For a long time, IT incidents were treated as unpredictable events: “things that happen,” “inevitable failures,” or simply consequences of complexity. However, experience accumulated across thousands of real-world incidents shows otherwise: most incidents are not random. In fact, there are almost always early signals that, if detected in time, allow teams to act before the impact reaches users.
Studies from the Ponemon Institute estimate that the average cost of a critical IT outage exceeds USD 9,000 per minute in industries such as e-commerce and fintech, while Gartner has indicated that more than 70% of severe incidents present detectable symptoms before total service failure. The problem is not a lack of data, but the human inability to detect subtle patterns early enough.
This is where artificial intelligence changes the game. It does not replace teams, but it enables the identification of degradations, anomalies, and atypical behaviors while there is still room to act.
In this article, we analyze the 7 most common causes of IT incidents that AI can anticipate, with real examples, concrete signals, and prevention strategies before they become visible outages. The focus is on modern e-commerce, SaaS, and fintech systems, where downtime is not just a technical issue—it is a direct business problem.
When a major incident occurs, postmortem analysis often reveals a familiar story: small degradations that were ignored, alerts that did not seem critical, metrics “within normal limits” that were already showing concerning patterns.
Incidents are typically the result of:
- Accumulation of small changes
- Dependencies that degrade slowly
- Unanticipated traffic growth
- Progressive resource saturation
- Silent errors that go unnoticed
The difference between a critical incident and a controlled degradation is often the moment of detection. AI does not prevent systems from failing, but it makes visible what traditional monitoring fails to detect in time.
A continuous and incremental decline in a Service Level Indicator (SLI), where the value remains within traditional alert thresholds, but the rate of change signals an imminent failure.
A payments API began showing a gradual increase in average latency:
- Day 1: 420 ms
- Day 2: 680 ms
- Day 3: 1.1 s
- Day 4: 2.3 s
There were no errors or outages, but conversion dropped by 11%. Four hours later, the service collapsed due to cascading timeouts.
An anomaly detection model identified the deviation from historical patterns 4 hours before total failure, when latency was still “within acceptable parameters.”
- Trend analysis, not just absolute values
- Comparison against historical behavior
- Detection of slope changes (rate of change)
- Monitor percentiles (p95, p99), not just averages
- Detect slow degradations
- Act before users perceive impact
Resource saturation remains a central cause of incidents, but it rarely happens instantly. There are usually early signals: increasing latency, longer queues, growing lock times.
A relational database began showing:
- Stable CPU usage (65–70%)
- Progressive increase in query execution time
- Growth in active connection pool usage
The system functioned “normally” for hours until it hit the connection limit and started rejecting requests. The impact was total.
AI detected the saturation pattern 90 minutes earlier by identifying anomalous growth in response time variability.
- Variability in query times
- Correlation between load and latency
- Repetitive contention patterns
- Alert on trends, not just thresholds
- Scale before collapse
- Prioritize critical queries
Intermittent errors are particularly dangerous because they do not always trigger clear alerts. A small percentage of timeouts may not seem critical—but it is enough to break entire flows.
An external API began showing:
- 1.2% timeouts
- Erratic latency between 300 ms and 4 s
The error rate did not exceed configured thresholds. However, checkout failed randomly.
AI detected an anomalous intermittency pattern 2 hours earlier, allowing traffic redirection and preventing an outage.
- Uses clustering models to identify non-deterministic failure patterns (“low-rate anomalies”) that threshold-based monitoring ignores
- Analyzes correlation between errors and context
- Detects unusual behavior even at low volume
Traffic spikes are not always DDoS attacks. Often, they are successful campaigns, marketing events, or poorly controlled integrations.
A SaaS platform received a 180% traffic increase within 20 minutes after an external integration. No immediate errors occurred, but latency doubled.
AI detected the pattern as anomalous traffic 35 minutes before internal services became saturated.
