Web traffic spikes on online education platforms represent one of the most demanding scenarios for any digital system. Unlike other industries, in EdTech these spikes are neither optional nor gradual: they occur at very specific and critical moments such as final exams, midterms, enrollment periods, or mandatory assignment submissions. If the platform fails at that moment, the impact is not only technical, but academic, reputational, and in many cases contractual.
For education platform leaders, EdTech CTOs, and DevOps teams, the challenge is not just handling more users, but guaranteeing stability, fairness, and service continuity when thousands of students depend on the system at the same time. In this article, we analyze why web traffic spikes are so dangerous in online education and how to prevent failures through advanced monitoring, synthetic monitoring, and incident prediction.
In EdTech, web traffic spikes are not random. They concentrate in very specific time windows:
- Start of online exams
- Mass access to timed assessments
- Simultaneous publication of results
- Enrollment or re-enrollment periods
- Final assignment submissions
During these moments, system behavior changes dramatically. Thousands—or tens of thousands—of users execute the same critical flows at the same time, generating extreme pressure on key platform components.
In practice, when the architecture is not designed for this type of concentrated concurrency, well-known technical failures begin to appear for DevOps and SRE teams:
- Thread Pool Exhaustion in authentication or exam validation services, preventing new requests even when the infrastructure is technically “up.”
- Connection Pool Overload in databases or identity services, causing timeouts and intermittent errors that are difficult to reproduce.
- Cascading failures when a slow service blocks other synchronous components that depend on it.
- Saturated or poorly sized queues in grading processes, answer storage, or result generation.
- Overly synchronous architectures, where every step of the flow (login → exam load → answer submission → validation) depends on the previous one, amplifying any latency.
The result is that many education platforms operate correctly for most of the year, but collapse under highly concentrated loads—exactly when tolerance for failure is zero. In these scenarios, an event-driven architecture with decoupled queues, controlled backpressure, and asynchronous processing stops being a “nice to have” and becomes a basic reliability requirement.
When these principles are missing, the system becomes fragile precisely at the moments when stability and predictability matter most: exam periods.
Unlike other industries, a failure in online education is not just an inconvenience. It can lead to:
- Students unable to take an exam
- Incomplete or lost assessments
- Massive complaints and loss of trust
- Legal or contractual issues
- Severe damage to institutional reputation
Additionally, web traffic spikes in EdTech are usually synchronized. They do not ramp up gradually; they explode within seconds when an exam or assessment becomes available.
To prevent failures during web traffic spikes, it is not enough to know which components are critical—it is essential to understand which metrics (SLIs) must be actively monitored as load increases.
Thousands of students trying to log in simultaneously often saturate identity services, token issuance, session validation, or external authentication providers.
Recommended SLIs to monitor:
- Authentication service latency p95 / p99 > 500 ms
- Error rate (4xx / 5xx) > 1%
- Token issuance failures or abnormal retries
- Thread pool utilization or request queue depth
These indicators typically degrade minutes before users start reporting login issues.
The simultaneous loading of content, questions, PDFs, or multimedia resources can create bottlenecks in backend services and databases.
Recommended SLIs to monitor:
- Response time p95 / p99 on course-loading endpoints
- Cache hit ratio (sudden drops indicate database pressure)
- Per-service throughput vs. historical baseline
- Error rate on content endpoints
Degradation here often manifests as long load times or blank screens, even if the system remains technically “up.”
Services that record answers, timing, attempts, and results are highly transactional and extremely sensitive to latency.
Recommended SLIs to monitor:
- Write latency p95 / p99 on answer submission endpoints
- Timeout rate or automatic retries
- Queue backlog if processing is asynchronous
- Success rate of persistence operations
A small latency increase can trigger cascading retries and answer loss if not detected early.
Although they do not always coincide with exams, web traffic spikes also impact live classes and on-demand content, especially when they overlap with assessments.
Recommended SLIs to monitor:
- Stream startup time (time to first frame)
- Buffering ratio or rebuffer events
- Error rate in CDN or media services
- Bandwidth utilization vs. contracted capacity
These issues directly affect user experience, even if the rest of the platform appears stable.
Databases are often the final bottleneck during web traffic spikes, especially when they handle heavy write workloads.
