in SRE teams show that between 30% and 40% of alerts are false positives or noise.
This leads to:
- Alert fatigue
- Team desensitization
- Slower response times
Real impact:
- Teams with high alert loads have up to 3x higher MTTR
- Critical incidents get lost among irrelevant alerts
- Poor prioritization between urgent vs important issues
Example:
- 50 simultaneous alerts
- Only 3 are critical
- The team takes 20 minutes to identify the root cause
How to avoid it:
- Prioritize alerts based on SLO impact
- Group related events
- Reduce noise with intelligent analysis
One of the most underestimated mistakes is monitoring components instead of user experiences.
Modern systems rarely fail at a single point. They fail at the interaction between multiple components.
Classic example:
- API responds correctly
- Database is working
- Infrastructure is stable
- But checkout fails
From a technical monitoring perspective: everything is OK
From the user’s perspective: the system is broken
Real impact:
- Up to 70% of incidents in e-commerce occur in complex flows, not individual components
- E2E failures directly impact revenue
Concrete example:
- Login works
- Cart works
- Payment fails at the final step
This does not always trigger technical alerts.
How to avoid it:
- Implement continuous end-to-end monitoring
- Validate complete user flows
- Measure success of critical processes
This is the ideal scenario for Synthetic Monitoring, as it simulates real user actions—something passive infrastructure monitoring cannot detect.
Most incidents do not start with a failure. They start with a degradation.
Typical signals:
- Gradual increase in latency
- Intermittent timeouts
- Errors in p95/p99
These signals often appear hours before an actual failure.
For example, an increase in p99 latency from 400 ms to 800 ms indicates an imminent degradation, even if average latency (p50) remains stable.
The problem:
- They don’t cross thresholds
- They don’t trigger immediate alerts
- They are ignored
Real impact:
- More than 80% of critical incidents have detectable early signals
- Without predictive analysis, these signals are missed
Example:
- Payment API latency increases from 200 ms to 450 ms
- No alert is triggered
- 2 hours later, the system collapses
How to avoid it:
- Analyze historical behavior
- Detect early anomalies
- Use predictive models
Many SLAs fail because they were poorly defined from the start.
Common mistakes:
- Based only on uptime (availability), not on user-experience SLIs/SLOs (like latency or error rate)
- No historical data
- Not aligned with real architecture
- Overly ambitious
Example:
- A 99.999% SLA without the infrastructure to support it
Real impact:
- Constant breaches
- Friction between business and engineering
- Loss of credibility
This is one of the most common and least discussed problems.
Many companies operate with SLAs defined 2–3 years ago that:
- Do not reflect current architecture
- Do not account for new dependencies
- Are not aligned with current business priorities
Real impact:
- Irrelevant metrics
- Unachievable or meaningless targets
- Total misalignment between teams
How to avoid it:
- Review SLAs quarterly or semi-annually
- Adjust them based on system evolution
- Incorporate new relevant metrics
Overcoming these challenges requires a shift in approach.
Move from:
- Reactive monitoring
- Threshold-based alerts
- Manual diagnosis
To:
- Predictive monitoring
- Anomaly detection
- Continuous flow validation
1. Continuous E2E monitoring
Allows you to validate:
- Real user experience
- Critical flows
- Business impact
2. Anomaly detection
Identifies:
- Behavioral changes
- Early degradations
- Invisible patterns
3. Predictive analysis
Enables:
- Incident anticipation
- Reduced MTTD
- Reduced MTTR
4. Intelligent prioritization
Not all issues have the same impact.
You should prioritize:
- Critical flows
- Metrics that affect SLAs
UptimeBolt directly addresses the root causes of SLA failures.
It does not replace observability—it makes it actionable.
