Root cause analysis is one of the most critical processes in modern IT operations.
After every incident, service outage, or performance degradation, the key question is: what was the root cause?
In simple infrastructures, answering this question was relatively straightforward. Today, with distributed architectures, microservices, APIs, multi-cloud environments, and external dependencies, traditional root cause analysis has become slow, manual, and often ineffective.
In this context, AI-powered root cause analysis emerges as the natural evolution of incident diagnostics. This article compares both approaches, explains their real differences, analyzes their limitations, and shows how AI enables a drastic reduction in MTTR, improves SLAs, and increases operational stability.
A few years ago, root cause analysis consisted of reviewing logs, observing isolated metrics, and mentally reconstructing the sequence of events that led to an incident. The process relied heavily on the engineer’s experience and the time available.
Today, that approach no longer scales. Modern applications generate thousands of metrics per second, distributed events across multiple services, and non-linear behaviors that are difficult to interpret manually. In this scenario, traditional root cause analysis often responds too late, when the damage has already been done.
The current challenge is not only finding the root cause, but doing so quickly, with context, and in a repeatable way. This is where AI completely transforms root cause analysis.
Traditional root cause analysis generally follows a sequence like this:
- An incident occurs
- An alert is received
- The team reviews metrics and logs
- Hypotheses are formulated
- Possible causes are tested
- A root cause is identified (or assumed)
This process can take minutes, hours, or even days, depending on system complexity.
The classic root cause analysis approach is based on:
- Manual log analysis
- Dashboard reviews
- Visual historical comparison
- Communication across multiple teams
- Prior experience of personnel
While this method may work in small systems, it presents serious problems in modern environments.
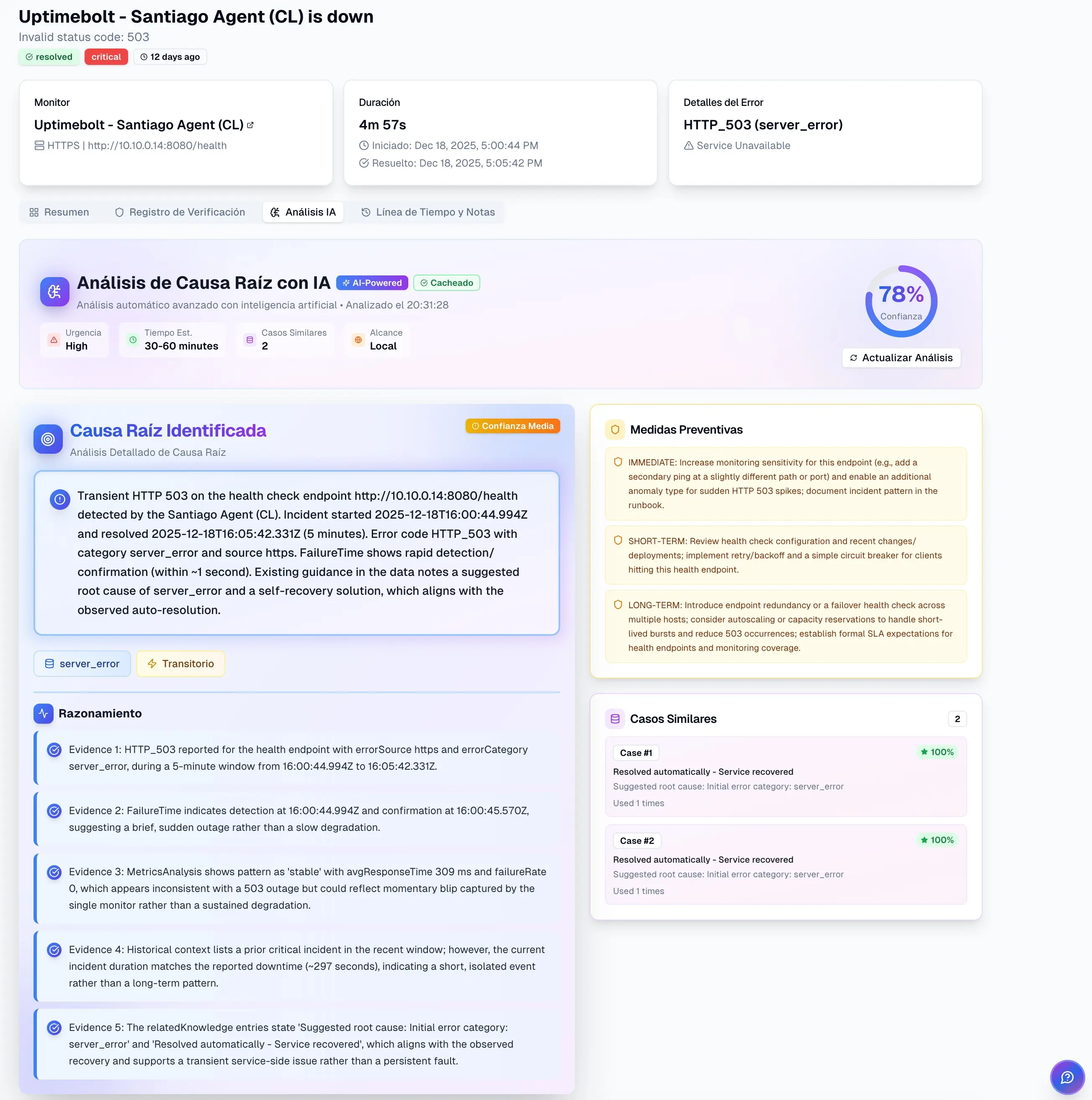
Traditional root cause analysis does not fail due to lack of intent, but because of structural limitations.
