For years, system monitoring relied on a rules-based approach with rigid threshold alerting: define metrics, set limits, and trigger alerts whenever something exceeded them.
If CPU usage went above 80%, if average latency rose beyond a certain value, or if the error rate spiked, the system would notify the team.
But this model — often centered around averages instead of more representative metrics like p95 or p99 — starts to fail when faced with the real variability of distributed systems.
It still has value, but it falls short compared to the complexity of modern architectures.
Today, applications run in distributed environments with:
- microservices
- internal and external APIs
- queues
- workers
- databases
- caches
- serverless services
- highly variable traffic patterns
In this context, problems do not always appear as abrupt failures.
Many times, they begin as subtle anomalies:
- latency slowly increasing
- a service still responding but with higher jitter
- an external dependency failing only during specific peaks
- a critical flow still working, but inconsistently
This paradigm shift allows organizations to move from Mean Time To Detect (MTTD) to Mean Time To Predict (MTTP), shifting operations from reaction to anticipation.
From an AI system’s perspective, an anomaly is not simply “something bad.”
Nor is it necessarily an error.
An anomaly is behavior that significantly deviates from the expected, learned, or historically observed pattern for a signal, service, or workflow.
That matters because anomalies often appear long before an incident exists.
For example:
- an API that normally responds in 180 ms starts consistently responding in 260 ms
- the p95 of an endpoint increases by 20%, while the average still looks acceptable
- a login flow continues returning 200 OK responses, but completion time rises from 1.1 s to 3.8 s
- a database is not saturated, but query time variability changes compared to its normal behavior
- a worker remains “alive,” but processes events at an abnormal rate
In all these cases, the system may not be “broken” yet.
But it is behaving differently from normal.
For an AI model, that alone is already a valuable signal.
The key is that the model does not need a full outage to learn.
It only needs to recognize:
- historical patterns
- seasonality
- expected noise
- normal variation ranges
When something moves too far outside that framework, it flags it as anomalous.
That is why anomaly detection works especially well in modern monitoring: many incidents do not begin with visible errors, but with small deviations that only make sense when analyzed in context.
There is no single magical algorithm for anomaly detection.
In practice, modern platforms combine multiple techniques depending on:
- signal type
- data volume
- sampling frequency
- system complexity
Statistical approaches remain highly relevant, especially when working with structured metrics and relatively stable time series.
Common techniques include:
- moving averages
- standard deviation
- z-score
- confidence bands
- residual analysis
- ARIMA or SARIMA models
These models are critical because they predict the next expected value in a time series (latency, throughput, etc.).
Anomalies are detected by measuring the deviation between the real value and the prediction (the residual).
The core logic is:
If a signal usually moves within a statistically expected range and suddenly deviates from it, there is a potential anomaly.
For example:
If an API’s average latency usually stays between 120 and 180 ms with known variance, a sustained increase to 260 ms can already be marked as anomalous, even if it has not yet crossed a manual threshold of 500 ms.
- interpretable
- lightweight
- useful for subtle change detection
- limited with highly complex patterns
- struggles with multiple seasonalities
- difficulty handling strong non-linearity
As systems become more complex, classical machine learning algorithms become useful.
Examples include:
- clustering
- k-nearest neighbors
- one-class SVM
- adapted random forests
- isolation forest
These models learn what normal behavior looks like and identify points that appear far away from it.
Clustering groups similar behaviors together.
If most data falls inside known normal groups and a new behavior appears outside those groups, it is considered suspicious.
In monitoring, clustering helps identify operational patterns and detect behaviors that do not fit historical norms.
Isolation Forest is one of the most popular anomaly detection algorithms because it performs well with large datasets.
The intuition behind it is simple:
Anomalous points are easier to isolate than normal ones.
Common points require many splits to isolate.
Rare points become isolated very quickly.
This enables the model to identify unusual observations without needing explicit examples of failures.
It is especially useful when dealing with multiple dimensions such as:
- latency
- errors
- traffic
- memory
- regions
- dependencies
When system behavior becomes highly dynamic and complex, deep learning models become more effective.
Common approaches include:
- autoencoders
- LSTM
- recurrent neural networks
- transformers for time series
Autoencoders learn to reconstruct normal patterns.
They are trained on healthy data and learn how to compress and reconstruct that normality.
When they receive something different, reconstruction quality degrades.
That difference becomes the anomaly signal.
In essence, the system says:
“This does not look like the normal behavior I learned.”
LSTM models capture long-term temporal dependencies.
This matters because not only the current value matters, but also the sequence leading to it.