Recommended SLIs to monitor:
- Connection pool utilization > 80%
- Maximum query latency (especially on results or session tables)
- Lock wait time or deadlocks
- Replication lag (if applicable)
When these metrics degrade, the impact usually propagates rapidly across the entire platform.
One of the most common mistakes in EdTech is reacting only when the system is already failing. To handle web traffic spikes effectively, anticipation is key.
Exam periods are predictable. Analyzing data from previous years or academic cycles helps estimate load and identify trends.
Before a full outage, early signals often appear, such as:
- Gradual increases in latency
- Intermittent errors
- Slower responses in critical APIs
Detecting these signals early allows teams to act before the spike reaches its peak.
Static thresholds often fail in EdTech because traffic baselines are highly variable, making AI-based anomaly detection essential.
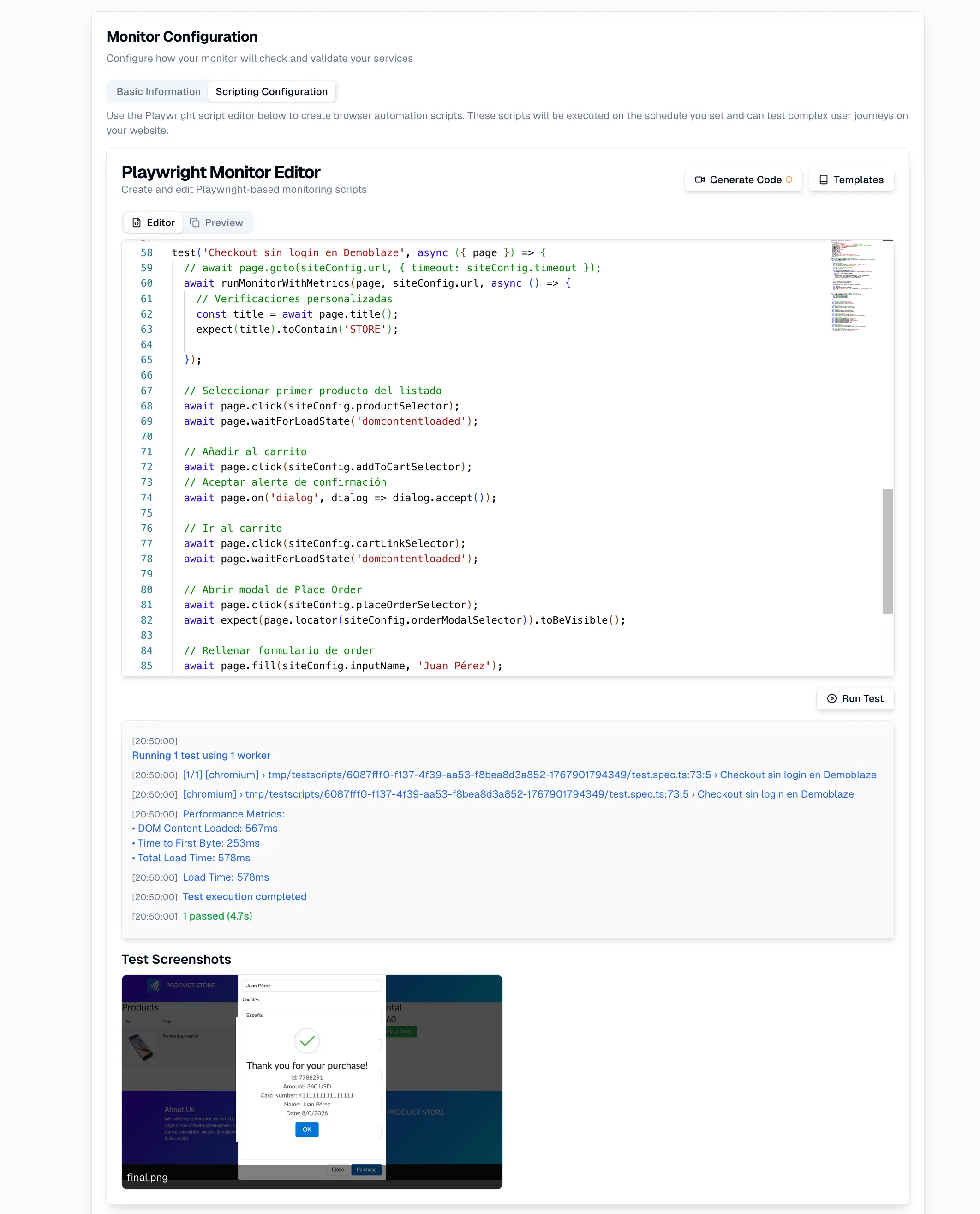
Synthetic monitoring is one of the most effective tools for handling web traffic spikes in online education.