- Sudden changes in access patterns
- Unusual distribution by region or endpoint
- Unexpected concurrency growth
- Implement adaptive rate limiting
- Decouple critical flows (e.g., authentication vs. logging)
- Protect essential services
- Prioritize legitimate traffic
In distributed architectures, a microservice may remain active but stop fulfilling its function: queues not processed, workers blocked, events not consumed.
A message consumer remained active but stopped processing events after a deployment. No errors or alerts were triggered.
AI detected the absence of expected behavior (functional heartbeats) and alerted 3 hours before user impact became visible.
- Comparison against expected behavior
- Identification of anomalous silence
- End-to-end (E2E) flow analysis
Certificate expiration continues to cause major outages despite being entirely predictable.
A TLS certificate was 5 days away from expiration. No one noticed. Upon expiration, 100% of HTTPS traffic failed.
AI detected the risk 72 hours earlier by correlating expiration date with critical service dependency.
- Monitor expirations with context
- Alert based on real impact
- Automate renewals
Poorly coordinated DNS changes can generate latency, regional errors, or partial outages that are difficult to diagnose.
A DNS change reduced TTL and redirected traffic to an unprepared region. The impact was progressive.
AI detected regional anomalies and increased latency 1 hour before total collapse.
- Changes in geographic traffic patterns
- Uneven latency between regions
- Errors correlated with DNS resolution
AI does not “guess.” It observes, compares, and learns.
Models are based on:
- Time series analysis
- Historical behavior
- Signal correlation
- Operational context
This enables a shift from reactive alerts to early detection, reducing MTTD, MTTR, and error budget consumption.
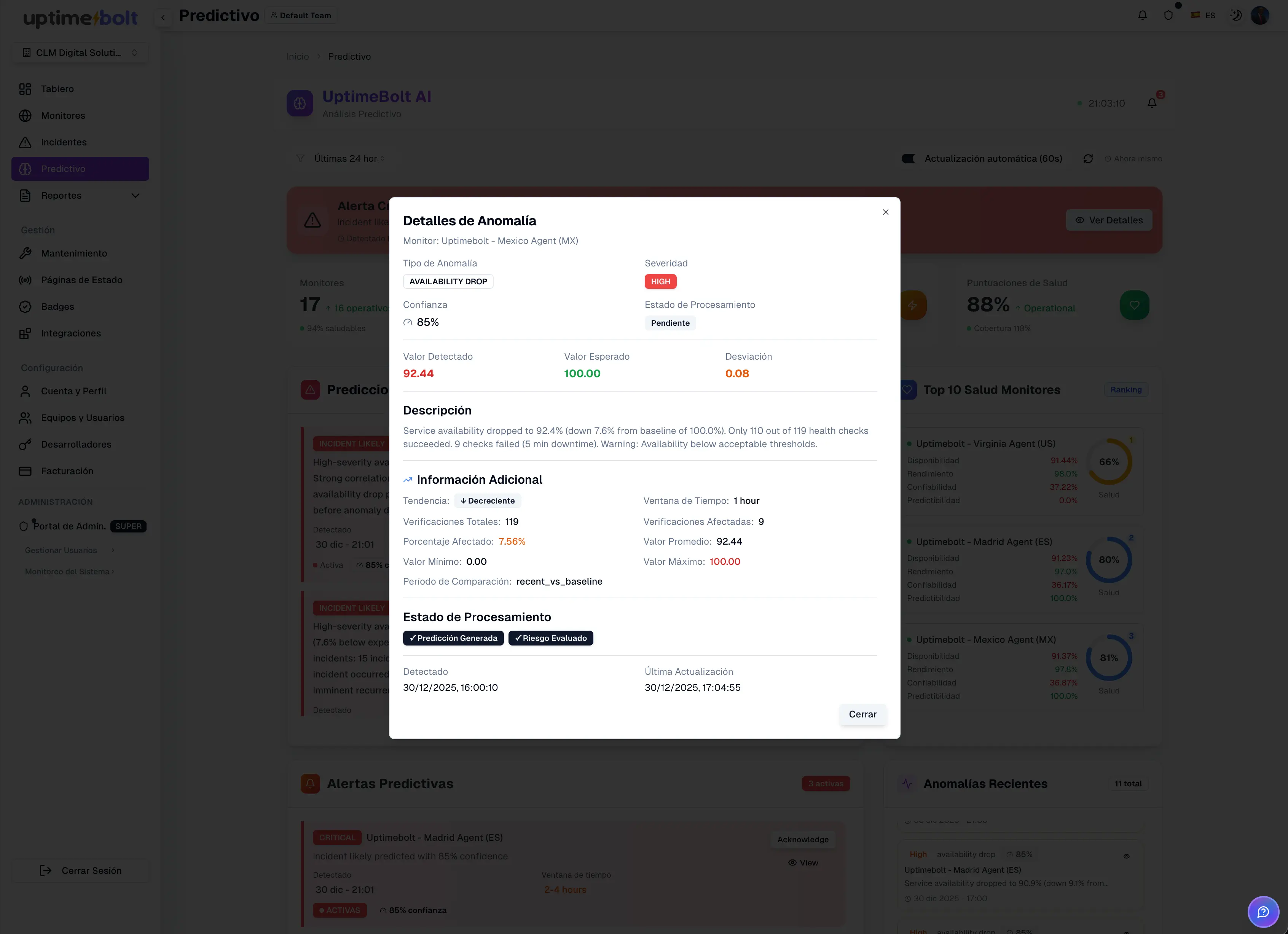
IT incidents rarely appear out of nowhere. In most cases, systems show warning signs before failure. The problem is that these signals are often invisible to traditional monitoring.
Artificial intelligence makes it possible to identify degradations, anomalies, and risks while there is still time to act. It does not eliminate failures—but it dramatically reduces their impact.
Adopting a predictive strategy is the new operational standard for achieving true resilience. AI is the only way to scale visibility at the pace of modern infrastructure complexity.
