For years, monitoring has been presented as the primary line of defense to ensure the stability of critical systems. Well-configured dashboards, key metrics under control, alerts running 24/7. Everything suggests that with enough visibility, major incidents should be preventable.
The reality is different.
Every year, critical platforms in e-commerce, fintech, healthcare, and cloud experience major outages despite having “properly configured” monitoring. According to Gartner, the average cost of downtime for large enterprises can exceed $300,000 per hour, amplifying an uncomfortable paradox for CTOs and SRE leaders: how is it possible that systems with strong observability still fail in such costly ways?
The answer is not that monitoring is useless, but that traditional monitoring has structural limits when facing modern complexity. Understanding these limitations—and how to overcome them—is key to building true digital resilience.
Below, we explore the false sense of security created by “good monitoring,” analyze why critical systems continue to fail, and explain how artificial intelligence closes the gaps that traditional approaches cannot address.
In many organizations, monitoring is evaluated based on technical coverage:
- Do we have CPU, memory, and network metrics?
- Are APIs monitored?
- Do we have alerts configured for errors?
- Do we have distributed tracing coverage?
If the answer is “yes,” the system is assumed to be protected.
The problem is that most critical incidents do not start with a clear signal, nor do they meet the exact conditions that trigger an alert. They begin as subtle anomalies, slow degradations, or combinations of factors that, in isolation, seem harmless.
This creates a dangerous illusion: the system “looks fine” on dashboards… until it suddenly doesn’t.
Traditional monitoring is based on explicit rules:
“If X exceeds Y, trigger an alert.”
But many real incidents:
- Do not exceed fixed thresholds
- Do so too late
- Or occur in dimensions that are not being measured
- Latency that increases slowly but never crosses the threshold
- Intermittent errors of 0.5–1% that consume the entire error budget (SLO) in minutes, but do not trigger traditional alerts due to total volume
- Progressive saturation that accelerates non-linearly
- Services that are “up” but stop processing events
In hindsight, the data was there. The problem is that no one was looking at the right signal, at the right time.
Modern critical systems don’t fail only due to internal issues. They fail due to complex interactions between multiple components, many of which are outside the team’s direct control.
Payments, authentication, data providers, third-party services. A small degradation in any of these can:
- Increase latency
- Generate timeouts
- Trigger cascading failures
Traditional monitoring often treats these dependencies as “black boxes.”
In a monolith, failures are usually obvious. In microservices:
- One service may partially fail
- Another may temporarily compensate
- The impact accumulates in non-obvious ways
The result is a system that “works,” but performs worse and worse until it collapses.
Workers, cron jobs, consumers, and internal processes can stop running without generating visible errors. From the outside, everything appears normal.
These are some of the most costly failures because they do not trigger traditional alerts.
This is one of the biggest operational pain points—and paradoxically, one of the least addressed.
Industry studies (including reports from Google SRE and Atlassian) indicate that between 30% and 40% of alerts in SRE teams are false positives or low-value. In some environments, this can exceed 50%.
- Teams become conditioned to ignore alerts
- Sensitivity to real signals is lost
- Response times increase
- Stress and team turnover rise
In this context, monitoring stops being helpful and becomes noise.
A system can “have monitoring” and still fail because important signals are lost in a sea of irrelevant alerts.
To understand the magnitude of the problem, it’s enough to review some widely documented incidents.
In multiple AWS outages, postmortems revealed:
- Metrics were available
- Alerts were functioning
- But interactions between services were not anticipated
Monitoring detected the failure when it was already happening, but did not anticipate the cascading impact.
In Cloudflare incidents, the issue was not lack of data, but:
- Configuration changes
- Unexpected behaviors
- Early signals that appeared normal
The system was monitored, but risk patterns were not evident without advanced analysis.
Facebook’s global outage was caused by changes in BGP and DNS. Internal monitoring worked, but:
- Critical dependencies were out of reach
- The impact was rapid and massive
These failures were not due to lack of data, but lack of context and correlation at scale. This is the critical gap that AI is designed to close.
This is where artificial intelligence changes the paradigm.
AI does not replace monitoring—it extracts value from existing data, identifying patterns that humans and rule-based systems cannot detect in time.
AI doesn’t just ask “Is this wrong?”, but:
“Is this normal for this system, in this context, at this moment?”
This enables detection of:
- Subtle behavior changes
- Slow degradations
- Anomalous variability
Instead of analyzing isolated metrics, AI correlates:
- Performance
- Errors
- End-to-end flows
- External dependencies
This reduces false positives and increases precision.
By recognizing patterns preceding historical incidents, AI can alert hours before a problem materializes.
This is not about guessing—it’s about recognizing risk signals.
An e-commerce platform had well-configured alerts for latency and errors. However:
- p95 latency gradually increased
- It did not cross the threshold until peak traffic
Result: outage during the most critical moment of the day.
A 0.7% error rate in an API seemed irrelevant. In reality, it was breaking checkout for certain users. Monitoring did not alert; the business suffered the impact.
An internal process stopped running after a deployment. The system was “up.” The backlog grew for hours until it affected customers.
In all these cases, monitoring was present—but it wasn’t enough.
Overcoming these limitations requires a more mature approach.
The real user experience must be the reference point.
- Eliminate low-value alerts
- Prioritize real impact
- Use intelligence to filter noise
Static thresholds do not adapt to dynamic systems.
Modern resilience is built by acting early—not by constantly fighting fires.
UptimeBolt is designed to address precisely where traditional monitoring fails:
- Detects invisible anomalies
- Reduces operational noise
- Correlates technical and functional signals
- Anticipates incidents before impact
It doesn’t promise to eliminate all failures, but it drastically reduces their impact and frequency—transforming operations from reactive to preventive.
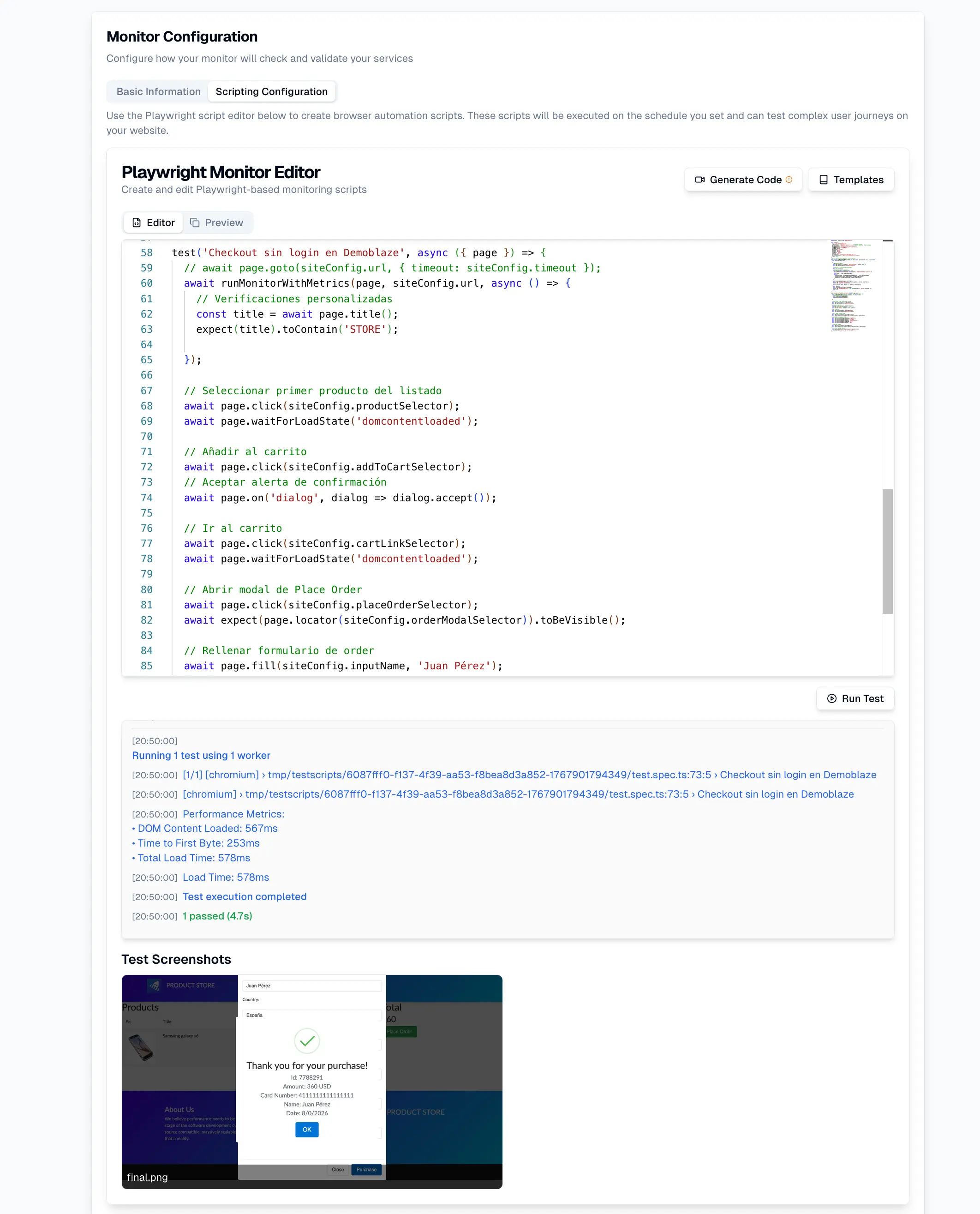
The biggest mistake today is not lacking monitoring—it’s believing that traditional monitoring is enough.
Critical systems fail because complexity exceeds human capacity to interpret signals in real time. The solution is not more dashboards or more alerts, but more intelligence applied to existing data.
Modern reliability is not built by reacting faster, but by anticipating better.
If you want to strengthen the resilience of your critical systems and prevent failures that traditional monitoring cannot see, we invite you to start with UptimeBolt through a free trial and take the next step toward truly preventive operations.
For years, monitoring has been presented as the primary line of defense to ensure the stability of critical systems. Well-configured dashboards, key metrics under control, alerts running 24/7. Everything suggests that with enough visibility, major incidents should be preventable.
The reality is different.
Every year, critical platforms in e-commerce, fintech, healthcare, and cloud experience major outages despite having “properly configured” monitoring. According to Gartner, the average cost of downtime for large enterprises can exceed $300,000 per hour, amplifying an uncomfortable paradox for CTOs and SRE leaders: how is it possible that systems with strong observability still fail in such costly ways?
The answer is not that monitoring is useless, but that traditional monitoring has structural limits when facing modern complexity. Understanding these limitations—and how to overcome them—is key to building true digital resilience.
Below, we explore the false sense of security created by “good monitoring,” analyze why critical systems continue to fail, and explain how artificial intelligence closes the gaps that traditional approaches cannot address.
When monitoring “looks” solid but still fails
In many organizations, monitoring is evaluated based on technical coverage:
If the answer is “yes,” the system is assumed to be protected.
The problem is that most critical incidents do not start with a clear signal, nor do they meet the exact conditions that trigger an alert. They begin as subtle anomalies, slow degradations, or combinations of factors that, in isolation, seem harmless.
This creates a dangerous illusion: the system “looks fine” on dashboards… until it suddenly doesn’t.
The uncomfortable reality: many incidents don’t meet alert conditions
Traditional monitoring is based on explicit rules:
But many real incidents:
Common examples
In hindsight, the data was there. The problem is that no one was looking at the right signal, at the right time.
Dependencies, microservices, and invisible failure points
Modern critical systems don’t fail only due to internal issues. They fail due to complex interactions between multiple components, many of which are outside the team’s direct control.
External dependencies
Payments, authentication, data providers, third-party services. A small degradation in any of these can:
Traditional monitoring often treats these dependencies as “black boxes.”
Microservices and distributed architectures
In a monolith, failures are usually obvious. In microservices:
The result is a system that “works,” but performs worse and worse until it collapses.
Silent failures
Workers, cron jobs, consumers, and internal processes can stop running without generating visible errors. From the outside, everything appears normal.
These are some of the most costly failures because they do not trigger traditional alerts.
Alert fatigue: when too many alerts hide real problems
This is one of the biggest operational pain points—and paradoxically, one of the least addressed.
Industry studies (including reports from Google SRE and Atlassian) indicate that between 30% and 40% of alerts in SRE teams are false positives or low-value. In some environments, this can exceed 50%.
Consequences
In this context, monitoring stops being helpful and becomes noise.
A system can “have monitoring” and still fail because important signals are lost in a sea of irrelevant alerts.
Famous postmortems: when monitoring existed but wasn’t enough
To understand the magnitude of the problem, it’s enough to review some widely documented incidents.
AWS (us-east-1, 2017 and 2021)
In multiple AWS outages, postmortems revealed:
Monitoring detected the failure when it was already happening, but did not anticipate the cascading impact.
Cloudflare (2020, 2022)
In Cloudflare incidents, the issue was not lack of data, but:
The system was monitored, but risk patterns were not evident without advanced analysis.
Facebook / Meta (2021)
Facebook’s global outage was caused by changes in BGP and DNS. Internal monitoring worked, but:
These failures were not due to lack of data, but lack of context and correlation at scale. This is the critical gap that AI is designed to close.
How AI detects degradations invisible to traditional systems
This is where artificial intelligence changes the paradigm.
AI does not replace monitoring—it extracts value from existing data, identifying patterns that humans and rule-based systems cannot detect in time.
Contextual anomaly detection
AI doesn’t just ask “Is this wrong?”, but:
This enables detection of:
Correlation of multiple signals
Instead of analyzing isolated metrics, AI correlates:
This reduces false positives and increases precision.
Anticipation instead of reaction
By recognizing patterns preceding historical incidents, AI can alert hours before a problem materializes.
This is not about guessing—it’s about recognizing risk signals.
Examples of incidents that occurred despite proper monitoring
Undetected progressive degradation
An e-commerce platform had well-configured alerts for latency and errors. However:
Result: outage during the most critical moment of the day.
Ignored intermittent error
A 0.7% error rate in an API seemed irrelevant. In reality, it was breaking checkout for certain users. Monitoring did not alert; the business suffered the impact.
Worker stopped without alerts
An internal process stopped running after a deployment. The system was “up.” The backlog grew for hours until it affected customers.
In all these cases, monitoring was present—but it wasn’t enough.
Best practices to ensure real resilience in critical systems
Overcoming these limitations requires a more mature approach.
Monitor flows, not just components
The real user experience must be the reference point.
Actively reduce alert fatigue
Incorporate anomaly detection
Static thresholds do not adapt to dynamic systems.
Anticipate, don’t just react
Modern resilience is built by acting early—not by constantly fighting fires.
How UptimeBolt helps close these gaps
UptimeBolt is designed to address precisely where traditional monitoring fails:
It doesn’t promise to eliminate all failures, but it drastically reduces their impact and frequency—transforming operations from reactive to preventive.
Conclusion: modern reliability is built on anticipation, not reaction
The biggest mistake today is not lacking monitoring—it’s believing that traditional monitoring is enough.
Critical systems fail because complexity exceeds human capacity to interpret signals in real time. The solution is not more dashboards or more alerts, but more intelligence applied to existing data.
Modern reliability is not built by reacting faster, but by anticipating better.
If you want to strengthen the resilience of your critical systems and prevent failures that traditional monitoring cannot see, we invite you to start with UptimeBolt through a free trial and take the next step toward truly preventive operations.