It enables you to:
- Monitor real SLIs
- Validate E2E flows
- Detect anomalies before incidents
- Predict degradations
- Reduce alert noise
Practical example:
In a traditional system:
- The SLA is breached
- It is detected
- Action is taken
With UptimeBolt:
- A latency deviation is detected
- An alert is triggered before impact
- Preventive action is taken
Result:
- Fewer incidents
- Lower operational impact
- Higher SLA compliance
- Better user experience
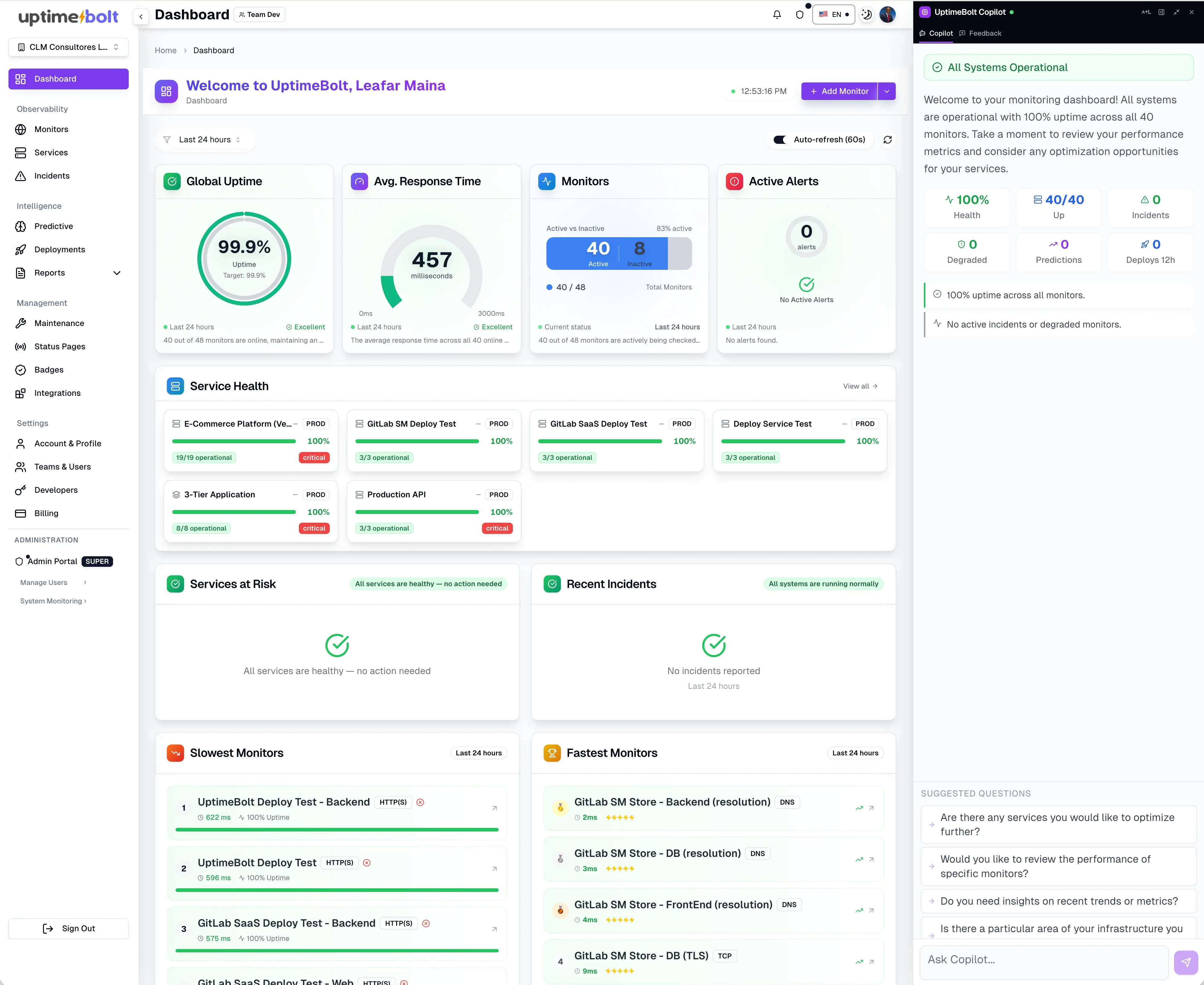
The biggest mistake is thinking an SLA is fulfilled just because it is defined.
An SLA is not met on paper—it is met in operation.
Organizations that consistently meet their SLAs are not those with better contracts, but those that:
- Detect earlier
- Understand better
- Act faster
- Prevent more
SLA compliance is not a state—it is a continuous practice.
