Microservices reliability is one of the biggest challenges in modern e-commerce platforms. Microservices make it possible to scale quickly, deploy frequently, and evolve products without heavy dependencies—but they also introduce a new kind of fragility: distributed failures, silent degradations, and cascading effects that directly impact revenue and customer experience.
In digital retail, where traffic can spike in seconds and every transaction matters, a poorly prepared distributed architecture can collapse at the most critical moments. During traffic peaks, an interruption of just 15 minutes in checkout can translate into hundreds of thousands of dollars in lost sales, even if the rest of the platform remains “online.”
This article presents a practical, actionable framework to improve microservices reliability in e-commerce by combining engineering best practices, advanced monitoring, synthetic testing, and AI-driven incident prediction—with one clear goal: prevent technical failures from turning into real business losses.
Microservices offer clear advantages: independent scalability, faster deployments, and autonomous teams. However, in e-commerce these benefits come with specific risks that are not always obvious in distributed environments.
In a typical platform, a purchase flow involves dozens of interconnected services: catalog, pricing, promotions, cart, inventory, payments, shipping, fraud detection, notifications, and external services. These services often communicate synchronously at critical points in the user journey.
For example, a degradation in the Promotions Service API can increase response times in the Cart Service, which in turn blocks execution threads in the Inventory Service while waiting for the final price calculation. Under load, this blocking can lead to thread or connection pool exhaustion, creating cascading latencies that eventually cause the Checkout Service to hit its timeout, even though no service is fully down.
These failures rarely appear as total outages. Instead, they show up as progressive degradations, intermittent timeouts, or partial errors that directly impact conversion rates and customer experience.
That’s why microservices reliability in e-commerce does not depend on each service working in isolation, but on the entire system working correctly together—under real load, with real internal and external dependencies, and in non-ideal conditions.
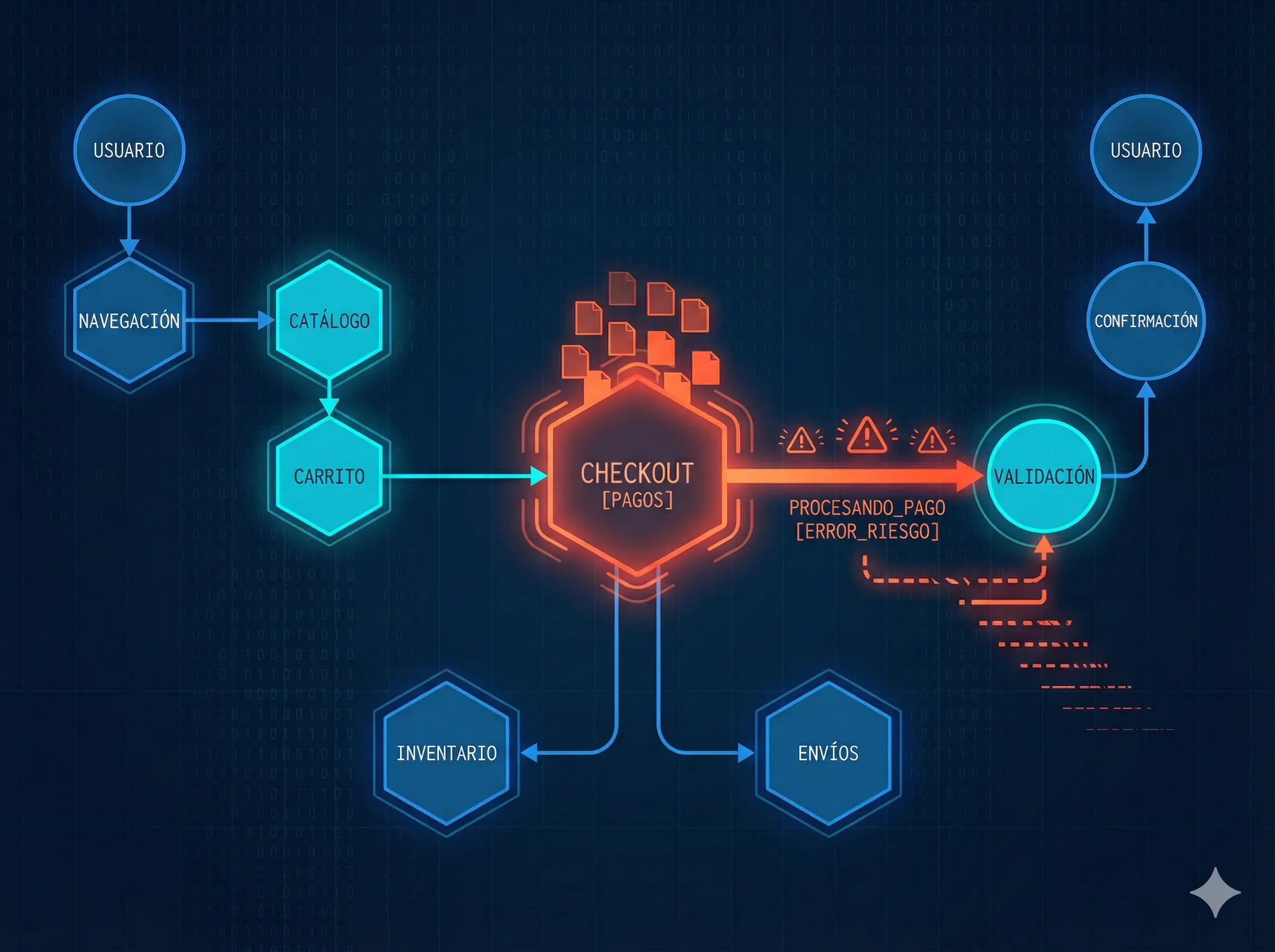
Before defining a framework, it’s essential to understand where microservices typically fail in digital retail.
-
Accumulated latency
Each service call adds latency. A flow may technically work but be too slow for users.
-
Hidden critical dependencies
Seemingly secondary services can become bottlenecks during traffic peaks.
-
Poorly configured timeouts
