Reducing MTTR is one of the biggest challenges for modern technology teams. MTTR (Mean Time to Recovery) measures how long an organization takes to restore a service after an incident, and its impact goes far beyond the technical domain: it directly affects SLAs, user experience, operational costs, and business reputation.
In complex digital environments, where architectures are distributed, services rely on multiple APIs, and systems change constantly, reducing MTTR with traditional methods is becoming increasingly difficult. This is where artificial intelligence (AI) becomes a decisive factor. This article explores how AI enables a drastic reduction in MTTR, transforming the way teams detect, understand, and resolve incidents.
For years, many organizations focused almost exclusively on uptime. However, today it is understood that availability alone does not tell the full story. Incidents happen, even in the best infrastructures; what truly makes the difference is how quickly you can recover.
A high MTTR implies:
- More time with users affected
- Higher risk of SLA breaches
- Increase in support tickets
- Loss of revenue and trust
On the other hand, reducing MTTR means more resilient systems and more efficient teams. In this context, reducing MTTR is no longer just a technical goal, but a strategic priority for CTOs, SRE leaders, and operational continuity owners.
Before understanding how AI helps reduce MTTR, it’s important to identify what increases it in the first place. In modern infrastructures, these are the most common factors.
The more services interact with each other, the harder it is to identify where a problem originated. A failure in one microservice can quickly propagate and generate symptoms across multiple components.
Third-party APIs, payment gateways, authentication services, or external integrations are often black boxes. When they fail or degrade, manual diagnosis becomes slow and imprecise.
Many alerts indicate what is failing, but not why. Without context, teams waste time investigating isolated signals.
An excess of irrelevant alerts overwhelms teams, delays response, and increases the time it takes to identify the real incident.
Manually reviewing logs, metrics, and dashboards consumes critical time during an incident. Every minute spent “searching for the cause” increases MTTR.
These factors make reducing MTTR with traditional approaches increasingly complex.
To understand how AI helps reduce MTTR, it’s useful to analyze the full incident resolution cycle:
detect → understand → resolve
Artificial intelligence has a direct impact on each of these stages.
AI makes it possible to identify weak signals before a visible incident occurs. By anticipating potential failures, teams can act before the system collapses, drastically reducing recovery time.
AI-based anomaly detection identifies unusual behaviors that do not match the system’s normal patterns. These anomalies often appear well before a full outage, providing time to intervene.
Instead of analyzing isolated alerts, AI correlates events, metrics, and anomalies across multiple services. This makes it possible to quickly understand which events are related and which are merely side effects.
This trio—prediction, anomalies, and correlation—transforms MTTR by reducing time lost in detection and diagnosis.
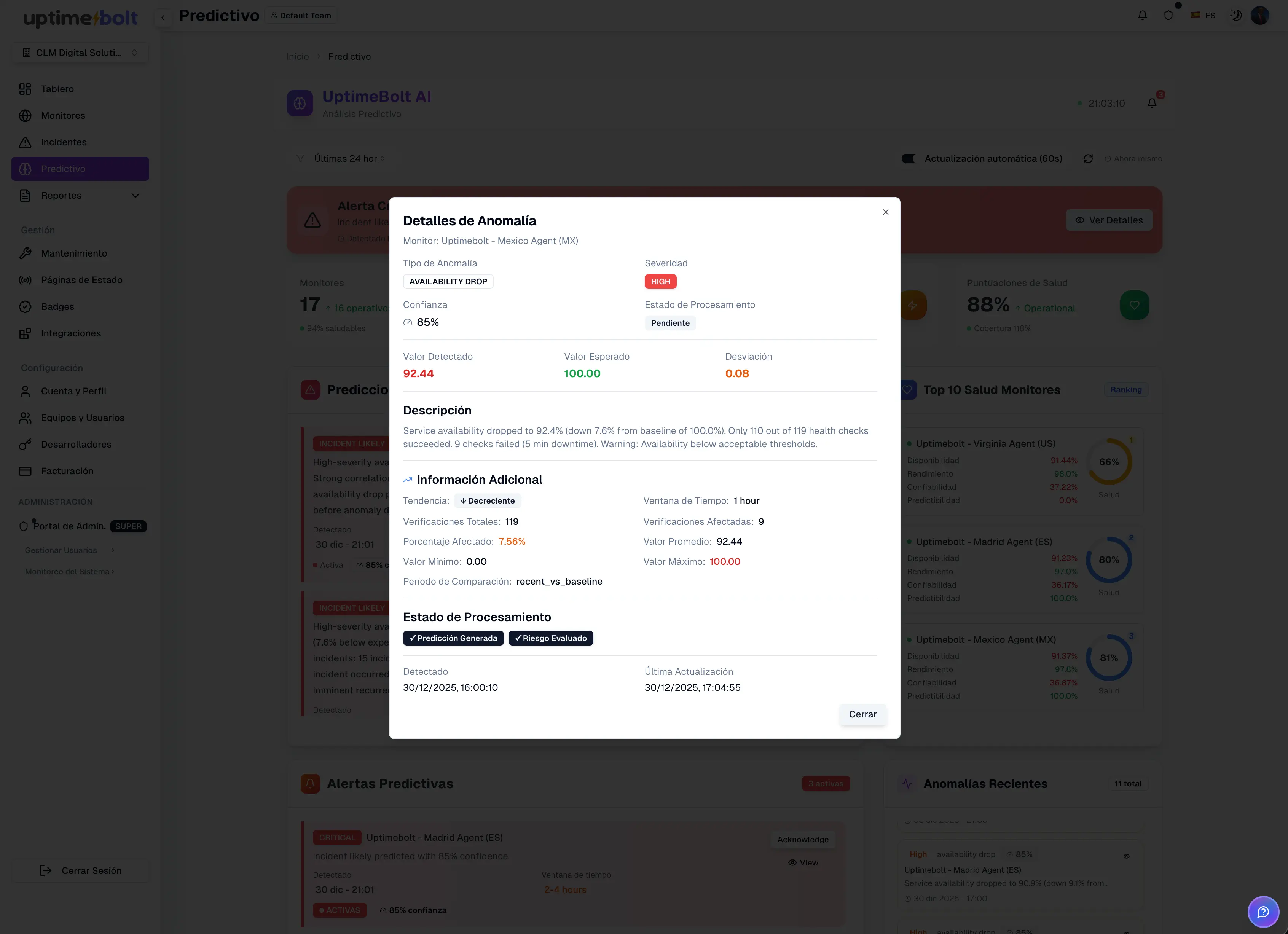
In the traditional model, detection occurs when a threshold is breached or a service goes down. At that point, the impact is already visible to users.
With AI, detection happens earlier:
- Progressive performance degradation
- Anomalous increases in latency
- Irregular traffic patterns
- Atypical behavior in APIs or databases
By detecting these early signals, AI enables corrective actions before the incident escalates, reducing MTTR—even to zero in some cases.
Historically, diagnosis is the most time-consuming phase during an incident.
Reducing MTTR is one of the biggest challenges for modern technology teams. MTTR (Mean Time to Recovery) measures how long an organization takes to restore a service after an incident, and its impact goes far beyond the technical domain: it directly affects SLAs, user experience, operational costs, and business reputation.
In complex digital environments, where architectures are distributed, services rely on multiple APIs, and systems change constantly, reducing MTTR with traditional methods is becoming increasingly difficult. This is where artificial intelligence (AI) becomes a decisive factor. This article explores how AI enables a drastic reduction in MTTR, transforming the way teams detect, understand, and resolve incidents.
Introduction: why MTTR is a critical metric for modern teams
For years, many organizations focused almost exclusively on uptime. However, today it is understood that availability alone does not tell the full story. Incidents happen, even in the best infrastructures; what truly makes the difference is how quickly you can recover.
A high MTTR implies:
On the other hand, reducing MTTR means more resilient systems and more efficient teams. In this context, reducing MTTR is no longer just a technical goal, but a strategic priority for CTOs, SRE leaders, and operational continuity owners.
Factors that increase MTTR in complex infrastructures
Before understanding how AI helps reduce MTTR, it’s important to identify what increases it in the first place. In modern infrastructures, these are the most common factors.
Distributed architectures and microservices
The more services interact with each other, the harder it is to identify where a problem originated. A failure in one microservice can quickly propagate and generate symptoms across multiple components.
External dependencies
Third-party APIs, payment gateways, authentication services, or external integrations are often black boxes. When they fail or degrade, manual diagnosis becomes slow and imprecise.
Lack of context in alerts
Many alerts indicate what is failing, but not why. Without context, teams waste time investigating isolated signals.
Alert fatigue
An excess of irrelevant alerts overwhelms teams, delays response, and increases the time it takes to identify the real incident.
Manual diagnosis
Manually reviewing logs, metrics, and dashboards consumes critical time during an incident. Every minute spent “searching for the cause” increases MTTR.
These factors make reducing MTTR with traditional approaches increasingly complex.
How AI impacts each stage of the resolution cycle
To understand how AI helps reduce MTTR, it’s useful to analyze the full incident resolution cycle:
detect → understand → resolve
Artificial intelligence has a direct impact on each of these stages.
Prediction, anomalies, and correlation: the trio that reduces MTTR
Early detection through incident prediction
AI makes it possible to identify weak signals before a visible incident occurs. By anticipating potential failures, teams can act before the system collapses, drastically reducing recovery time.
Anomaly detection
AI-based anomaly detection identifies unusual behaviors that do not match the system’s normal patterns. These anomalies often appear well before a full outage, providing time to intervene.
Intelligent event correlation
Instead of analyzing isolated alerts, AI correlates events, metrics, and anomalies across multiple services. This makes it possible to quickly understand which events are related and which are merely side effects.
This trio—prediction, anomalies, and correlation—transforms MTTR by reducing time lost in detection and diagnosis.
How AI reduces MTTR during the detection phase
In the traditional model, detection occurs when a threshold is breached or a service goes down. At that point, the impact is already visible to users.
With AI, detection happens earlier:
By detecting these early signals, AI enables corrective actions before the incident escalates, reducing MTTR—even to zero in some cases.
How AI accelerates diagnosis and reduces MTTR
Historically, diagnosis is the most time-consuming phase during an incident.