In most digital organizations, downtime does not occur suddenly or completely unexpectedly.
Before a critical outage, there are almost always early signals: subtle performance changes, atypical behavior in certain flows, intermittent errors, or variations that, in isolation, seem normal.
The problem is that traditional monitoring systems are not designed to detect what is “abnormal,” but only what crosses an explicit threshold. By the time the system finally “alerts,” the impact is already happening.
This is where AI-driven anomaly detection radically changes the approach: instead of waiting for something to become clearly critical, it enables early identification of deviations from normal behavior and allows action before end users feel the impact.
Keep reading to learn more.
Traditional monitoring follows a binary logic:
“everything is fine” or “something is broken.”
Operational reality is far more complex. Modern systems rarely go from healthy to full outage instantly. Most incidents follow a progressive pattern:
- Gradual increases in latency
- Low-frequency intermittent errors
- Behavioral changes in specific endpoints
- Slow resource saturation
- External dependencies starting to degrade
These signals usually do not trigger traditional alerts, yet they are exactly the signals that enable incident prevention when detected early.
Anomaly detection focuses on this intermediate space: the moment when something still works, but no longer behaves as it should.
One of the most common mistakes is using “anomaly” and “incident” as synonyms. They are not.
An anomaly is any behavior that deviates from the expected normal pattern of a system, even if it does not yet generate visible errors or directly impact users.
- Increase in
connection_reset from 0.001% to 0.05% in a specific load balancer, without the overall error rate crossing alert thresholds
- p95 latency increasing by 25% compared to historical behavior
- An endpoint showing higher variability in response times
- An end-to-end flow taking longer to complete at certain times
- A service responding correctly but with increased jitter
An incident occurs when the impact is already evident:
- Outages
- Massive errors
- Broken flows
- SLA breaches
Anomaly detection enables intervention before an anomaly escalates into an incident, reducing downtime, MTTR, and operational damage.
Fixed thresholds rely on assumptions that no longer hold in modern systems:
- System behavior is stable
- Limits are clear and predictable
- A “bad” value is always the same
In practice:
- Systems constantly change
- Traffic varies by time, region, and events
- A value acceptable today may be anomalous tomorrow
This creates two major problems:
- False positives when thresholds are too strict
- False negatives when thresholds are too loose
AI-based anomaly detection does not rely on static rules. It learns how the system actually behaves, considering:
- Historical trends
- Seasonality
- Patterns by service, flow, and time
- Normal vs. anomalous variability
Instead of asking “Did it exceed the threshold?”, AI asks:
“Is this behavior normal for this system, in this context, at this moment?”
That shift in question changes everything.
Even the most experienced teams have cognitive limits. An SRE cannot correlate hundreds of metrics, logs, and flows in real time.
AI can.
Models analyze metrics such as:
- Latency
- Errors
- Throughput
- Execution times
Identifying statistical deviations and trend changes that are not visible at a glance.
An anomaly is rarely explained by a single metric. AI correlates:
- Technical metrics
- End-to-end flow results
- API signals
- External dependencies
This enables detection of compound patterns that, through machine learning, can project a 75% incident risk within the next 30 minutes.
AI understands operational context:
- Time of day
- Day of the week
- Known events
- Historical behavior
Drastically reducing noise.
A database begins showing a gradual increase in latency for specific queries. No threshold is exceeded. Four hours later, the connection pool saturates and the system fails.
The anomaly was there from the beginning.
A payment API responds correctly but with higher variability. Error rate remains low. Minutes later, massive timeouts begin.
The anomaly preceded the incident.
Login works, but takes longer. Users begin dropping off before the system actually “fails.”
The anomaly was already impacting the business.
Early anomaly detection has direct and measurable effects:
- Reduced MTTD by detecting issues before they are visible
- Lower MTTR because diagnosis starts earlier
- Less accumulated downtime
- Lower impact on SLAs and user experience
Teams that adopt anomaly detection typically shift from:
“reacting to incidents”
to
“preventing or mitigating them early”
From an executive perspective, training an anomaly detection model involves three key steps:
- Collect sufficient historical data
- Learn the system’s normal behavior
- Tune sensitivity to maximize signal and minimize noise
It is not about “teaching what is wrong,” but about teaching what is normal.
This allows the model to detect deviations even when there are no prior examples of failure.
For more technical SRE and DevOps teams, the process includes:
- Time series models for metrics
- Statistical detection and machine learning
- Dynamic analysis windows
- Context-aware adaptive thresholds
A critical point is anomaly validation. Without validation, most tools generate too many false positives.
This is where many solutions fail.
Anomaly detection has a bad reputation for a reason: when poorly implemented, it generates noise.
UptimeBolt addresses this by combining:
- Cross-signal validation
- Historical context
- Impact on real flows
- Automatic correlation
Only when an anomaly shows potential real impact does it become an alert.