Timeouts that are too high block resources; too low create unnecessary errors.
-
Silent degradation
A service responds, but incorrectly or intermittently, without triggering clear alerts.
-
Cascading failures
Slowness or failure in one service propagates to others, amplifying the impact.
Improving microservices reliability requires addressing these points systematically.
Below is a step-by-step framework designed specifically for e-commerce platforms.
Not all microservices have the same impact. The first step is identifying which flows generate real business value.
In e-commerce, the most common are:
- Login and authentication
- Navigation and search
- Shopping cart
- Checkout
- Payment and confirmation
Microservices reliability must be evaluated from these business journeys, not from individual services.
Once critical flows are defined, map which services participate and how they interact.
This mapping helps to:
- Identify strong dependencies
- Detect single points of failure
- Prioritize critical services
- Understand cascading impacts
Without this map, microservices reliability is managed blindly.
High availability does not guarantee reliability. In microservices, resilience is essential.
Best practices include:
- Defining an error budget and latency SLOs
- Circuit breakers to prevent cascades
- Controlled retries
- Fallbacks when a service fails
- Acceptable functional degradation
For example, showing products without recommendations is preferable to breaking the entire flow.
Generic timeouts are a common cause of e-commerce failures.
Each service should have:
- Timeouts aligned with user experience expectations
- Clear concurrency limits, using rate limiters at the API Gateway level and bulkhead patterns to isolate secondary services (e.g., Recommendations) and protect critical ones (Checkout)
- Saturation protection
Microservices reliability improves when limits are designed around the full user journey.
Monitoring individual microservices does not guarantee that the system works as a whole.
Synthetic monitoring validates complete journeys by simulating users, such as:
- Login → search → cart → checkout → payment
It’s important to clarify that this does not measure real user behavior (that’s RUM), but validates real system behavior through controlled simulations.
This approach detects:
- Broken flows even when services are “up”
- Logical errors between services
- Progressive degradations
For microservices reliability in e-commerce, this type of validation is essential.
Microservices primarily communicate via APIs. When APIs fail, the entire system suffers.
Monitoring should cover:
- Inter-service latency
- Intermittent errors
- Timeouts and incomplete responses
- API contract changes
Monitoring APIs in isolation is not enough—they must be correlated within business flows.
In e-commerce, conversions often drop before the system goes down.
Early signs of degradation include:
-
Gradual increases in response times
Monitoring should focus on P99 latency of critical services (e.g., Payment and Checkout) and alert when it exceeds a degradation threshold (e.g., +20% in 5 minutes).
-
Sporadic checkout errors
-
Payments taking longer than usual
-
Invisible retries for users
Early anomaly detection allows teams to act before these degradations affect business metrics.
The complexity of microservices reliability makes manual analysis insufficient.
AI enables teams to:
- Detect non-obvious anomalies
(e.g., correlating a spike in 503 errors in Inventory with a drop in Catalog database throughput and an increase in P50 latency in Authentication)
- Correlate events across services
- Identify pre-incident patterns
- Prioritize real business risks
In e-commerce, where traffic peaks are predictable but intense, incident prediction makes the difference between stability and outage.
An effective framework doesn’t stop at production. Microservices reliability must be validated before and after every release.
This includes:
- Synthetic tests in staging environments
- Post-deploy validations in production
- Continuous monitoring of critical journeys
This prevents small changes from breaking entire journeys.
Before a critical event, a team should be able to answer “yes” to the following:
- Have we identified critical journeys?
- Do we understand microservice dependencies?
- Are circuit breakers and fallbacks in place?
- Are timeouts well defined?
- Do we continuously simulate full journeys?
- Do we monitor internal APIs with context?
- Do we detect degradation before outages occur?
- Do we use data and AI to anticipate incidents?
If any answer is “no,” microservices reliability is at risk.
UptimeBolt is designed to address microservices reliability from an end-to-end, business-oriented perspective.
The platform enables:
- Synthetic monitoring of complete e-commerce journeys
- API monitoring between microservices
- AI-driven anomaly detection
- Incident prediction ahead of traffic peaks
- Automatic event correlation
- Intelligent alerts with clear context
This approach allows teams to anticipate failures, protect conversions, and operate with confidence even under extreme load.
If you want to strengthen microservices reliability in your e-commerce platform and prevent one service from breaking the entire sales flow, sign up and get a free trial.
In e-commerce, technology is not just a support function—it is the business. A poorly prepared microservices architecture may scale fast, but it can also fail fast when it matters most.
Applying a practical framework to improve microservices reliability helps detect risks before they impact conversions, anticipate incidents, and deliver stable experiences even under extreme conditions.
In digital retail, success isn’t defined by who ships faster—it’s defined by who stays reliable when everyone shows up at the same time.
Microservices reliability is one of the biggest challenges in modern e-commerce platforms. Microservices make it possible to scale quickly, deploy frequently, and evolve products without heavy dependencies—but they also introduce a new kind of fragility: distributed failures, silent degradations, and cascading effects that directly impact revenue and customer experience.
In digital retail, where traffic can spike in seconds and every transaction matters, a poorly prepared distributed architecture can collapse at the most critical moments. During traffic peaks, an interruption of just 15 minutes in checkout can translate into hundreds of thousands of dollars in lost sales, even if the rest of the platform remains “online.”
This article presents a practical, actionable framework to improve microservices reliability in e-commerce by combining engineering best practices, advanced monitoring, synthetic testing, and AI-driven incident prediction—with one clear goal: prevent technical failures from turning into real business losses.
Why microservices are powerful—but fragile—in e-commerce
Microservices offer clear advantages: independent scalability, faster deployments, and autonomous teams. However, in e-commerce these benefits come with specific risks that are not always obvious in distributed environments.
In a typical platform, a purchase flow involves dozens of interconnected services: catalog, pricing, promotions, cart, inventory, payments, shipping, fraud detection, notifications, and external services. These services often communicate synchronously at critical points in the user journey.
For example, a degradation in the Promotions Service API can increase response times in the Cart Service, which in turn blocks execution threads in the Inventory Service while waiting for the final price calculation. Under load, this blocking can lead to thread or connection pool exhaustion, creating cascading latencies that eventually cause the Checkout Service to hit its timeout, even though no service is fully down.
These failures rarely appear as total outages. Instead, they show up as progressive degradations, intermittent timeouts, or partial errors that directly impact conversion rates and customer experience.