Manual investigation consumes valuable time while the system remains degraded or down. Every additional minute increases the impact on users and the business.
Two engineers can reach different conclusions when analyzing the same incident. Root cause analysis depends too heavily on human judgment.
The classic approach analyzes metrics in isolation, without automatically correlating events across services, APIs, databases, and end-to-end flows.
Often, the root cause is not where the symptom is visible. Traditional root cause analysis frequently confuses effect with cause.
The direct consequence is a high MTTR, impacting SLAs, reputation, and operational costs.
These limitations explain why, even with good monitoring, incidents continue to occur and repeat.
AI-powered root cause analysis introduces a radical shift: instead of analyzing isolated signals, it automatically correlates large volumes of data to identify the most likely cause of a problem.
AI applied to root cause analysis is capable of:
- Correlating events across multiple layers of the system
- Analyzing metrics as time series
- Detecting hidden anomalies and patterns
- Understanding cause-and-effect relationships
- Prioritizing the most relevant cause
This enables a shift from “searching for the cause” to identifying it automatically and contextually.
The AI-powered root cause analysis process typically includes the following steps:
Metrics, logs, events, end-to-end flows, APIs, and databases are analyzed together.
AI identifies unusual behaviors that precede the incident.
Seemingly independent events are grouped based on temporal and causal relationships.
Current incidents are compared with past incidents to identify similarities.
The system proposes the root cause with the highest impact and probability.
Thanks to this approach, root cause analysis stops being reactive and becomes predictive and AI-assisted.
To understand the real impact of AI-powered root cause analysis, it’s useful to look at real-world scenarios where complexity makes manual analysis slow, imprecise, and costly.
An e-commerce platform experiences a sudden increase in checkout response time during a promotional campaign.
The site remains “up,” but users begin abandoning their carts. Initial metrics show:
- Increased latency in the checkout API
- Intermittent timeouts
- Apparently normal CPU usage
- No clear errors in main logs
The team receives multiple isolated alerts.
They review infrastructure dashboards, then checkout API logs, then databases.
Several hypotheses emerge: network issues, backend saturation, external dependencies.
Manual diagnosis takes more than 2 hours while conversion impact continues.
AI analyzes metrics, events, and anomalies together and automatically reconstructs the causal sequence:
- Detects a prior anomaly in the latency of a promotions microservice
- Correlates this event with an increase in synchronous database calls
- Identifies that a recent change activated a more expensive promotional rule under load
- Determines that this microservice is the root cause of the checkout bottleneck
The root cause is identified in less than 3 minutes.
The team disables the problematic rule, restores performance, and avoids a complete checkout failure.
Users report occasional login failures. The issue is not constant and does not affect all users.
Traditional monitors do not detect a clear outage.
The team reviews authentication logs and finds no consistent errors.
They suspect network issues, then credentials, then session handling.
The problem persists for days, impacting user experience.
AI detects an anomalous pattern in the response time of an external validation service.
It correlates this degradation with silent retries in the login flow and specific traffic spikes.
Historical analysis reveals that the issue appears only under certain load conditions.
The root cause—an external dependency degrading under concurrency—is quickly identified.
The team adjusts timeouts and adds a fallback, permanently eliminating the intermittent failure.