For example:
A latency of 300 ms may be perfectly normal at a certain time of day, but anomalous if preceded by saturation, jitter, and intermittent errors.
LSTM and RNNs are particularly useful for:
- distributed traces
- logs
- sequential events
One of AI’s biggest strengths in monitoring is that it does not only analyze isolated values.
It analyzes behavior.
The system learns which signals usually appear together.
For example:
It may recognize that a certain traffic level combined with specific latency and cache usage is normal during peak hours, but suspicious during the middle of the night.
Metrics do not need to explode.
A slow, sustained increase may be more important than a single spike.
AI can detect:
- slope changes
- progressive degradation
Many systems have:
patterns.
A Monday morning behaves differently than a Saturday night.
Modern models incorporate seasonality to avoid false alarms caused by expected behavior.
Every signal contains noise.
Not every small change matters.
AI attempts to distinguish between:
- normal variation
- real anomalies
This capability is critical for reducing false positives.
Static thresholds have three major limitations:
- They do not understand context
- They often react too late
- They generate either noise or blindness
AI improves this by working with:
- dynamic baselines
- historical behavior
- contextual analysis
- detects degradation before thresholds are crossed
- reduces false positives
- understands seasonality
- prioritizes anomalous patterns
Thresholds still remain useful as safety nets.
But AI enables a shift from reactive monitoring to preventive monitoring.
A payment API usually has a p95 latency of 220 ms.
During a campaign:
- it rises to 310 ms
- then 420 ms
- later 650 ms
The error rate remains low.
A traditional alert never fires.
AI, however, detects the deviation and allows teams to act before massive timeouts occur.
Checkout works for most users, but fails for 1% of them.
The average looks healthy.
However, AI detects anomalies in:
- p99 latency
- response times
- external dependencies
CPU has not reached its limit.
Connections are still available.
But query time variability changes significantly.
A statistical model or Isolation Forest detects the anomaly before collapse occurs.
The service is still responding.
No visible outage exists.
But:
- memory usage grows abnormally
- garbage collection times change
A sequential model detects the pattern before the issue becomes visible to users.
UptimeBolt combines several of these techniques to build a more predictive and actionable monitoring layer.
The platform:
- analyzes historical behavior
- detects anomalies in real time
- correlates signals across services and APIs
- monitors critical user journeys
- predicts incidents in advance
- early degradation detection
- advanced time-series analysis
- functional and technical correlation
- end-to-end monitoring
- incident prediction
The goal is not to replace traditional monitoring.
It is to radically improve it.
Where a traditional system says:
“Something is already wrong”
UptimeBolt aims to say:
