For years, most technical teams have operated under an implicit premise: incidents are inevitable, what matters is reacting quickly. This mindset shaped tools, processes, and entire cultures built around alerts, on-calls, and war rooms that activate once something has already broken.
The problem is that in modern digital platforms, reacting is no longer enough. When a user experiences slowness, errors, or outages, the damage has already occurred: a sale was lost, a transaction failed, trust was weakened, or reputation was affected. Reactive monitoring detects failure; proactive monitoring aims to prevent that failure from ever reaching the user.
This article explores in depth the difference between reactive monitoring and proactive monitoring—not from the perspective of advanced tools or complex predictive models, but from the cultural and operational shift required to move from firefighting to prevention. We will also examine the real costs of downtime, concrete scenarios, the metrics involved, and how to progressively migrate toward a proactive model without disrupting existing operations.
Most teams believe they monitor effectively because they receive alerts. However, many of those alerts arrive when users are already experiencing the issue—or even when the impact is already significant.
Classic symptoms of this approach include:
- Alerts triggered after visible error spikes
- Incidents detected by customers before the team notices
- Dashboards that “turn red” when the damage is already done
- Reactive, stressful, and frequent on-calls
- Postmortems that always conclude: “We should have seen it earlier”
This model does not fail due to lack of effort, but by design. Reactive monitoring is built to confirm that something has broken, not to anticipate that something is degrading.
Reactive monitoring is based on predefined rules and thresholds. The system observes known metrics and generates alerts when they cross a limit considered “unacceptable.”
Typical examples include:
- CPU > 85% for 5 minutes
- HTTP 5xx error rate > 2%
- Service not responding
- Job not executed within the expected interval
This approach answers the question:
Has something already broken or clearly gone out of bounds?
It would be a mistake to say reactive monitoring has no value. In fact, it remains essential for:
- Confirming availability
- Meeting basic SLAs
- Detecting binary failures (up/down)
- Automating simple responses
- Providing minimum operational visibility
The issue is not its existence, but relying on it exclusively.
Reactive monitoring has clear limitations:
- It does not detect gradual degradation
- It lacks contextual understanding
- It generates significant noise in complex systems
- It reacts only when impact is already visible
- It requires predefined scenarios for every possible failure
In modern architectures, where “normal” behavior constantly shifts, these limitations become critical.
Proactive monitoring does not wait for a metric to cross a fixed threshold. Instead, it seeks early signals that something is deviating from normal behavior—even if there are no visible errors yet.
The question changes from:
“Is it broken?”
to
“Is this behavior normal for this system at this moment?”
Being proactive does not mean predicting the future with mathematical certainty. It means detecting degradation before it becomes an incident.
A proactive monitoring model pays attention to:
- Trends, not just absolute values
- Subtle shifts in latency or performance
- Anomalous variability (jitter)
- Historical and seasonal patterns
- Atypical behavior in critical flows
Often, before an outage occurs, the system “signals” subtle warnings that reactive monitoring ignores.
For technical audiences, “proactive” and “predictive” may sound similar, but they are not the same.
- Proactive: Detecting and acting before the user feels the impact.
- Predictive: Using models to estimate that an incident will occur in the future.
Proactive monitoring can leverage predictive techniques, but it does not depend entirely on them. In fact, advanced predictive monitoring deserves its own dedicated discussion.
This article positions proactive monitoring as the foundation upon which more sophisticated predictive models can later be built.
In organizations with reactive monitoring:
- Typical MTTD: 15–45 minutes
- Users often notice the issue first
In organizations with proactive monitoring:
- MTTD: 3–10 minutes
- In many cases, detection occurs before visible impact
The difference is not technical—it is operational.
This is where the discussion stops being philosophical.
Widely cited data includes:
- Gartner estimates the average cost of IT downtime at around $5,600 per minute, depending on the industry.
- The Ponemon Institute reports that in e-commerce and fintech, the cost can exceed $9,000 per minute during critical events.
- Amazon has historically estimated losses of over $100,000 per minute during high-traffic outages.
If reactive monitoring detects an incident 30 minutes late, the financial impact can be enormous—even if recovery is fast.
Proactive monitoring does not eliminate all incidents, but it dramatically reduces exposure time—which is what truly drives cost.
Reactive monitoring often generates:
- Too many alerts
- Alert fatigue
- Constant on-calls
- Burnout among SRE and DevOps teams
A proactive approach reduces noise by prioritizing meaningful signals rather than every irrelevant fluctuation.
An e-commerce platform experiences a gradual increase in checkout latency over several hours. No fixed thresholds are crossed, so no alerts fire. Conversion drops by 8%.
A proactive approach would have detected the anomalous latency pattern before the impact became significant.
A service begins showing increased variability in response times due to connection saturation. The service never fully crashes but becomes unstable.
Reactive monitoring does not trigger alerts. Proactive monitoring detects the growing jitter and enables action before collapse.
An external API responds slower than usual without returning errors. The impact propagates through internal flows.
Reactive monitoring sees “everything up.” Proactive monitoring detects behavioral deviation.
Migration does not mean discarding what already exists. The shift should be incremental.
The first change is conceptual. Binary availability does not reflect real user experience.
Not everything should be monitored equally. Identify:
- Login
- Checkout
- Payments
- Core APIs
These flows should become the focus of proactive monitoring.
Start observing:
- Trends
- Variability
- Slow degradation
Not just absolute values.
Fewer alerts, better context.
Playbooks, mitigation strategies, and automation should be ready in advance.
Artificial intelligence does not replace proactive monitoring—it amplifies it.
AI enables teams to:
- Detect anomalies that do not cross thresholds
- Identify invisible patterns
- Prioritize real risks
- Reduce false positives
- Accelerate decision-making
This is where proactive monitoring becomes a sustainable competitive advantage.
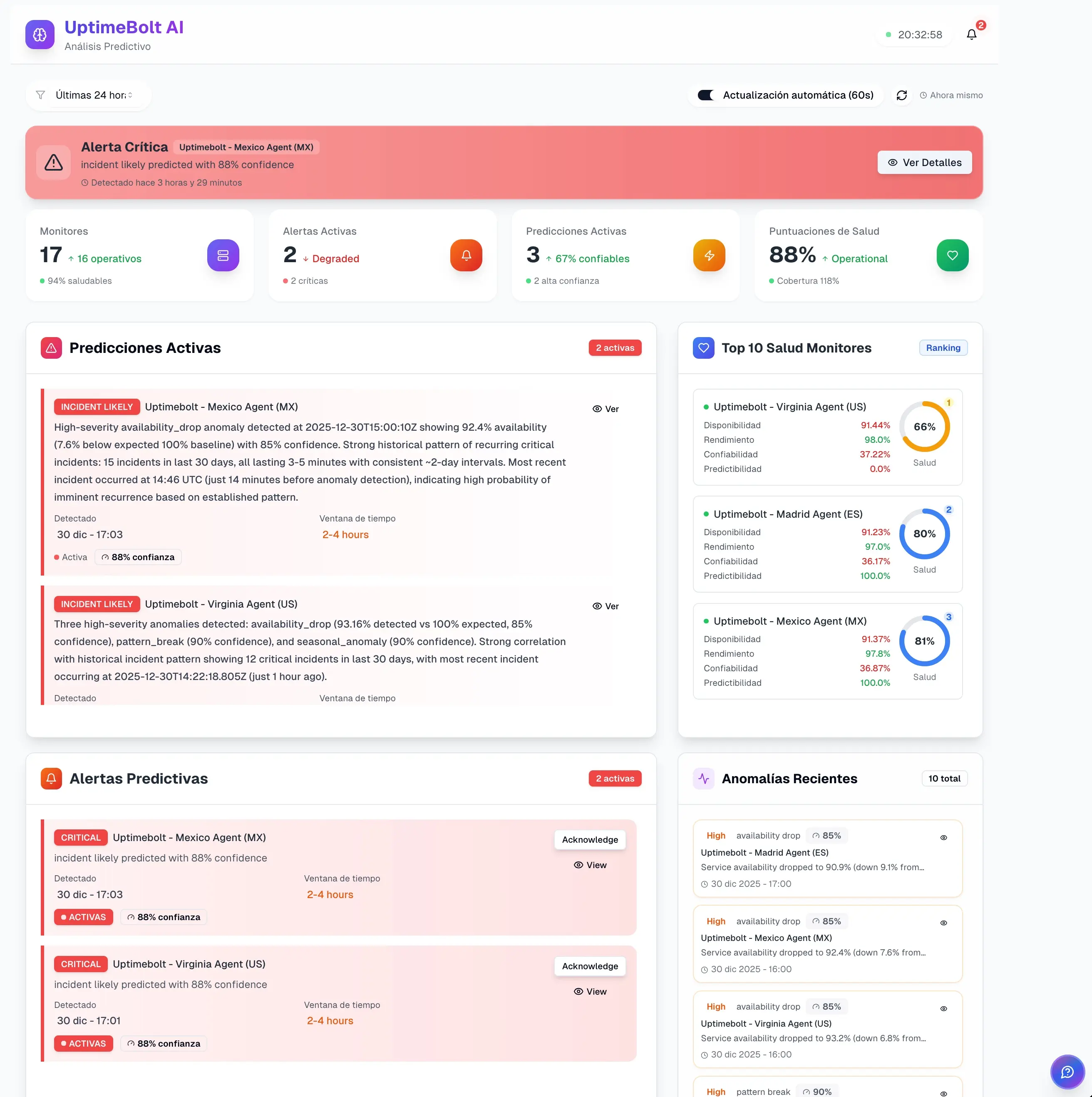
Reactive monitoring will continue to exist, but it can no longer be the center of operations. In modern platforms, reacting quickly is not enough when damage occurs in seconds.
Proactive monitoring represents a cultural shift: moving from confirming failures to preventing impact, from firefighting to reducing the probability of fires altogether.
Organizations that adopt this approach not only reduce downtime, but also improve user experience, lower operational costs, and protect their teams.
If you want to begin evolving from reactive monitoring to a more proactive and preventive model, start with UptimeBolt through a free trial and take the first step toward a more stable, predictable, and resilient operation.
For years, most technical teams have operated under an implicit premise: incidents are inevitable, what matters is reacting quickly. This mindset shaped tools, processes, and entire cultures built around alerts, on-calls, and war rooms that activate once something has already broken.
The problem is that in modern digital platforms, reacting is no longer enough. When a user experiences slowness, errors, or outages, the damage has already occurred: a sale was lost, a transaction failed, trust was weakened, or reputation was affected. Reactive monitoring detects failure; proactive monitoring aims to prevent that failure from ever reaching the user.
This article explores in depth the difference between reactive monitoring and proactive monitoring—not from the perspective of advanced tools or complex predictive models, but from the cultural and operational shift required to move from firefighting to prevention. We will also examine the real costs of downtime, concrete scenarios, the metrics involved, and how to progressively migrate toward a proactive model without disrupting existing operations.
The Problem with Relying on Alerts When It’s Already Too Late
Most teams believe they monitor effectively because they receive alerts. However, many of those alerts arrive when users are already experiencing the issue—or even when the impact is already significant.
Classic symptoms of this approach include:
This model does not fail due to lack of effort, but by design. Reactive monitoring is built to confirm that something has broken, not to anticipate that something is degrading.
Reactive Monitoring: How It Works and Why It Limits Reliability
What Is Reactive Monitoring?
Reactive monitoring is based on predefined rules and thresholds. The system observes known metrics and generates alerts when they cross a limit considered “unacceptable.”
Typical examples include:
This approach answers the question:
Advantages of Reactive Monitoring
It would be a mistake to say reactive monitoring has no value. In fact, it remains essential for:
The issue is not its existence, but relying on it exclusively.
Structural Limitations
Reactive monitoring has clear limitations:
In modern architectures, where “normal” behavior constantly shifts, these limitations become critical.
Proactive Monitoring: Anticipation, Patterns, and Prevention
What Does Being Proactive Really Mean?
Proactive monitoring does not wait for a metric to cross a fixed threshold. Instead, it seeks early signals that something is deviating from normal behavior—even if there are no visible errors yet.
The question changes from:
to
Being proactive does not mean predicting the future with mathematical certainty. It means detecting degradation before it becomes an incident.
What a Proactive Approach Observes
A proactive monitoring model pays attention to:
Often, before an outage occurs, the system “signals” subtle warnings that reactive monitoring ignores.
Proactive vs. Predictive (Key Clarification)
For technical audiences, “proactive” and “predictive” may sound similar, but they are not the same.
Proactive monitoring can leverage predictive techniques, but it does not depend entirely on them. In fact, advanced predictive monitoring deserves its own dedicated discussion.
This article positions proactive monitoring as the foundation upon which more sophisticated predictive models can later be built.
Direct Comparison: Time, Cost, Impact, and Noise
Detection and Reaction Time
In organizations with reactive monitoring:
In organizations with proactive monitoring:
The difference is not technical—it is operational.
The Real Costs of Downtime: Hard Data
This is where the discussion stops being philosophical.
Widely cited data includes:
If reactive monitoring detects an incident 30 minutes late, the financial impact can be enormous—even if recovery is fast.
Proactive monitoring does not eliminate all incidents, but it dramatically reduces exposure time—which is what truly drives cost.
Operational Noise and Human Burnout
Reactive monitoring often generates:
A proactive approach reduces noise by prioritizing meaningful signals rather than every irrelevant fluctuation.
Real Scenarios Where a Proactive Approach Could Have Prevented Incidents
Case 1: Slow Checkout Degradation
An e-commerce platform experiences a gradual increase in checkout latency over several hours. No fixed thresholds are crossed, so no alerts fire. Conversion drops by 8%.
A proactive approach would have detected the anomalous latency pattern before the impact became significant.
Case 2: Progressive Connection Pool Exhaustion
A service begins showing increased variability in response times due to connection saturation. The service never fully crashes but becomes unstable.
Reactive monitoring does not trigger alerts. Proactive monitoring detects the growing jitter and enables action before collapse.
Case 3: Degraded External Dependency
An external API responds slower than usual without returning errors. The impact propagates through internal flows.
Reactive monitoring sees “everything up.” Proactive monitoring detects behavioral deviation.
How to Gradually Migrate Toward a Proactive Monitoring Model
Migration does not mean discarding what already exists. The shift should be incremental.
Step 1: Accept That “Up” Is Not Enough
The first change is conceptual. Binary availability does not reflect real user experience.
Step 2: Identify Critical Business Flows
Not everything should be monitored equally. Identify:
These flows should become the focus of proactive monitoring.
Step 3: Incorporate Behavioral Monitoring
Start observing:
Not just absolute values.
Step 4: Reduce Noise Before Adding More Signals
Fewer alerts, better context.
Step 5: Prepare Responses Before Incidents Occur
Playbooks, mitigation strategies, and automation should be ready in advance.
The Role of AI in Failure Anticipation
Artificial intelligence does not replace proactive monitoring—it amplifies it.
AI enables teams to:
This is where proactive monitoring becomes a sustainable competitive advantage.
Conclusion: The New Standard Is Acting Before Users Feel the Impact
Reactive monitoring will continue to exist, but it can no longer be the center of operations. In modern platforms, reacting quickly is not enough when damage occurs in seconds.
Proactive monitoring represents a cultural shift: moving from confirming failures to preventing impact, from firefighting to reducing the probability of fires altogether.
Organizations that adopt this approach not only reduce downtime, but also improve user experience, lower operational costs, and protect their teams.
If you want to begin evolving from reactive monitoring to a more proactive and preventive model, start with UptimeBolt through a free trial and take the first step toward a more stable, predictable, and resilient operation.