And in modern systems, that practice depends directly on your ability to anticipate problems, not just react to them.
If you want to improve your SLA compliance through predictive monitoring, anomaly detection, and E2E validation, we invite you to get started with UptimeBolt through a free trial.
In modern environments, SLAs are no longer the best starting point for understanding the true reliability of a system. While SLAs define the external promise to the customer, SLOs (Service Level Objectives) represent the internal capability to meet that promise. The problem is that, in many organizations, there is a structural gap between the two: what is promised is not aligned with what the system can realistically sustain in operation.
This disconnect is rarely due to a lack of concern for reliability, but rather to limitations in observability, metric definition, and operational maturity. Without clear visibility into latency, errors, or degradations, teams operate “blind,” unable to measure whether their SLOs are at risk until the impact is already visible to the end user.
According to recent industry reports (such as DORA reports or analyses from firms like Gartner), more than 60% of organizations consistently fail to meet their service level objectives, especially in distributed architectures. Most concerning is not just the failure itself, but the fact that in many cases it is not detected in time.
The problem is not the SLA as a concept, but how reliability is operationalized. The causes of failure are usually operational, technical, and organizational. And in most cases, they are avoidable.
Error 1: Monitoring that detects issues too late
The first major issue is relying on monitoring that only detects problems after they have already impacted the user.
Most traditional tools operate under a simple model:
The problem is that by the time an alert fires, the SLA is already compromised.
Typical example:
This type of monitoring is useful for detecting outages, but not degradations.
Real impact:
How to avoid it:
Error 2: Over-reliance on reactive alerts
Related to the above, many organizations depend almost entirely on alerts to operate.
The problem is that not all failures generate clear alerts.
Worse, many alerts do not require action.
Studies in SRE teams show that between 30% and 40% of alerts are false positives or noise.
This leads to:
Real impact:
Example:
How to avoid it:
Error 3: Not measuring critical end-to-end flows (No Synthetic Monitoring)
One of the most underestimated mistakes is monitoring components instead of user experiences.
Modern systems rarely fail at a single point. They fail at the interaction between multiple components.
Classic example:
From a technical monitoring perspective: everything is OK
From the user’s perspective: the system is broken
Real impact:
Concrete example:
This does not always trigger technical alerts.
How to avoid it:
This is the ideal scenario for Synthetic Monitoring, as it simulates real user actions—something passive infrastructure monitoring cannot detect.
Error 4: Not anticipating degradations in APIs or databases
Most incidents do not start with a failure. They start with a degradation.
Typical signals:
These signals often appear hours before an actual failure.
For example, an increase in p99 latency from 400 ms to 800 ms indicates an imminent degradation, even if average latency (p50) remains stable.
The problem:
Real impact:
Example:
How to avoid it:
Error 5: Poorly designed or unrealistic SLAs
Many SLAs fail because they were poorly defined from the start.
Common mistakes:
Example:
Real impact:
Error 6: Outdated SLAs
This is one of the most common and least discussed problems.
Many companies operate with SLAs defined 2–3 years ago that:
Real impact:
How to avoid it:
How to avoid these errors with predictive monitoring and synthetic flows
Overcoming these challenges requires a shift in approach.
Move from:
To:
Key elements
1. Continuous E2E monitoring
Allows you to validate:
2. Anomaly detection
Identifies:
3. Predictive analysis
Enables:
4. Intelligent prioritization
Not all issues have the same impact.
You should prioritize:
UptimeBolt: From Reaction to Control, Ensuring SLAs with Predictive Reliability
UptimeBolt directly addresses the root causes of SLA failures.
It does not replace observability—it makes it actionable.
It enables you to:
Practical example:
In a traditional system:
With UptimeBolt:
Result:
Conclusion: SLA compliance is a practice, not a document
The biggest mistake is thinking an SLA is fulfilled just because it is defined.
An SLA is not met on paper—it is met in operation.
Organizations that consistently meet their SLAs are not those with better contracts, but those that:
SLA compliance is not a state—it is a continuous practice.
And in modern systems, that practice depends directly on your ability to anticipate problems, not just react to them.
If you want to improve your SLA compliance through predictive monitoring, anomaly detection, and E2E validation, we invite you to get started with UptimeBolt through a free trial.