This enables significantly higher accuracy than traditional threshold-based or isolated models.
We achieve 99.8% accuracy, reducing operational noise by 80% compared to the industry average.
UptimeBolt uses anomaly detection as part of a broader intelligent monitoring strategy:
- Identifies early deviations
- Correlates metrics, flows, and dependencies
- Prioritizes real risks
- Reduces operational noise
- Anticipates incidents before they escalate
The result is a more stable, predictable operation with lower operational costs.
If you want to optimize monitoring in your operation and reduce downtime through intelligent anomaly detection, we invite you to start with UptimeBolt through a free trial.
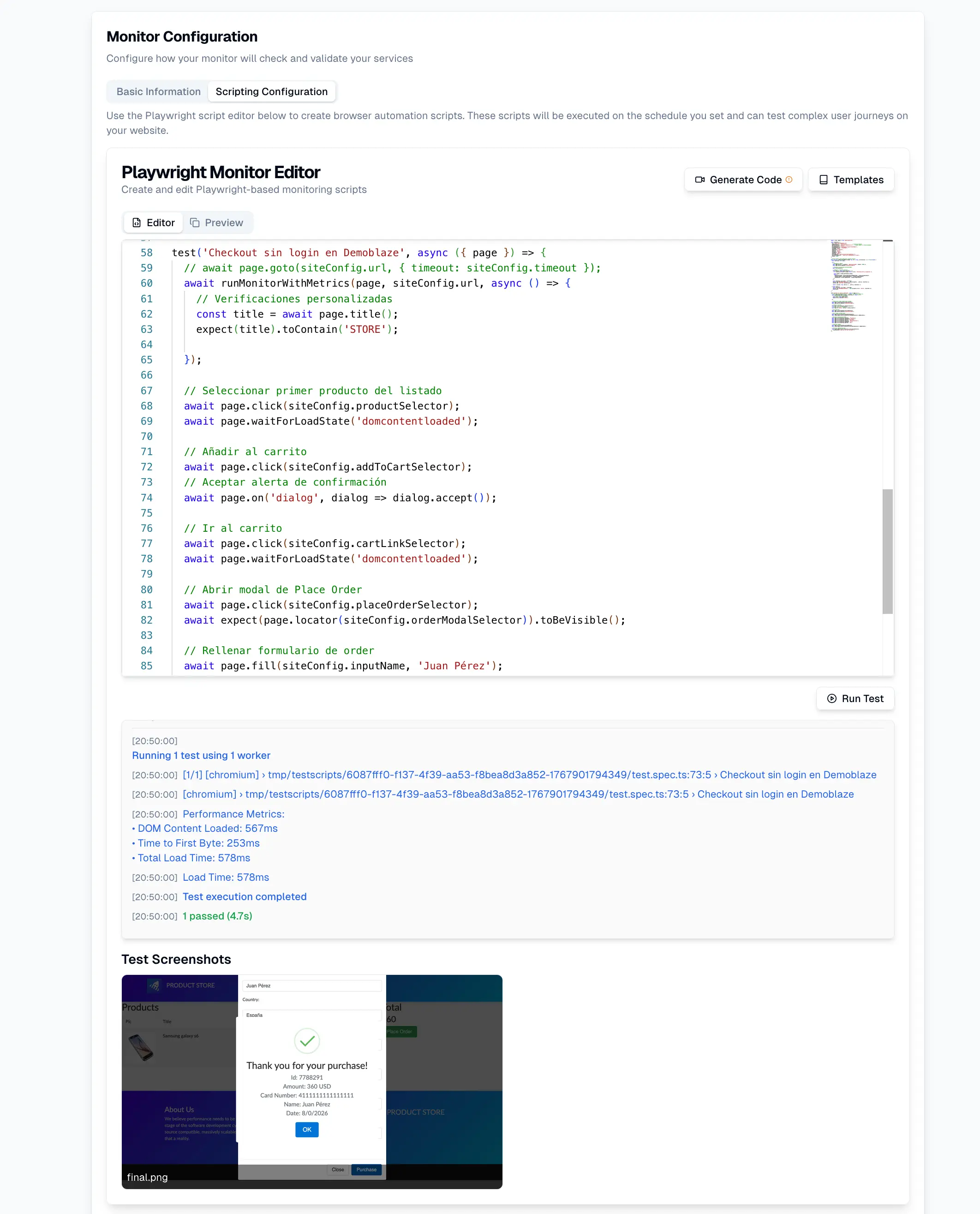
The future of reliability is not about more alerts or more dashboards. It is about understanding when a system starts behaving abnormally—even if it is still “working.”
AI-driven anomaly detection closes the gap between what the system does and what it should do, transforming monitoring from reactive to preventive.
Detecting the abnormal early is not just a technical improvement—it is an operational and competitive advantage.
Start a free trial to learn more.
In most digital organizations, downtime does not occur suddenly or completely unexpectedly.
Before a critical outage, there are almost always early signals: subtle performance changes, atypical behavior in certain flows, intermittent errors, or variations that, in isolation, seem normal.
The problem is that traditional monitoring systems are not designed to detect what is “abnormal,” but only what crosses an explicit threshold. By the time the system finally “alerts,” the impact is already happening.
This is where AI-driven anomaly detection radically changes the approach: instead of waiting for something to become clearly critical, it enables early identification of deviations from normal behavior and allows action before end users feel the impact.
Keep reading to learn more.
The importance of detecting the “abnormal” before the “critical” through observability
Traditional monitoring follows a binary logic:
Operational reality is far more complex. Modern systems rarely go from healthy to full outage instantly. Most incidents follow a progressive pattern:
These signals usually do not trigger traditional alerts, yet they are exactly the signals that enable incident prevention when detected early.
Anomaly detection focuses on this intermediate space: the moment when something still works, but no longer behaves as it should.
What is an anomaly and how it differs from an incident
One of the most common mistakes is using “anomaly” and “incident” as synonyms. They are not.
What is an anomaly
An anomaly is any behavior that deviates from the expected normal pattern of a system, even if it does not yet generate visible errors or directly impact users.
Examples
connection_resetfrom 0.001% to 0.05% in a specific load balancer, without the overall error rate crossing alert thresholdsWhat is an incident
An incident occurs when the impact is already evident:
Anomaly detection enables intervention before an anomaly escalates into an incident, reducing downtime, MTTR, and operational damage.
AI vs. fixed thresholds: the key difference in problem detection
Limitations of fixed thresholds
Fixed thresholds rely on assumptions that no longer hold in modern systems:
In practice:
This creates two major problems:
How AI overcomes these limits
AI-based anomaly detection does not rely on static rules. It learns how the system actually behaves, considering:
Instead of asking “Did it exceed the threshold?”, AI asks:
That shift in question changes everything.
How AI detects anomalies that humans would never see
Even the most experienced teams have cognitive limits. An SRE cannot correlate hundreds of metrics, logs, and flows in real time.
AI can.
Time series analysis
Models analyze metrics such as:
Identifying statistical deviations and trend changes that are not visible at a glance.
Correlation of multiple signals
An anomaly is rarely explained by a single metric. AI correlates:
This enables detection of compound patterns that, through machine learning, can project a 75% incident risk within the next 30 minutes.
Automatic context awareness
AI understands operational context:
Drastically reducing noise.
Real examples of anomalies that anticipate failures
Progressive database degradation
A database begins showing a gradual increase in latency for specific queries. No threshold is exceeded. Four hours later, the connection pool saturates and the system fails.
The anomaly was there from the beginning.
External API with erratic behavior
A payment API responds correctly but with higher variability. Error rate remains low. Minutes later, massive timeouts begin.
The anomaly preceded the incident.
Slower E2E flows without errors
Login works, but takes longer. Users begin dropping off before the system actually “fails.”
The anomaly was already impacting the business.
Direct impact on reducing downtime and MTTR
Early anomaly detection has direct and measurable effects:
Teams that adopt anomaly detection typically shift from:
How an anomaly detection model is trained (executive view)
From an executive perspective, training an anomaly detection model involves three key steps:
It is not about “teaching what is wrong,” but about teaching what is normal.
This allows the model to detect deviations even when there are no prior examples of failure.
Technical deep dive: model training and validation
For more technical SRE and DevOps teams, the process includes:
A critical point is anomaly validation. Without validation, most tools generate too many false positives.
This is where many solutions fail.
The false positives problem (and how UptimeBolt solves it)
Anomaly detection has a bad reputation for a reason: when poorly implemented, it generates noise.
UptimeBolt addresses this by combining:
Only when an anomaly shows potential real impact does it become an alert.
This enables significantly higher accuracy than traditional threshold-based or isolated models.
We achieve 99.8% accuracy, reducing operational noise by 80% compared to the industry average.
How UptimeBolt reduces downtime with predictive anomalies
UptimeBolt uses anomaly detection as part of a broader intelligent monitoring strategy:
The result is a more stable, predictable operation with lower operational costs.
If you want to optimize monitoring in your operation and reduce downtime through intelligent anomaly detection, we invite you to start with UptimeBolt through a free trial.
Conclusion: early detection is the key to operational stability
The future of reliability is not about more alerts or more dashboards. It is about understanding when a system starts behaving abnormally—even if it is still “working.”
AI-driven anomaly detection closes the gap between what the system does and what it should do, transforming monitoring from reactive to preventive.
Detecting the abnormal early is not just a technical improvement—it is an operational and competitive advantage.
Start a free trial to learn more.