“This behavior is starting to drift and may become an incident.”
That operational shift reduces:
- MTTD
- SLO impact
- reactive firefighting
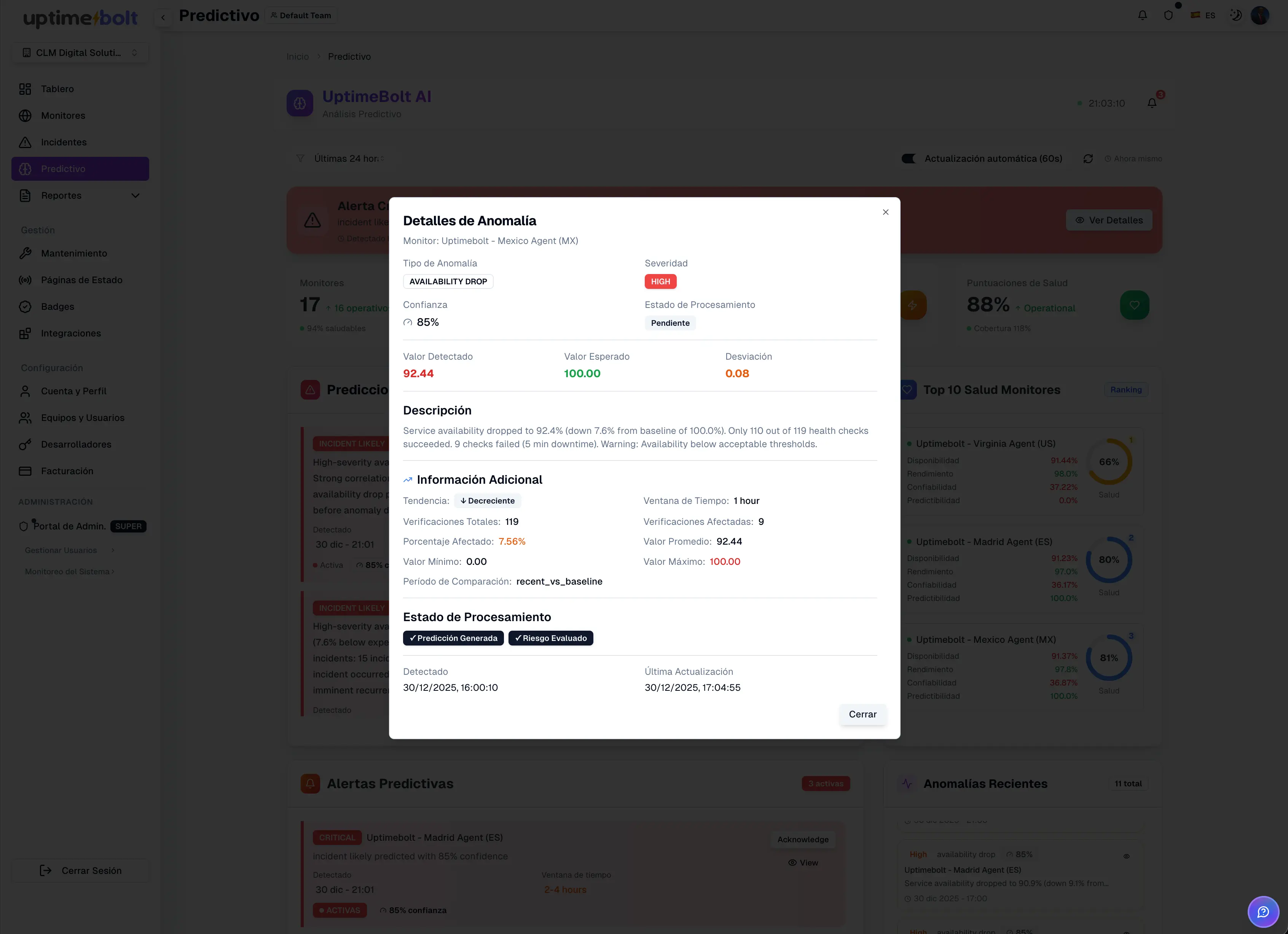
AI-powered monitoring is not magic or an incomprehensible black box.
Behind it are concrete algorithm families:
- statistical models
- classical machine learning
- clustering
- Isolation Forest
- autoencoders
- LSTM
- time-series analysis
All of them aim toward the same core idea:
Detect anomalous behavior before it becomes a critical incident.
Understanding how these models work helps teams trust them.
You do not need to become an expert in every algorithm.
But it is important to understand that anomaly detection relies on:
- patterns
- context
- historical behavior
- real system signals
And in modern monitoring, that makes the difference between reacting too late and acting proactively.
Integrating AI-based anomaly detection is a critical step toward:
- protecting SLOs
- reducing alert noise
- improving observability
- strengthening DevOps operations
How AI Detects Anomalies Before Incidents Happen
For years, system monitoring relied on a rules-based approach with rigid threshold alerting: define metrics, set limits, and trigger alerts whenever something exceeded them.
If CPU usage went above 80%, if average latency rose beyond a certain value, or if the error rate spiked, the system would notify the team.
But this model — often centered around averages instead of more representative metrics like p95 or p99 — starts to fail when faced with the real variability of distributed systems.
It still has value, but it falls short compared to the complexity of modern architectures.
Why Static Thresholds Are No Longer Enough
Today, applications run in distributed environments with:
In this context, problems do not always appear as abrupt failures.
Many times, they begin as subtle anomalies:
This paradigm shift allows organizations to move from Mean Time To Detect (MTTD) to Mean Time To Predict (MTTP), shifting operations from reaction to anticipation.
What Is an Anomaly From an AI System Perspective?
From an AI system’s perspective, an anomaly is not simply “something bad.”
Nor is it necessarily an error.
An anomaly is behavior that significantly deviates from the expected, learned, or historically observed pattern for a signal, service, or workflow.
That matters because anomalies often appear long before an incident exists.
For example:
In all these cases, the system may not be “broken” yet.
But it is behaving differently from normal.
For an AI model, that alone is already a valuable signal.
The key is that the model does not need a full outage to learn.
It only needs to recognize:
When something moves too far outside that framework, it flags it as anomalous.
That is why anomaly detection works especially well in modern monitoring: many incidents do not begin with visible errors, but with small deviations that only make sense when analyzed in context.
Most Common Algorithms: Statistical Models, Classical Machine Learning, and Deep Learning
There is no single magical algorithm for anomaly detection.
