For DevOps and SRE teams, the simple uptime metric is now an insufficient relic. In the era of microservices and observability, 99.9% availability is no longer a guarantee of reliability.
In modern architectures—distributed, API-driven, built on microservices and multiple dependencies—a system can be technically available and still deliver a poor experience. High latency, intermittent errors, or incomplete flows can directly impact the business without causing an obvious outage.
Digital reliability is no longer measured by uptime alone, but by the system’s ability to operate correctly under the principles of Site Reliability Engineering (SRE):
- Maintain low latency (Latency)
- Properly handle traffic (Traffic)
- Minimize and control errors (Errors)
- Detect issues early
- Recover quickly
- Meet user expectations
In this article, we present the 7 essential metrics that truly matter, with a clear structure for each:
- What it measures
- How to calculate it
- Real benchmarks
- How to improve it
Real availability measures the percentage of successful requests from the user’s perspective—not just whether the system responds.
Availability (%) = (Successful requests / Total requests) × 100
- 99% → acceptable (non-critical services)
- 99.9% → SaaS standard
- 99.99% → critical systems (fintech, payments)
A system can return 200 OK but with incorrect or incomplete data.
For example, a Kubernetes liveness probe may return 200, while a retry loop in a downstream service or a slow datastore connection is causing failures in 1% of transactions without triggering a critical alert.
- Monitor SLIs based on real success
- Validate functional responses, not just technical ones
- Implement E2E monitoring
Measures how long the system takes to respond to a request.
Latency SLI = Percentile (pXX) of response time (e.g., p95 or p99 over the last 5 minutes).
Using averages is dangerous for reliability.
- <300 ms → excellent
- 300–800 ms → acceptable
- 1 s → abandonment risk
Specifically:
Averages hide problems. The real issues live in high percentiles.
- Optimize queries and API calls
- Use caching strategically
- Monitor p95 and p99, not just averages
Percentage of requests that fail.
Error rate (%) = (Errors / Total requests) × 100
- <0.1% → excellent
- 0.1% – 1% → acceptable
-
1% → critical
Not all errors are visible (silent errors).
Example:
- API returns 200, but the body is empty
- Classify technical vs functional errors
- Monitor complete flows
- Detect anomalies early
Use Machine Learning models to detect subtle changes in error patterns (e.g., a 0.05% increase in 5xx errors or a drop in expected volume), even if they don’t cross static thresholds. This is predictive monitoring.
Average time the system takes to recover after an incident.
MTTR = Total recovery time / Number of incidents
- <30 min → excellent
- 30 min – 2 h → acceptable
-
2 h → high impact
High MTTR is often the result of slow diagnosis.
- Automate responses
- Maintain clear runbooks
- Improve visibility and event correlation
Implement automated correlation solutions (AIOps) to group noisy alerts and reduce investigation time (Time To Triage), directly lowering MTTR.
Average time it takes for the team to detect a problem.
MTTD = Total detection time / Number of incidents
- <5 min → excellent
- 5–15 min → acceptable
-
15 min → operational risk
Many failures are detected by users instead of monitoring systems.
- Implement E2E monitoring
- Use anomaly detection
- Reduce reliance on static thresholds
AI-based anomaly detection and out-of-the-box monitoring (without manual thresholds) is the only way to bring MTTD below 5 minutes. This capability can be measured internally using a bonus metric: prediction accuracy.
Measures the percentage of times a complete flow (login, checkout, payment) executes successfully.
Flow success rate (%) = (Successful flows / Total flows) × 100
- 99.5% → excellent
- 98–99.5% → moderate risk
- <98% → direct business impact
This metric is the closest to real user experience.
Example:
- API OK
- Database OK
- But checkout fails
Only E2E monitoring detects it.
- Implement continuous end-to-end monitoring
- Validate intermediate steps
- Detect partial degradation
This metric directly connects to E2E monitoring, which is critical for understanding real system reliability.
The amount of failure allowed within a given period based on the SLO.
Error budget = 100% - SLO
- SLO: 99.9%
- Error budget: 0.1%
Depends on the business:
- SaaS: 99.9%
- Fintech: 99.99%
- Critical infrastructure: 99.999%
It is defined but not used for decision-making.
- Use it to decide deployments
- Balance stability vs velocity
- Integrate it into planning
Measures how accurate AI-generated incident predictions are.
Prediction accuracy (%) = (Correct predictions / Total predictions) × 100
- 85% → high confidence
- 70–85% → useful with supervision
- <70% → high noise
Modern organizations don’t just detect problems—they anticipate them.
- Train models with historical data
- Reduce false positives
- Correlate multiple signals
One of the biggest challenges is not defining metrics—but operationalizing them.
UptimeBolt acts as a layer that connects:
- Traditional monitoring
- E2E experience
- AI-based prediction
- Measuring real SLIs (not just uptime)
- Analyzing latency in percentiles
- Detecting anomalies before incidents
- Validating complete flows
- Reducing MTTD and MTTR
- Anticipating issues with predictive models
It significantly reduces MTTD by implementing predictive anomaly detection (based on the bonus metric).
UptimeBolt doesn’t aim to replace observability—it makes it more actionable and focused on real reliability.
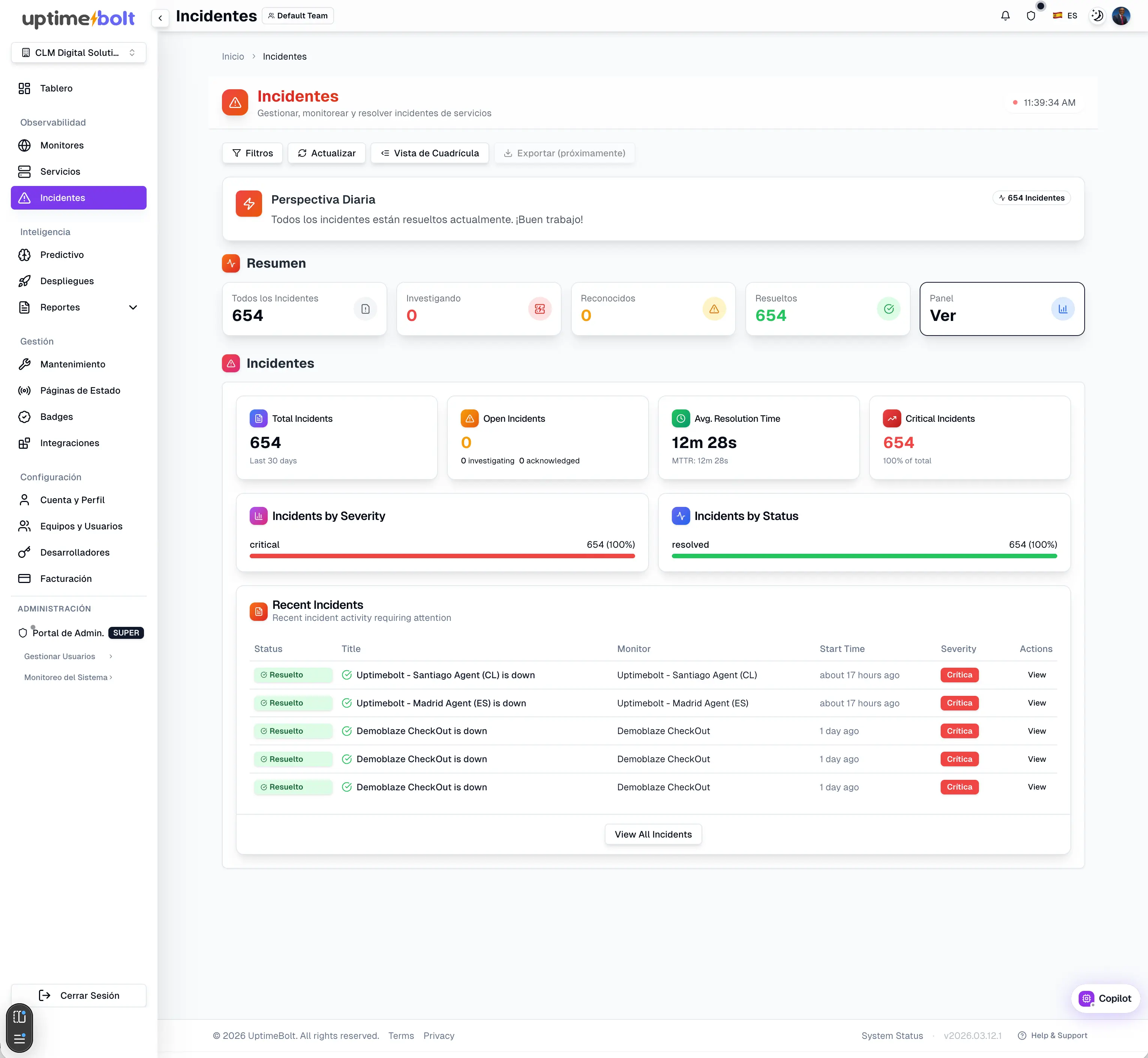
Digital reliability is not a state—it is a continuous process.
It is not achieved with more dashboards, but with:
- The right metrics
- Proper interpretation
- Continuous action
The most mature organizations are not the ones that monitor the most—but the ones that understand the best.
And it all starts by measuring what truly matters.
If you want to start measuring and improving your digital reliability with actionable metrics and predictive monitoring, we invite you to try UptimeBolt for free.
For DevOps and SRE teams, the simple uptime metric is now an insufficient relic. In the era of microservices and observability, 99.9% availability is no longer a guarantee of reliability.
In modern architectures—distributed, API-driven, built on microservices and multiple dependencies—a system can be technically available and still deliver a poor experience. High latency, intermittent errors, or incomplete flows can directly impact the business without causing an obvious outage.
Digital reliability is no longer measured by uptime alone, but by the system’s ability to operate correctly under the principles of Site Reliability Engineering (SRE):
In this article, we present the 7 essential metrics that truly matter, with a clear structure for each:
Metric 1: Real Availability (SLI)
Definition
Real availability measures the percentage of successful requests from the user’s perspective—not just whether the system responds.
Formula
Availability (%) = (Successful requests / Total requests) × 100
Industry benchmark
Common problem
A system can return 200 OK but with incorrect or incomplete data.
For example, a Kubernetes liveness probe may return 200, while a retry loop in a downstream service or a slow datastore connection is causing failures in 1% of transactions without triggering a critical alert.
How to improve
Metric 2: Latency and Response Time
Definition
Measures how long the system takes to respond to a request.
Formula
Latency SLI = Percentile (pXX) of response time (e.g., p95 or p99 over the last 5 minutes).
Using averages is dangerous for reliability.
Industry benchmark
Specifically:
Common problem
Averages hide problems. The real issues live in high percentiles.
How to improve
Metric 3: Error Rate
Definition
Percentage of requests that fail.
Formula
Error rate (%) = (Errors / Total requests) × 100
Industry benchmark
Common problem
Not all errors are visible (silent errors).
Example:
How to improve
Use Machine Learning models to detect subtle changes in error patterns (e.g., a 0.05% increase in 5xx errors or a drop in expected volume), even if they don’t cross static thresholds. This is predictive monitoring.
Metric 4: MTTR (Mean Time To Recovery)
Definition
Average time the system takes to recover after an incident.
Formula
MTTR = Total recovery time / Number of incidents
Industry benchmark
Common problem
High MTTR is often the result of slow diagnosis.
How to improve
Implement automated correlation solutions (AIOps) to group noisy alerts and reduce investigation time (Time To Triage), directly lowering MTTR.
Metric 5: MTTD (Mean Time To Detect)
Definition
Average time it takes for the team to detect a problem.
Formula
MTTD = Total detection time / Number of incidents
Industry benchmark
Common problem
Many failures are detected by users instead of monitoring systems.
How to improve
AI-based anomaly detection and out-of-the-box monitoring (without manual thresholds) is the only way to bring MTTD below 5 minutes. This capability can be measured internally using a bonus metric: prediction accuracy.
Metric 6: Critical Flow Success (E2E)
Definition
Measures the percentage of times a complete flow (login, checkout, payment) executes successfully.
Formula
Flow success rate (%) = (Successful flows / Total flows) × 100
Industry benchmark
Key problem
This metric is the closest to real user experience.
Example:
Only E2E monitoring detects it.
How to improve
This metric directly connects to E2E monitoring, which is critical for understanding real system reliability.
Metric 7: Error Budget
Error Budget as a governance tool
The amount of failure allowed within a given period based on the SLO.
Formula
Error budget = 100% - SLO
Example
Industry benchmark
Depends on the business:
Common problem
It is defined but not used for decision-making.
How to improve
Bonus Metric: Prediction Accuracy (AI-first)
Definition
Measures how accurate AI-generated incident predictions are.
Formula
Prediction accuracy (%) = (Correct predictions / Total predictions) × 100
Indicative benchmark
Why it matters
Modern organizations don’t just detect problems—they anticipate them.
How to improve
How UptimeBolt enables unified monitoring of these metrics
One of the biggest challenges is not defining metrics—but operationalizing them.
UptimeBolt acts as a layer that connects:
It enables
It significantly reduces MTTD by implementing predictive anomaly detection (based on the bonus metric).
UptimeBolt doesn’t aim to replace observability—it makes it more actionable and focused on real reliability.
Conclusion: reliability is built by measuring and learning
Digital reliability is not a state—it is a continuous process.
It is not achieved with more dashboards, but with:
The most mature organizations are not the ones that monitor the most—but the ones that understand the best.
And it all starts by measuring what truly matters.
If you want to start measuring and improving your digital reliability with actionable metrics and predictive monitoring, we invite you to try UptimeBolt for free.