If you want to start anticipating common incidents—such as degradations, saturations, timeouts, anomalous traffic, or silent failures—and reduce the operational cost of downtime, start with UptimeBolt through a free trial and take the first step toward a more preventive, stable, and resilient operation.
For a long time, IT incidents were treated as unpredictable events: “things that happen,” “inevitable failures,” or simply consequences of complexity. However, experience accumulated across thousands of real-world incidents shows otherwise: most incidents are not random. In fact, there are almost always early signals that, if detected in time, allow teams to act before the impact reaches users.
Studies from the Ponemon Institute estimate that the average cost of a critical IT outage exceeds USD 9,000 per minute in industries such as e-commerce and fintech, while Gartner has indicated that more than 70% of severe incidents present detectable symptoms before total service failure. The problem is not a lack of data, but the human inability to detect subtle patterns early enough.
This is where artificial intelligence changes the game. It does not replace teams, but it enables the identification of degradations, anomalies, and atypical behaviors while there is still room to act.
In this article, we analyze the 7 most common causes of IT incidents that AI can anticipate, with real examples, concrete signals, and prevention strategies before they become visible outages. The focus is on modern e-commerce, SaaS, and fintech systems, where downtime is not just a technical issue—it is a direct business problem.
Most Incidents Are NOT Random
When a major incident occurs, postmortem analysis often reveals a familiar story: small degradations that were ignored, alerts that did not seem critical, metrics “within normal limits” that were already showing concerning patterns.
Incidents are typically the result of:
The difference between a critical incident and a controlled degradation is often the moment of detection. AI does not prevent systems from failing, but it makes visible what traditional monitoring fails to detect in time.
Cause 1: Progressive Performance Degradation
A continuous and incremental decline in a Service Level Indicator (SLI), where the value remains within traditional alert thresholds, but the rate of change signals an imminent failure.