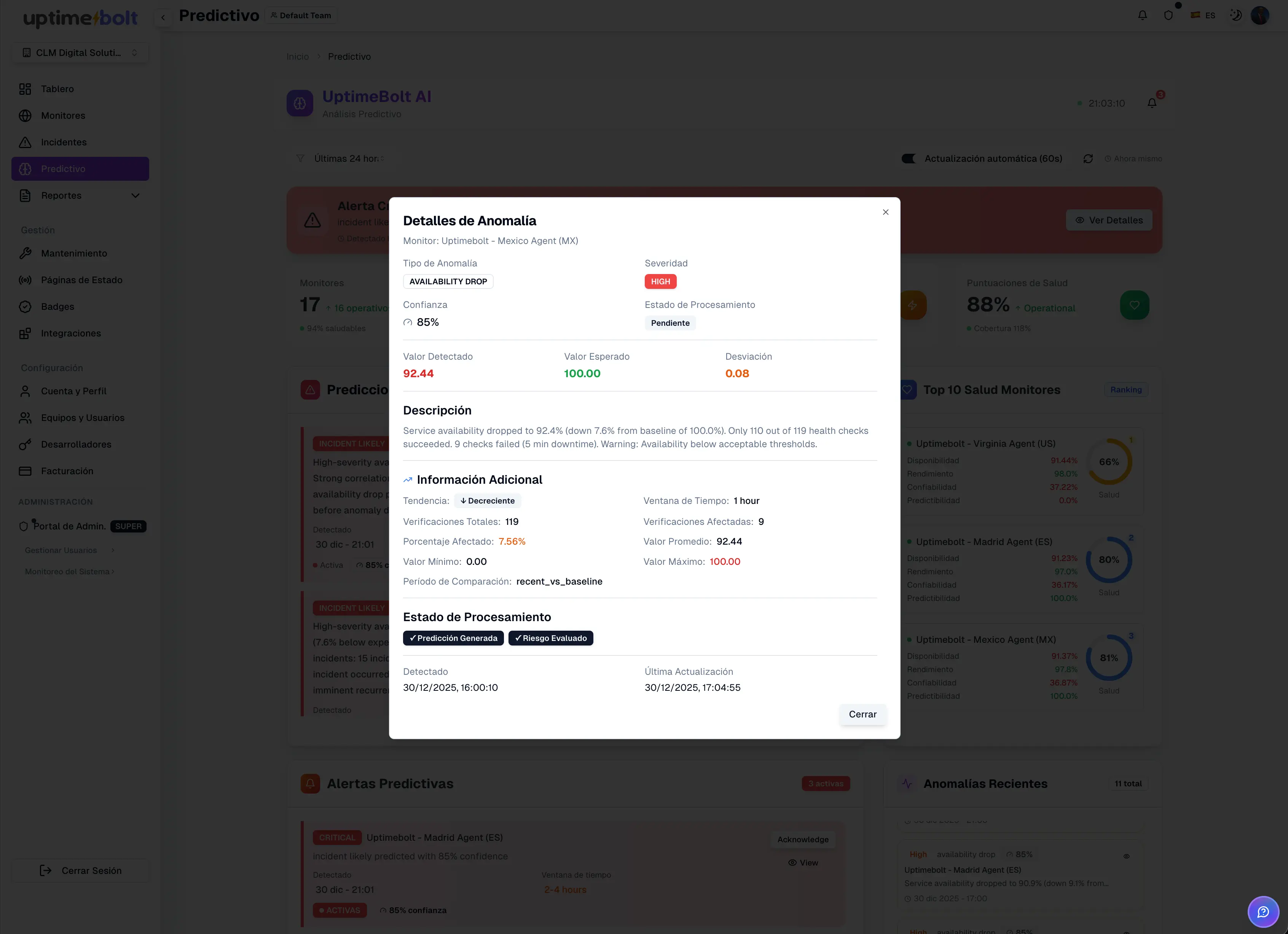
Adopting AI-driven root cause analysis delivers immediate and measurable benefits in any modern operational environment.
By identifying the root cause faster, teams reduce total resolution time and limit incident impact.
Less degradation time directly translates into better availability metrics and higher perceived reliability for customers and users.
Accurate root cause analysis enables permanent fixes instead of temporary patches, preventing repeated issues.
By reducing manual investigation and operational noise, engineers stop “fighting fires” and can focus on improving system architecture and resilience.
Corrective actions are based on real correlations, historical data, and objective patterns—not assumptions or intuition.
For these reasons, AI-powered root cause analysis is becoming an operational standard for advanced SRE and DevOps teams managing complex infrastructures.
The benefits above define what AI brings to incident analysis in general. The key difference lies in how a specific platform turns these capabilities into real operational actions.
UptimeBolt integrates predictive, AI-powered root cause analysis directly into its monitoring platform, enabling these benefits to be applied continuously and automatically in day-to-day operations.
With UptimeBolt, teams can:
- Automatically correlate metrics, events, and anomalies in a single context
- Analyze dependencies across services, APIs, and end-to-end flows
- Identify root causes while incidents are still in the degradation phase, not only after outages
- Drastically reduce MTTR by eliminating unnecessary manual investigation
- Provide clear, prioritized, and actionable context to technical teams
Additionally, UptimeBolt combines root cause analysis with anomaly detection and incident prediction, offering a complete and continuous view of the system:
what is happening, why it is happening, and what is likely to happen next.
This approach transforms incident analysis into a proactive, intelligent, and prevention-oriented process, rather than a reactive post-failure activity.
Root cause analysis can no longer rely solely on manual analysis and individual experience. Modern infrastructures are too complex, dynamic, and distributed for that approach.
AI-powered root cause analysis represents the natural evolution of operational diagnostics: faster, more accurate, and contextual. By correlating events, detecting patterns, and learning from historical behavior, AI enables teams to anticipate issues, resolve incidents more effectively, and build more resilient systems.
In a world where every minute of downtime matters, the future of root cause analysis is clear: autonomous, predictive, and powered by artificial intelligence.
If you want to try AI-powered Root Cause Analysis, sign up and get a free trial!
Root cause analysis is one of the most critical processes in modern IT operations.
After every incident, service outage, or performance degradation, the key question is: what was the root cause?
In simple infrastructures, answering this question was relatively straightforward. Today, with distributed architectures, microservices, APIs, multi-cloud environments, and external dependencies, traditional root cause analysis has become slow, manual, and often ineffective.
In this context, AI-powered root cause analysis emerges as the natural evolution of incident diagnostics. This article compares both approaches, explains their real differences, analyzes their limitations, and shows how AI enables a drastic reduction in MTTR, improves SLAs, and increases operational stability.
Introduction: the modern challenge of root cause analysis in complex infrastructures
A few years ago, root cause analysis consisted of reviewing logs, observing isolated metrics, and mentally reconstructing the sequence of events that led to an incident. The process relied heavily on the engineer’s experience and the time available.
Today, that approach no longer scales. Modern applications generate thousands of metrics per second, distributed events across multiple services, and non-linear behaviors that are difficult to interpret manually. In this scenario, traditional root cause analysis often responds too late, when the damage has already been done.
The current challenge is not only finding the root cause, but doing so quickly, with context, and in a repeatable way. This is where AI completely transforms root cause analysis.
Traditional RCA: how it works and why it’s no longer enough
Traditional root cause analysis generally follows a sequence like this:
This process can take minutes, hours, or even days, depending on system complexity.
How classic root cause analysis is performed
The classic root cause analysis approach is based on:
While this method may work in small systems, it presents serious problems in modern environments.
Limitations of traditional root cause analysis
Traditional root cause analysis does not fail due to lack of intent, but because of structural limitations.
Manual and slow processes
Manual investigation consumes valuable time while the system remains degraded or down. Every additional minute increases the impact on users and the business.
Subjectivity in diagnosis
Two engineers can reach different conclusions when analyzing the same incident. Root cause analysis depends too heavily on human judgment.
Lack of real correlation
The classic approach analyzes metrics in isolation, without automatically correlating events across services, APIs, databases, and end-to-end flows.
Difficulty detecting indirect causes
Often, the root cause is not where the symptom is visible. Traditional root cause analysis frequently confuses effect with cause.
High MTTR
The direct consequence is a high MTTR, impacting SLAs, reputation, and operational costs.
These limitations explain why, even with good monitoring, incidents continue to occur and repeat.
AI-powered Root Cause Analysis: event correlation, patterns, anomalies, and context
AI-powered root cause analysis introduces a radical shift: instead of analyzing isolated signals, it automatically correlates large volumes of data to identify the most likely cause of a problem.
What makes AI-powered root cause analysis different
AI applied to root cause analysis is capable of:
This enables a shift from “searching for the cause” to identifying it automatically and contextually.
How AI-driven root cause analysis works
The AI-powered root cause analysis process typically includes the following steps:
Massive data ingestion
Metrics, logs, events, end-to-end flows, APIs, and databases are analyzed together.
Anomaly detection
AI identifies unusual behaviors that precede the incident.
Automatic event correlation
Seemingly independent events are grouped based on temporal and causal relationships.
Historical pattern analysis
Current incidents are compared with past incidents to identify similarities.
Identification of the most likely root cause
The system proposes the root cause with the highest impact and probability.
Thanks to this approach, root cause analysis stops being reactive and becomes predictive and AI-assisted.
Practical cases: when AI identifies the root cause in minutes
To understand the real impact of AI-powered root cause analysis, it’s useful to look at real-world scenarios where complexity makes manual analysis slow, imprecise, and costly.
Case 1: critical latency in the checkout API during a traffic spike
Scenario
An e-commerce platform experiences a sudden increase in checkout response time during a promotional campaign.
The site remains “up,” but users begin abandoning their carts. Initial metrics show:
Traditional analysis
The team receives multiple isolated alerts.
They review infrastructure dashboards, then checkout API logs, then databases.
Several hypotheses emerge: network issues, backend saturation, external dependencies.
Manual diagnosis takes more than 2 hours while conversion impact continues.
AI-powered root cause analysis
AI analyzes metrics, events, and anomalies together and automatically reconstructs the causal sequence:
Result
The root cause is identified in less than 3 minutes.
The team disables the problematic rule, restores performance, and avoids a complete checkout failure.
Case 2: intermittent authentication failures with no visible errors
Scenario
Users report occasional login failures. The issue is not constant and does not affect all users.
Traditional monitors do not detect a clear outage.
Traditional analysis
The team reviews authentication logs and finds no consistent errors.
They suspect network issues, then credentials, then session handling.
The problem persists for days, impacting user experience.
AI-powered root cause analysis
AI detects an anomalous pattern in the response time of an external validation service.
It correlates this degradation with silent retries in the login flow and specific traffic spikes.
Historical analysis reveals that the issue appears only under certain load conditions.
Result
The root cause—an external dependency degrading under concurrency—is quickly identified.
The team adjusts timeouts and adds a fallback, permanently eliminating the intermittent failure.
Direct impact of AI-powered Root Cause Analysis: less wasted time, better SLAs, more stability
Adopting AI-driven root cause analysis delivers immediate and measurable benefits in any modern operational environment.
Significant MTTR reduction
By identifying the root cause faster, teams reduce total resolution time and limit incident impact.
Improved SLA compliance
Less degradation time directly translates into better availability metrics and higher perceived reliability for customers and users.
Fewer recurring incidents
Accurate root cause analysis enables permanent fixes instead of temporary patches, preventing repeated issues.
Lower operational burden on teams
By reducing manual investigation and operational noise, engineers stop “fighting fires” and can focus on improving system architecture and resilience.
Greater confidence in decision-making
Corrective actions are based on real correlations, historical data, and objective patterns—not assumptions or intuition.
For these reasons, AI-powered root cause analysis is becoming an operational standard for advanced SRE and DevOps teams managing complex infrastructures.
How UptimeBolt brings AI-powered Root Cause Analysis into practice
The benefits above define what AI brings to incident analysis in general. The key difference lies in how a specific platform turns these capabilities into real operational actions.
UptimeBolt integrates predictive, AI-powered root cause analysis directly into its monitoring platform, enabling these benefits to be applied continuously and automatically in day-to-day operations.
With UptimeBolt, teams can:
Additionally, UptimeBolt combines root cause analysis with anomaly detection and incident prediction, offering a complete and continuous view of the system:
what is happening, why it is happening, and what is likely to happen next.
This approach transforms incident analysis into a proactive, intelligent, and prevention-oriented process, rather than a reactive post-failure activity.
Conclusion: the future of operational diagnostics is autonomous and predictive
Root cause analysis can no longer rely solely on manual analysis and individual experience. Modern infrastructures are too complex, dynamic, and distributed for that approach.
AI-powered root cause analysis represents the natural evolution of operational diagnostics: faster, more accurate, and contextual. By correlating events, detecting patterns, and learning from historical behavior, AI enables teams to anticipate issues, resolve incidents more effectively, and build more resilient systems.
In a world where every minute of downtime matters, the future of root cause analysis is clear: autonomous, predictive, and powered by artificial intelligence.
If you want to try AI-powered Root Cause Analysis, sign up and get a free trial!