This type of monitoring simulates users executing critical flows such as:
- Login
- Course access
- Assessment loading
- Answer submission
- Submission confirmation
Synthetic monitoring does not measure real user behavior (that is the role of RUM); instead, it validates real system behavior by simulating users in a controlled and continuous way.
This makes it possible to detect:
- Broken flows even when the platform is “online”
- Logical errors that do not trigger traditional alerts
- Progressive degradation under load
During web traffic spikes, continuous validation is key to ensuring fairness and stability.
In EdTech, many critical functions depend on internal and external APIs. During web traffic spikes, these APIs are often the first saturation point.
Monitoring should focus on:
- Latency of assessment APIs
- Timeouts and intermittent errors
- Response content, not just HTTP status codes
Databases also require special attention. Increased concurrent writes during exams can cause locks and silent degradations that only proper monitoring can detect.
Scaling does not simply mean adding more resources. During poorly managed web traffic spikes, scaling can even make things worse.
Best practices include:
- Scaling based on real metrics, not just CPU
- Predictive autoscaling based on the academic calendar
- Effective caching for static content
- Separation of read and write workloads
- Load testing before critical periods
Advanced monitoring helps validate that scaling actually improves user experience instead of introducing new issues.
In online education, system stability is directly tied to perceptions of fairness and reliability. A student who cannot take an exam due to a technical failure does not see a “system error,” but an injustice.
Protecting stability during web traffic spikes therefore also means protecting institutional credibility.
UptimeBolt is designed to help education platforms anticipate and manage web traffic spikes proactively.
The platform enables:
- Synthetic monitoring of critical flows such as login and exams
- Monitoring of APIs and key dependencies
- AI-based anomaly detection
- Incident prediction ahead of critical periods
- Intelligent alerts with clear, actionable context
With this approach, teams can identify risks before students are affected and act with enough lead time.
If you want to prepare your education platform for exam periods and avoid failures during web traffic spikes, sign up and get a free trial.
In online education, web traffic spikes are not an exception—they are a normal part of the business. The difference between a reliable platform and a problematic one lies in how it prepares for these critical moments.
Anticipating saturation, validating flows with synthetic monitoring, monitoring APIs and databases, and leveraging artificial intelligence to prevent incidents ensures stability when it matters most.
Because, ultimately, during exam periods, system stability defines the reputation of the entire education platform.
Web traffic spikes on online education platforms represent one of the most demanding scenarios for any digital system. Unlike other industries, in EdTech these spikes are neither optional nor gradual: they occur at very specific and critical moments such as final exams, midterms, enrollment periods, or mandatory assignment submissions. If the platform fails at that moment, the impact is not only technical, but academic, reputational, and in many cases contractual.
For education platform leaders, EdTech CTOs, and DevOps teams, the challenge is not just handling more users, but guaranteeing stability, fairness, and service continuity when thousands of students depend on the system at the same time. In this article, we analyze why web traffic spikes are so dangerous in online education and how to prevent failures through advanced monitoring, synthetic monitoring, and incident prediction.
The extreme stress of exam periods
In EdTech, web traffic spikes are not random. They concentrate in very specific time windows:
During these moments, system behavior changes dramatically. Thousands—or tens of thousands—of users execute the same critical flows at the same time, generating extreme pressure on key platform components.
In practice, when the architecture is not designed for this type of concentrated concurrency, well-known technical failures begin to appear for DevOps and SRE teams:
The result is that many education platforms operate correctly for most of the year, but collapse under highly concentrated loads—exactly when tolerance for failure is zero. In these scenarios, an event-driven architecture with decoupled queues, controlled backpressure, and asynchronous processing stops being a “nice to have” and becomes a basic reliability requirement.