That’s why microservices reliability in e-commerce does not depend on each service working in isolation, but on the entire system working correctly together—under real load, with real internal and external dependencies, and in non-ideal conditions.
Common failure points in distributed architectures
Before defining a framework, it’s essential to understand where microservices typically fail in digital retail.
Accumulated latency
Each service call adds latency. A flow may technically work but be too slow for users.
Hidden critical dependencies
Seemingly secondary services can become bottlenecks during traffic peaks.
Poorly configured timeouts
Timeouts that are too high block resources; too low create unnecessary errors.
Silent degradation
A service responds, but incorrectly or intermittently, without triggering clear alerts.
Cascading failures
Slowness or failure in one service propagates to others, amplifying the impact.
Improving microservices reliability requires addressing these points systematically.
A practical framework to improve microservices reliability
Below is a step-by-step framework designed specifically for e-commerce platforms.
Step 1: Identify critical business journeys
Not all microservices have the same impact. The first step is identifying which flows generate real business value.
In e-commerce, the most common are:
Microservices reliability must be evaluated from these business journeys, not from individual services.
Step 2: Map dependencies between microservices
Once critical flows are defined, map which services participate and how they interact.
This mapping helps to:
Without this map, microservices reliability is managed blindly.
Step 3: Design for resilience, not just availability
High availability does not guarantee reliability. In microservices, resilience is essential.
Best practices include:
For example, showing products without recommendations is preferable to breaking the entire flow.
Step 4: Configure timeouts and limits aligned with the business
Generic timeouts are a common cause of e-commerce failures.
Each service should have:
Microservices reliability improves when limits are designed around the full user journey.
Synthetic monitoring to validate critical journeys
Monitoring individual microservices does not guarantee that the system works as a whole.
Synthetic monitoring validates complete journeys by simulating users, such as:
It’s important to clarify that this does not measure real user behavior (that’s RUM), but validates real system behavior through controlled simulations.
This approach detects:
For microservices reliability in e-commerce, this type of validation is essential.
API monitoring between microservices
Microservices primarily communicate via APIs. When APIs fail, the entire system suffers.
Monitoring should cover:
Monitoring APIs in isolation is not enough—they must be correlated within business flows.
Detecting degradation before it impacts conversions
In e-commerce, conversions often drop before the system goes down.
Early signs of degradation include:
Gradual increases in response times
Monitoring should focus on P99 latency of critical services (e.g., Payment and Checkout) and alert when it exceeds a degradation threshold (e.g., +20% in 5 minutes).
Sporadic checkout errors
Payments taking longer than usual
Invisible retries for users
Early anomaly detection allows teams to act before these degradations affect business metrics.
AI for incident prediction in e-commerce
The complexity of microservices reliability makes manual analysis insufficient.
AI enables teams to:
(e.g., correlating a spike in 503 errors in Inventory with a drop in Catalog database throughput and an increase in P50 latency in Authentication)
In e-commerce, where traffic peaks are predictable but intense, incident prediction makes the difference between stability and outage.
Integrating reliability into the deployment lifecycle
An effective framework doesn’t stop at production. Microservices reliability must be validated before and after every release.
This includes:
This prevents small changes from breaking entire journeys.
Final distributed reliability checklist for e-commerce
Before a critical event, a team should be able to answer “yes” to the following:
If any answer is “no,” microservices reliability is at risk.
How UptimeBolt improves microservices reliability
UptimeBolt is designed to address microservices reliability from an end-to-end, business-oriented perspective.
The platform enables:
This approach allows teams to anticipate failures, protect conversions, and operate with confidence even under extreme load.
If you want to strengthen microservices reliability in your e-commerce platform and prevent one service from breaking the entire sales flow, sign up and get a free trial.
Conclusion: reliability is the real secret to success in digital retail
In e-commerce, technology is not just a support function—it is the business. A poorly prepared microservices architecture may scale fast, but it can also fail fast when it matters most.
Applying a practical framework to improve microservices reliability helps detect risks before they impact conversions, anticipate incidents, and deliver stable experiences even under extreme conditions.
In digital retail, success isn’t defined by who ships faster—it’s defined by who stays reliable when everyone shows up at the same time.