In practice, modern platforms combine multiple techniques depending on:
Advanced Statistical Models
Statistical approaches remain highly relevant, especially when working with structured metrics and relatively stable time series.
Common techniques include:
These models are critical because they predict the next expected value in a time series (latency, throughput, etc.).
Anomalies are detected by measuring the deviation between the real value and the prediction (the residual).
The core logic is:
For example:
If an API’s average latency usually stays between 120 and 180 ms with known variance, a sustained increase to 260 ms can already be marked as anomalous, even if it has not yet crossed a manual threshold of 500 ms.
Advantages
Disadvantages
Classical Machine Learning
As systems become more complex, classical machine learning algorithms become useful.
Examples include:
These models learn what normal behavior looks like and identify points that appear far away from it.
Clustering
Clustering groups similar behaviors together.
If most data falls inside known normal groups and a new behavior appears outside those groups, it is considered suspicious.
In monitoring, clustering helps identify operational patterns and detect behaviors that do not fit historical norms.
Isolation Forest
Isolation Forest is one of the most popular anomaly detection algorithms because it performs well with large datasets.
The intuition behind it is simple:
Common points require many splits to isolate.
Rare points become isolated very quickly.
This enables the model to identify unusual observations without needing explicit examples of failures.
It is especially useful when dealing with multiple dimensions such as:
Deep Learning
When system behavior becomes highly dynamic and complex, deep learning models become more effective.
Common approaches include:
Autoencoders
Autoencoders learn to reconstruct normal patterns.
They are trained on healthy data and learn how to compress and reconstruct that normality.
When they receive something different, reconstruction quality degrades.
That difference becomes the anomaly signal.
In essence, the system says:
LSTM and Sequential Models
LSTM models capture long-term temporal dependencies.
This matters because not only the current value matters, but also the sequence leading to it.
For example:
A latency of 300 ms may be perfectly normal at a certain time of day, but anomalous if preceded by saturation, jitter, and intermittent errors.
LSTM and RNNs are particularly useful for:
Detection Through Patterns, Trends, Seasonality, and Noise
One of AI’s biggest strengths in monitoring is that it does not only analyze isolated values.
It analyzes behavior.
Patterns
The system learns which signals usually appear together.
For example:
It may recognize that a certain traffic level combined with specific latency and cache usage is normal during peak hours, but suspicious during the middle of the night.
Trends
Metrics do not need to explode.
A slow, sustained increase may be more important than a single spike.
AI can detect:
Seasonality
Many systems have:
patterns.
A Monday morning behaves differently than a Saturday night.
Modern models incorporate seasonality to avoid false alarms caused by expected behavior.
Noise
Every signal contains noise.
Not every small change matters.
AI attempts to distinguish between:
This capability is critical for reducing false positives.
Advantages Over Static Thresholds
Static thresholds have three major limitations:
AI improves this by working with:
Key Advantages
Thresholds still remain useful as safety nets.
But AI enables a shift from reactive monitoring to preventive monitoring.
Real Examples of Anomalies Detected Before Incidents
Case 1: Payment API Degradation
A payment API usually has a p95 latency of 220 ms.
During a campaign:
The error rate remains low.
A traditional alert never fires.
AI, however, detects the deviation and allows teams to act before massive timeouts occur.
Case 2: Intermittent Checkout Errors
Checkout works for most users, but fails for 1% of them.
The average looks healthy.
However, AI detects anomalies in:
Case 3: Progressive Database Saturation
CPU has not reached its limit.
Connections are still available.
But query time variability changes significantly.
A statistical model or Isolation Forest detects the anomaly before collapse occurs.
Case 4: Memory Leak in a Microservice
The service is still responding.
No visible outage exists.
But:
A sequential model detects the pattern before the issue becomes visible to users.
How UptimeBolt Applies These Techniques
UptimeBolt combines several of these techniques to build a more predictive and actionable monitoring layer.
The platform:
Capabilities
The goal is not to replace traditional monitoring.
It is to radically improve it.
Where a traditional system says:
UptimeBolt aims to say:
That operational shift reduces:
Conclusion
AI-powered monitoring is not magic or an incomprehensible black box.
Behind it are concrete algorithm families:
All of them aim toward the same core idea:
Understanding how these models work helps teams trust them.
You do not need to become an expert in every algorithm.
But it is important to understand that anomaly detection relies on:
And in modern monitoring, that makes the difference between reacting too late and acting proactively.
Integrating AI-based anomaly detection is a critical step toward: