Is your observability investment truly protecting your business, or just generating bigger log ingestion bills?
The dilemma between advanced observability and predictive monitoring is no longer technical — it is strategic. In practice, many architecture and reliability investment decisions are still based on a widespread conceptual misunderstanding: treating advanced observability and predictive monitoring as if they were equivalent, or worse, as if one could completely replace the other.
For a CTO, this is not a semantic discussion. It has direct consequences on budget, operational complexity, incident resolution speed, and the real ability to scale a platform without degrading the user experience. As architectures evolve from relatively simple applications into distributed ecosystems with microservices, APIs, queues, workers, external dependencies, and continuous deployments, monitoring stops being a tactical function and becomes a strategic business layer.
The problem is that along this journey, two different needs emerge. The first is understanding what happened and why when something degrades or fails. The second is detecting early warning signs to act before users experience impact. Advanced observability solves the first extremely well. Predictive monitoring is designed for the second.
That is why the central point of this article is simple but important: they are not the same, they do not compete, and they should not be evaluated as direct substitutes. They are complementary layers within a modern reliability strategy. One helps observe and understand. The other helps anticipate and prevent.
For engineering leaders, this distinction is critical because it determines how budgets are allocated, how platforms are designed, and how cognitive load is distributed across teams. Investing only in depth without anticipation can trap an organization in a reactive operating model. Investing only in anticipation without context can generate faster actions but incomplete diagnoses. The right combination, on the other hand, can reduce MTTD, lower MTTR, improve SLA compliance, and better protect the business.
Advanced observability is designed to answer one very specific question:
Why is the system behaving this way?
That “why” is the core of its value. When a platform enters an unexpected state, observability allows teams to explore internal signals and reconstruct system behavior with enough detail to understand the technical root cause of the problem.
In practical terms, its most recognizable capabilities include:
- log analysis
- detailed metrics
- distributed tracing
- deep debugging
- post-incident analysis
- dependency exploration and internal behavior analysis
This makes it especially powerful in distributed environments where visible symptoms rarely match the actual root cause. A frontend latency increase may originate from a slow database query, a degraded external dependency, a configuration change, or anomalous behavior in an internal queue. Advanced observability allows teams to follow that trail.
For SRE or platform teams, this means being able to answer questions such as:
- Which service started the degradation?
- What version was running?
- Which request type was affected?
- Which dependency failed first?
- What changed compared to the normal state?
This deep inspection capability has enormous value, especially for debugging, postmortems, and structural system improvements.
But its strength also defines its limitation. Advanced observability is, in most cases, much stronger at explaining than anticipating. It excels at providing depth, context, and detail once the problem already exists or has left enough traces behind. In other words, it tends to be more reactive than preventive.
Additionally, many implementations still rely heavily on human interpretation. Although modern platforms offer query capabilities, visualizations, and some automated assistance, the leap from “here is the data” to “this is the most likely root cause and this should be the action” still often depends on the team. That requires time, expertise, and operational maturity.
If advanced observability answers the “why,” predictive monitoring answers a different question:
What is starting to behave abnormally, and what could fail if no action is taken?
That shift in focus is fundamental. Predictive monitoring is not built to explain every internal detail of an incident after it occurs. It is designed to identify early signals that precede degradation, saturation, or visible failures.
Its core capabilities typically include:
- anomaly detection
- historical pattern analysis
- proactive alerts
- deviation detection from normal behavior
- risk- or impact-based prioritization
- automated operational signal correlation
The main strength of predictive monitoring lies in detecting problems before users feel the impact. A progressive latency increase, an anomalous p95 variation, intermittent errors that have not yet crossed alert thresholds, emerging saturation in a critical dependency, or a behavior change after a deployment may all be sufficient signals to intervene before visible damage occurs.
This has very concrete implications for CTOs. When a platform can act before impact occurs, it not only improves technical metrics. It also reduces revenue loss, protects customer experience, lowers pressure on teams, and improves operational compliance.
Its limitation, however, is also important: predictive monitoring does not always fully explain the “why.” It may accurately identify that something is entering a risk zone, that a particular flow is degrading, or that a historical incident pattern is repeating itself. But that does not mean it can always independently provide the forensic level of detail that an advanced observability platform can deliver.
That is why a predictive system may identify problems earlier, prioritize better, and reduce response time, while deep incident analysis may still require broader observability capabilities.
The most useful comparison is not philosophical — it is operational. The following table summarizes how value is distributed between both approaches.
| Capability | Advanced Observability | Predictive Monitoring | Both |
|---|
| Log, metrics, and trace analysis | ✔️ | ❌ | |
| Deep diagnosis and debugging | ✔️ | ⚠️ Partial | |
| Anomaly detection | ⚠️ Limited or tool-dependent | ✔️ | |
| Incident anticipation | ❌ | ✔️ | |
| Automated signal correlation | ⚠️ Depends on tool and configuration | ✔️ | |
| Failure prevention | ❌ | ✔️ | |
| End-to-end visibility | ✔️ | ✔️ | ✔️ |
| Post-incident analysis | ✔️ | ⚠️ Supports but does not replace | |
| Operational risk prioritization | ⚠️ Limited | ✔️ | |
| Architectural context understanding | ✔️ | ⚠️ Partial | |
The correct interpretation of this table is not “which one wins,” but rather “what gap does each one leave if used alone?”
This is where one of the most sensitive points for technology leaders appears: the total cost of operating these capabilities.
Advanced observability provides depth. But that depth often comes with significant scaling costs, especially when platforms rely on large volumes of logs, traces, and continuously ingested data.
Tools like Datadog or New Relic are well known precisely for this richness of data — but also for how quickly that model can scale in cost if not rigorously managed.
In contrast, predictive monitoring and AIOps solutions prioritize efficiency in ingestion and processing, focusing on extracting relevant signals instead of accumulating volume.
In large environments, the cost is not limited to licensing or infrastructure. It also includes the engineering time required to govern, tune, query, maintain dashboards, optimize ingestion, and prevent the monitoring system from becoming a data factory with little actionable value.
This is one of the major executive dilemmas: more data does not necessarily mean more value. Many organizations discover that they have technically powerful observability, but operationally expensive systems. They know a lot about the platform, yet still take too long to turn that depth into fast decisions.
Predictive monitoring, on the other hand, is usually far more efficient in how it uses signals. It does not necessarily need to ingest the maximum possible depth from every stack layer to generate value. Its logic is more selective: identify critical patterns, detect meaningful anomalies, anticipate degradation, and reduce operational noise.
That does not make it “better” in every case. It makes it different.
If there were one useful phrase to summarize this for CTOs, it would be:
Observability equals depth.
Predictive monitoring equals efficiency.
Observability allows you to go deeper. Predictive monitoring allows you to act earlier with less friction.
From a scalability perspective, this balance matters enormously. Small and mid-sized teams can drown trying to operate extremely deep platforms without sufficient automation. Larger teams may greatly benefit from that depth, while still requiring a predictive layer to avoid becoming entirely reactive.
The best strategy is not choosing between advanced observability and predictive monitoring. It is designing how they work together.
- Observability explains the incident.
- Predictive monitoring helps prevent it or detect it before it escalates.
That is the ideal workflow in modern operations:
- Predictive monitoring detects an anomaly or risk pattern.
- A proactive alert or contextualized incident is generated.
- Advanced observability enables deep investigation into the affected component, service, or dependency.
- Teams act with better information and less wasted time.
This sequence reduces both MTTD and MTTR.
- It reduces MTTD because issues are detected earlier.
- It reduces MTTR because deep analysis starts with a more accurate hypothesis.
Additionally, this combination lowers business impact. A problem detected early and explained quickly usually requires fewer war rooms, less exposure time, and less friction for end users.
In other words, end-to-end reliability does not come from a single technological layer. It comes from effectively connecting the ability to anticipate with the ability to understand.
This is where artificial intelligence becomes especially relevant.
AI is not important simply because it “automates things.” Its most valuable contribution is transforming scattered data into operationally actionable decisions. It acts as a bridge between the depth of observability and the speed of predictive monitoring.
- automatic signal correlation
- operational noise reduction
- detection of patterns invisible to manual analysis
- contextualization of anomalies with recent changes, traffic, or dependencies
- prioritization based on real risk instead of static thresholds
This matters because, in many teams, the real bottleneck is no longer collecting data. It is interpreting it fast enough to prevent business impact.
AI helps exactly there. It does not eliminate the need for human judgment, but it reduces mechanical work and shortens the path between signal and decision.
For CTOs, this layer provides clear value: it allows observability investments to generate more operational return and transforms monitoring from a chain of isolated alerts into a more strategic operational capability.
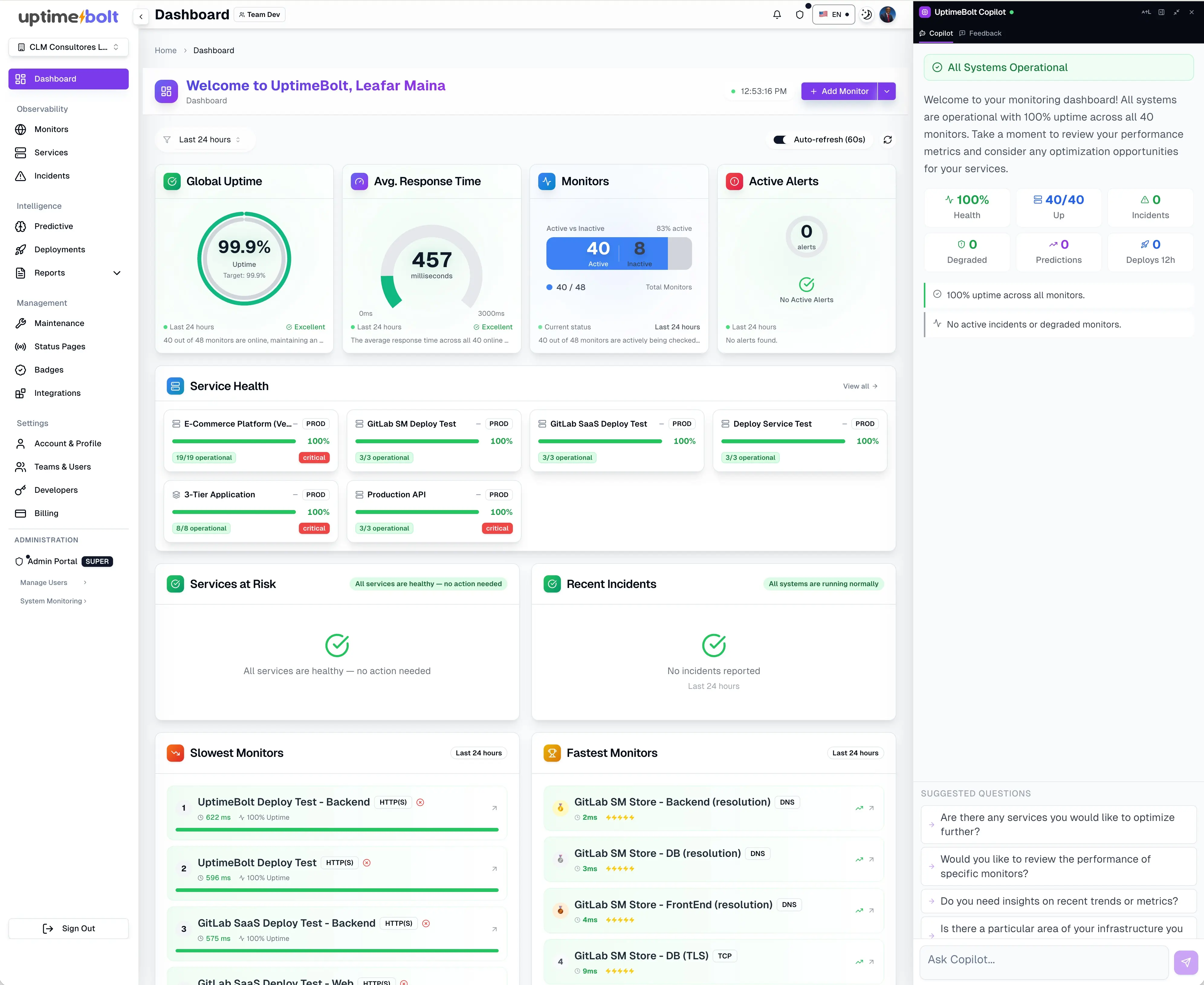
UptimeBolt positions itself precisely in the middle ground where many organizations still have unmet needs: not just observing what happens, but also interpreting and anticipating.
The platform combines:
- integrated predictive monitoring
- anomaly detection
- intelligent event correlation
- visibility into critical flows
- useful diagnostic context
- operational interpretation of degradation and risk
This means it can automatically correlate an abnormal latency increase in the API Gateway with a recent deployment in the authentication service and a drop in distributed cache usage, identifying the root cause in seconds instead of hours of manual analysis.
That means it does not simply say “something is failing.” It seeks to understand which signals are related, which business flow is at risk, whether recent deployments occurred, whether an external dependency is involved, and which pre-incident pattern is repeating itself.
That is the strongest differentiator: it does not just observe — it interprets and anticipates.
From a strategic perspective, this allows it to complement deeper observability capabilities with a layer focused on prevention, prioritization, and noise reduction. It does not attempt to replace the full diagnostic depth of a traditional enterprise observability platform. Instead, it aims to make operations more actionable and less reactive.
For CTOs, that nuance matters because it avoids a false dichotomy. The question is not whether to “see everything” or “anticipate effectively.” The question is where a platform provides depth, where it provides efficiency, and how to avoid operational complexity consuming the value of both.
The debate between advanced observability and predictive monitoring loses value when framed as a competition. The right question is not which one replaces the other, but which layer of modern reliability each one solves.
- Advanced observability enables teams to observe and understand.
- Predictive monitoring enables teams to anticipate and prioritize.
- AI connects both and accelerates the path from data to decision.
That is why the final message for CTOs is simple but important:
Observability without prediction leaves organizations too reactive.
Prediction without context leaves organizations incomplete.
Modern reliability requires observing, understanding, and predicting.
When those three capabilities work together, teams do not just resolve incidents better. They also reduce noise, improve operational costs, scale with greater control, and better protect both user experience and the business itself.
That is the difference between having monitoring tools and having a real reliability strategy.
Learn how to apply this strategy and how UptimeBolt technology can close the reliability loop across your platform.
Is your observability investment truly protecting your business, or just generating bigger log ingestion bills?
The dilemma between advanced observability and predictive monitoring is no longer technical — it is strategic. In practice, many architecture and reliability investment decisions are still based on a widespread conceptual misunderstanding: treating advanced observability and predictive monitoring as if they were equivalent, or worse, as if one could completely replace the other.
For a CTO, this is not a semantic discussion. It has direct consequences on budget, operational complexity, incident resolution speed, and the real ability to scale a platform without degrading the user experience. As architectures evolve from relatively simple applications into distributed ecosystems with microservices, APIs, queues, workers, external dependencies, and continuous deployments, monitoring stops being a tactical function and becomes a strategic business layer.
The problem is that along this journey, two different needs emerge. The first is understanding what happened and why when something degrades or fails. The second is detecting early warning signs to act before users experience impact. Advanced observability solves the first extremely well. Predictive monitoring is designed for the second.
That is why the central point of this article is simple but important: they are not the same, they do not compete, and they should not be evaluated as direct substitutes. They are complementary layers within a modern reliability strategy. One helps observe and understand. The other helps anticipate and prevent.
For engineering leaders, this distinction is critical because it determines how budgets are allocated, how platforms are designed, and how cognitive load is distributed across teams. Investing only in depth without anticipation can trap an organization in a reactive operating model. Investing only in anticipation without context can generate faster actions but incomplete diagnoses. The right combination, on the other hand, can reduce MTTD, lower MTTR, improve SLA compliance, and better protect the business.
What Advanced Observability Provides: Understanding the “Why”
Advanced observability is designed to answer one very specific question:
That “why” is the core of its value. When a platform enters an unexpected state, observability allows teams to explore internal signals and reconstruct system behavior with enough detail to understand the technical root cause of the problem.
In practical terms, its most recognizable capabilities include:
This makes it especially powerful in distributed environments where visible symptoms rarely match the actual root cause. A frontend latency increase may originate from a slow database query, a degraded external dependency, a configuration change, or anomalous behavior in an internal queue. Advanced observability allows teams to follow that trail.
For SRE or platform teams, this means being able to answer questions such as:
This deep inspection capability has enormous value, especially for debugging, postmortems, and structural system improvements.
But its strength also defines its limitation. Advanced observability is, in most cases, much stronger at explaining than anticipating. It excels at providing depth, context, and detail once the problem already exists or has left enough traces behind. In other words, it tends to be more reactive than preventive.
Additionally, many implementations still rely heavily on human interpretation. Although modern platforms offer query capabilities, visualizations, and some automated assistance, the leap from “here is the data” to “this is the most likely root cause and this should be the action” still often depends on the team. That requires time, expertise, and operational maturity.
What Predictive Monitoring Provides: Anticipating Before Impact
If advanced observability answers the “why,” predictive monitoring answers a different question:
That shift in focus is fundamental. Predictive monitoring is not built to explain every internal detail of an incident after it occurs. It is designed to identify early signals that precede degradation, saturation, or visible failures.
Its core capabilities typically include:
The main strength of predictive monitoring lies in detecting problems before users feel the impact. A progressive latency increase, an anomalous p95 variation, intermittent errors that have not yet crossed alert thresholds, emerging saturation in a critical dependency, or a behavior change after a deployment may all be sufficient signals to intervene before visible damage occurs.
This has very concrete implications for CTOs. When a platform can act before impact occurs, it not only improves technical metrics. It also reduces revenue loss, protects customer experience, lowers pressure on teams, and improves operational compliance.
Its limitation, however, is also important: predictive monitoring does not always fully explain the “why.” It may accurately identify that something is entering a risk zone, that a particular flow is degrading, or that a historical incident pattern is repeating itself. But that does not mean it can always independently provide the forensic level of detail that an advanced observability platform can deliver.
That is why a predictive system may identify problems earlier, prioritize better, and reduce response time, while deep incident analysis may still require broader observability capabilities.
A Clear Comparison for CTOs
The most useful comparison is not philosophical — it is operational. The following table summarizes how value is distributed between both approaches.
The correct interpretation of this table is not “which one wins,” but rather “what gap does each one leave if used alone?”
Costs and Efficiency: What CTOs Must Consider
This is where one of the most sensitive points for technology leaders appears: the total cost of operating these capabilities.
Advanced observability provides depth. But that depth often comes with significant scaling costs, especially when platforms rely on large volumes of logs, traces, and continuously ingested data.
Tools like Datadog or New Relic are well known precisely for this richness of data — but also for how quickly that model can scale in cost if not rigorously managed.
In contrast, predictive monitoring and AIOps solutions prioritize efficiency in ingestion and processing, focusing on extracting relevant signals instead of accumulating volume.
In large environments, the cost is not limited to licensing or infrastructure. It also includes the engineering time required to govern, tune, query, maintain dashboards, optimize ingestion, and prevent the monitoring system from becoming a data factory with little actionable value.
This is one of the major executive dilemmas: more data does not necessarily mean more value. Many organizations discover that they have technically powerful observability, but operationally expensive systems. They know a lot about the platform, yet still take too long to turn that depth into fast decisions.
Predictive monitoring, on the other hand, is usually far more efficient in how it uses signals. It does not necessarily need to ingest the maximum possible depth from every stack layer to generate value. Its logic is more selective: identify critical patterns, detect meaningful anomalies, anticipate degradation, and reduce operational noise.
That does not make it “better” in every case. It makes it different.
If there were one useful phrase to summarize this for CTOs, it would be:
Observability allows you to go deeper. Predictive monitoring allows you to act earlier with less friction.
From a scalability perspective, this balance matters enormously. Small and mid-sized teams can drown trying to operate extremely deep platforms without sufficient automation. Larger teams may greatly benefit from that depth, while still requiring a predictive layer to avoid becoming entirely reactive.
How They Complement Each Other to Deliver End-to-End Reliability
The best strategy is not choosing between advanced observability and predictive monitoring. It is designing how they work together.
That is the ideal workflow in modern operations:
This sequence reduces both MTTD and MTTR.
Additionally, this combination lowers business impact. A problem detected early and explained quickly usually requires fewer war rooms, less exposure time, and less friction for end users.
In other words, end-to-end reliability does not come from a single technological layer. It comes from effectively connecting the ability to anticipate with the ability to understand.
AI as the Bridge Between Observability and Prevention
This is where artificial intelligence becomes especially relevant.
AI is not important simply because it “automates things.” Its most valuable contribution is transforming scattered data into operationally actionable decisions. It acts as a bridge between the depth of observability and the speed of predictive monitoring.
Where Does AI Add Real Value?
This matters because, in many teams, the real bottleneck is no longer collecting data. It is interpreting it fast enough to prevent business impact.
AI helps exactly there. It does not eliminate the need for human judgment, but it reduces mechanical work and shortens the path between signal and decision.
For CTOs, this layer provides clear value: it allows observability investments to generate more operational return and transforms monitoring from a chain of isolated alerts into a more strategic operational capability.
How UptimeBolt Enhances Both Capabilities in a Single Platform
UptimeBolt positions itself precisely in the middle ground where many organizations still have unmet needs: not just observing what happens, but also interpreting and anticipating.
The platform combines:
This means it can automatically correlate an abnormal latency increase in the API Gateway with a recent deployment in the authentication service and a drop in distributed cache usage, identifying the root cause in seconds instead of hours of manual analysis.
That means it does not simply say “something is failing.” It seeks to understand which signals are related, which business flow is at risk, whether recent deployments occurred, whether an external dependency is involved, and which pre-incident pattern is repeating itself.
That is the strongest differentiator: it does not just observe — it interprets and anticipates.
From a strategic perspective, this allows it to complement deeper observability capabilities with a layer focused on prevention, prioritization, and noise reduction. It does not attempt to replace the full diagnostic depth of a traditional enterprise observability platform. Instead, it aims to make operations more actionable and less reactive.
For CTOs, that nuance matters because it avoids a false dichotomy. The question is not whether to “see everything” or “anticipate effectively.” The question is where a platform provides depth, where it provides efficiency, and how to avoid operational complexity consuming the value of both.
Conclusion
The debate between advanced observability and predictive monitoring loses value when framed as a competition. The right question is not which one replaces the other, but which layer of modern reliability each one solves.
That is why the final message for CTOs is simple but important:
When those three capabilities work together, teams do not just resolve incidents better. They also reduce noise, improve operational costs, scale with greater control, and better protect both user experience and the business itself.
That is the difference between having monitoring tools and having a real reliability strategy.
Learn how to apply this strategy and how UptimeBolt technology can close the reliability loop across your platform.