Real Mini Case
A payments API began showing a gradual increase in average latency:
There were no errors or outages, but conversion dropped by 11%. Four hours later, the service collapsed due to cascading timeouts.
An anomaly detection model identified the deviation from historical patterns 4 hours before total failure, when latency was still “within acceptable parameters.”
How AI Detects This Cause
How to Prevent It
Cause 2: Database or Server Saturation
Critical Resource Contention and Early Warning Signals
Resource saturation remains a central cause of incidents, but it rarely happens instantly. There are usually early signals: increasing latency, longer queues, growing lock times.
Real Mini Case
A relational database began showing:
The system functioned “normally” for hours until it hit the connection limit and started rejecting requests. The impact was total.
AI detected the saturation pattern 90 minutes earlier by identifying anomalous growth in response time variability.
Signals AI Uses
Prevention
Cause 3: Timeouts and Intermittent API Errors
The Invisible Enemy
Intermittent errors are particularly dangerous because they do not always trigger clear alerts. A small percentage of timeouts may not seem critical—but it is enough to break entire flows.
Real Mini Case
An external API began showing:
The error rate did not exceed configured thresholds. However, checkout failed randomly.
AI detected an anomalous intermittency pattern 2 hours earlier, allowing traffic redirection and preventing an outage.
How AI Helps
Cause 4: Anomalous Traffic or Unexpected Spikes
Not Every Spike Is an Attack
Traffic spikes are not always DDoS attacks. Often, they are successful campaigns, marketing events, or poorly controlled integrations.
Real Mini Case
A SaaS platform received a 180% traffic increase within 20 minutes after an external integration. No immediate errors occurred, but latency doubled.
AI detected the pattern as anomalous traffic 35 minutes before internal services became saturated.
Key Signals
Prevention
Cause 5: Silent Failures in Microservices
When “Everything Is Up” but Nothing Works Properly
In distributed architectures, a microservice may remain active but stop fulfilling its function: queues not processed, workers blocked, events not consumed.
Real Mini Case
A message consumer remained active but stopped processing events after a deployment. No errors or alerts were triggered.
AI detected the absence of expected behavior (functional heartbeats) and alerted 3 hours before user impact became visible.
Detection
Cause 6: Expired SSL/TLS Certificates
The Most Avoidable (and Most Common) Incident
Certificate expiration continues to cause major outages despite being entirely predictable.
Real Mini Case
A TLS certificate was 5 days away from expiration. No one noticed. Upon expiration, 100% of HTTPS traffic failed.
AI detected the risk 72 hours earlier by correlating expiration date with critical service dependency.
Prevention
Cause 7: Unplanned DNS Changes
The Domino Effect of DNS
Poorly coordinated DNS changes can generate latency, regional errors, or partial outages that are difficult to diagnose.
Real Mini Case
A DNS change reduced TTL and redirected traffic to an unprepared region. The impact was progressive.
AI detected regional anomalies and increased latency 1 hour before total collapse.
Signals Used
How AI Detects These Signals Before They Escalate
AI does not “guess.” It observes, compares, and learns.
Models are based on:
This enables a shift from reactive alerts to early detection, reducing MTTD, MTTR, and error budget consumption.
Conclusion: Reducing Incidents Starts by Anticipating Them
IT incidents rarely appear out of nowhere. In most cases, systems show warning signs before failure. The problem is that these signals are often invisible to traditional monitoring.
Artificial intelligence makes it possible to identify degradations, anomalies, and risks while there is still time to act. It does not eliminate failures—but it dramatically reduces their impact.
Adopting a predictive strategy is the new operational standard for achieving true resilience. AI is the only way to scale visibility at the pace of modern infrastructure complexity.
If you want to start anticipating common incidents—such as degradations, saturations, timeouts, anomalous traffic, or silent failures—and reduce the operational cost of downtime, start with UptimeBolt through a free trial and take the first step toward a more preventive, stable, and resilient operation.