When these principles are missing, the system becomes fragile precisely at the moments when stability and predictability matter most: exam periods.
Why web traffic spikes are especially critical in EdTech
Unlike other industries, a failure in online education is not just an inconvenience. It can lead to:
Additionally, web traffic spikes in EdTech are usually synchronized. They do not ramp up gradually; they explode within seconds when an exam or assessment becomes available.
Critical failure points in education platforms
To prevent failures during web traffic spikes, it is not enough to know which components are critical—it is essential to understand which metrics (SLIs) must be actively monitored as load increases.
Login and authentication
Thousands of students trying to log in simultaneously often saturate identity services, token issuance, session validation, or external authentication providers.
Recommended SLIs to monitor:
These indicators typically degrade minutes before users start reporting login issues.
Course and assessment access
The simultaneous loading of content, questions, PDFs, or multimedia resources can create bottlenecks in backend services and databases.
Recommended SLIs to monitor:
Degradation here often manifests as long load times or blank screens, even if the system remains technically “up.”
Assessment APIs
Services that record answers, timing, attempts, and results are highly transactional and extremely sensitive to latency.
Recommended SLIs to monitor:
A small latency increase can trigger cascading retries and answer loss if not detected early.
Live classes and streaming
Although they do not always coincide with exams, web traffic spikes also impact live classes and on-demand content, especially when they overlap with assessments.
Recommended SLIs to monitor:
These issues directly affect user experience, even if the rest of the platform appears stable.
Databases
Databases are often the final bottleneck during web traffic spikes, especially when they handle heavy write workloads.
Recommended SLIs to monitor:
When these metrics degrade, the impact usually propagates rapidly across the entire platform.
How to anticipate saturation before traffic explodes
One of the most common mistakes in EdTech is reacting only when the system is already failing. To handle web traffic spikes effectively, anticipation is key.
Historical pattern analysis
Exam periods are predictable. Analyzing data from previous years or academic cycles helps estimate load and identify trends.
Early degradation detection
Before a full outage, early signals often appear, such as:
Detecting these signals early allows teams to act before the spike reaches its peak.
Static thresholds often fail in EdTech because traffic baselines are highly variable, making AI-based anomaly detection essential.
Synthetic monitoring to validate access, courses, and exams
Synthetic monitoring is one of the most effective tools for handling web traffic spikes in online education.
This type of monitoring simulates users executing critical flows such as:
Synthetic monitoring does not measure real user behavior (that is the role of RUM); instead, it validates real system behavior by simulating users in a controlled and continuous way.
This makes it possible to detect:
During web traffic spikes, continuous validation is key to ensuring fairness and stability.
API and database monitoring during critical periods
In EdTech, many critical functions depend on internal and external APIs. During web traffic spikes, these APIs are often the first saturation point.
Monitoring should focus on:
Databases also require special attention. Increased concurrent writes during exams can cause locks and silent degradations that only proper monitoring can detect.
How to scale education services without degradation
Scaling does not simply mean adding more resources. During poorly managed web traffic spikes, scaling can even make things worse.
Best practices include:
Advanced monitoring helps validate that scaling actually improves user experience instead of introducing new issues.
The relationship between stability and academic trust
In online education, system stability is directly tied to perceptions of fairness and reliability. A student who cannot take an exam due to a technical failure does not see a “system error,” but an injustice.
Protecting stability during web traffic spikes therefore also means protecting institutional credibility.
How UptimeBolt helps prevent failures in EdTech
UptimeBolt is designed to help education platforms anticipate and manage web traffic spikes proactively.
The platform enables:
With this approach, teams can identify risks before students are affected and act with enough lead time.
If you want to prepare your education platform for exam periods and avoid failures during web traffic spikes, sign up and get a free trial.
Conclusion: exam stability defines platform reputation
In online education, web traffic spikes are not an exception—they are a normal part of the business. The difference between a reliable platform and a problematic one lies in how it prepares for these critical moments.
Anticipating saturation, validating flows with synthetic monitoring, monitoring APIs and databases, and leveraging artificial intelligence to prevent incidents ensures stability when it matters most.
Because, ultimately, during exam periods, system stability defines the reputation of the entire education platform.